
What is Unstract?
Unstract 是一个开源、无代码平台,专为利用大型语言模型(LLMs)从复杂的非结构化文档中高精度提取数据而设计。它有效消除了通常与准备和处理高度多变文档相关的手动复杂性,使那些追求精确性和可扩展性的前瞻性工程师和组织,能够为其关键的非结构化数据资产部署可靠、可审计的API和ETL管道。
核心功能
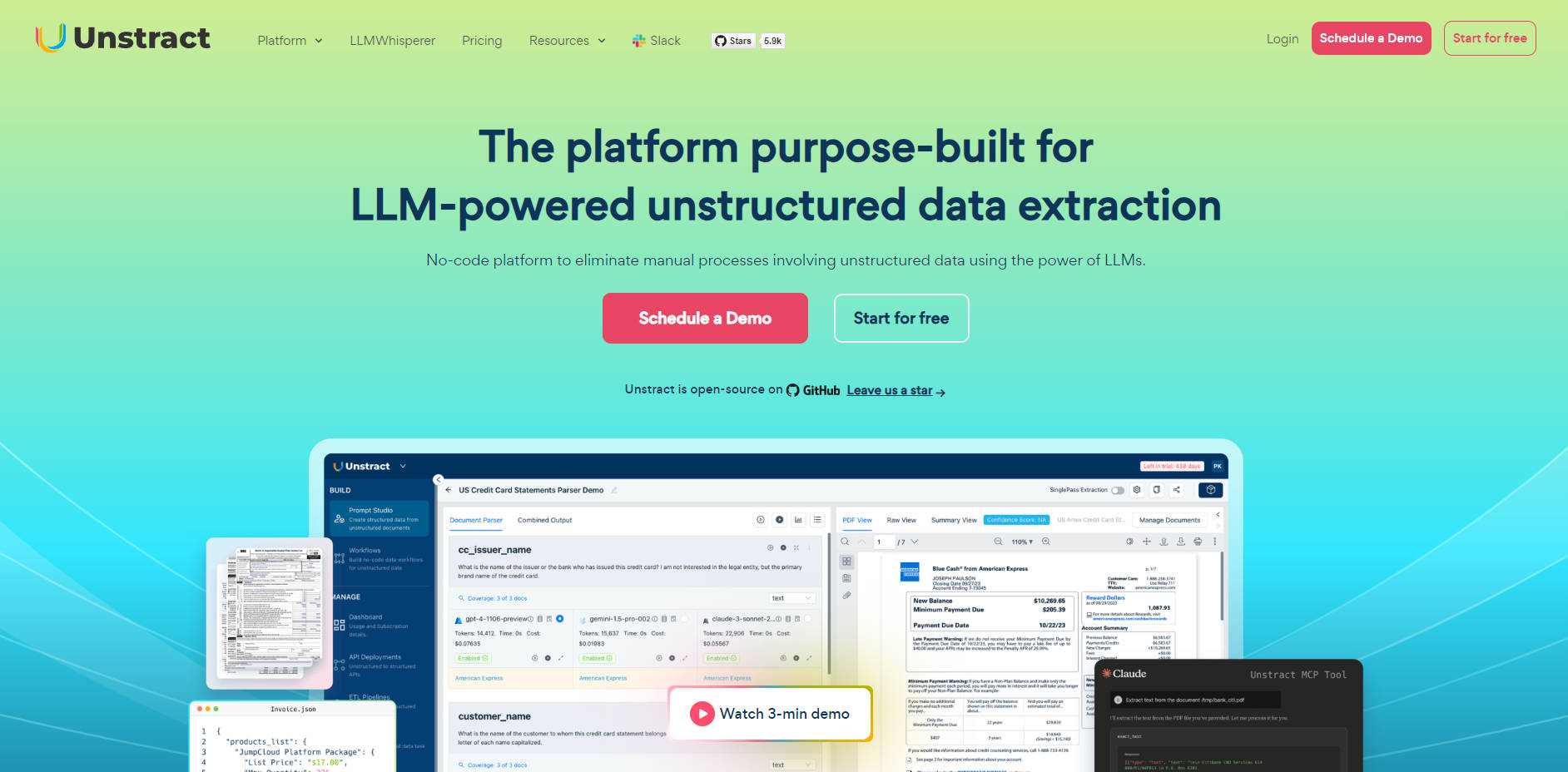
Unstract 提供了必要的架构组件,能够将任意文档输入转化为整洁、可靠且可供系统使用的JSON或CSV数据。
🧠 LLMChallenge:双LLM共识引擎
这种独特的机制通过采用两个独立的LLM(一个提取器和一个挑战者)来验证结果,从而提升了数据信任度。系统遵循“空值优于错误值”的原则,在处理初期捕获并摒弃“幻觉”(hallucinations)。这确保了只返回准确、经过验证的值,显著提升了自动化工作流的完整性。
🛠️ Prompt Studio:专用工程环境
Prompt Studio 提供了一个专用的画布,供提示工程师快速构建、测试和优化提取逻辑。您可以从少量有代表性的文档样本中快速构建通用提示,强制执行一致的架构(从简单文本到嵌套JSON),并利用内置的版本控制功能,便于测试和回滚。这一功能为复杂、高保真部署提供了必要的控制。
🖼️ LLMWhisperer:布局保留型文档准备
处理实际文档——无论是扫描的PDF、多列表格,还是智能手机拍摄的图片——都需要智能预处理。LLMWhisperer 作为一项辅助服务,生成高度优化的输出,其格式是LLM最容易理解的。其独特的布局保留模式使LLM能够准确解释多列布局、表格、表单,甚至可靠地检测手写文本、复选框和单选按钮。
⚡ SinglePass 和 Summarized Extraction:实现成本效益
通过优化token(令牌)使用,实现显著的成本节约和速度提升。SinglePass Extraction 将所有字段提取提示整合为针对整个文档的一次性大型执行。另外,Summarized Extraction 自动构建输入文档的极度精简版本,然后针对这个优化版本运行提示,以处理更少的文本。这些策略可以将token使用量减少高达7倍,以最低的成本提供最大的提取效率。
🧑💻 人工辅助(HITL)验证
对于需要绝对确定性的生产级数据,HITL 功能弥合了自动化提取与无暇数据之间的鸿沟。您可以根据置信度分数或字段值配置智能路由规则,确保您的团队只审查边缘案例。用户可以并排查看提取的数据和源文档,并利用源文档高亮显示功能进行即时验证、纠正错误,并维护一个完全可审计的追踪记录。
应用场景
Unstract 旨在处理传统智能文档处理(IDP)和机器人流程自动化(RPA)系统难以应对的复杂性和规模。
高变异性文档处理: 轻松自动化涉及高度多变文档的任务,例如处理来自200家不同银行的银行对账单,或处理在50个不同州具有变体的相同表格。Unstract 确保无论文档如何变化,都能输出一致的结构化JSON数据。
自动化复杂合同分析: 工程师可以利用 LLMWhisperer 和 SinglePass extraction 功能,从发票中高效提取特定、详细的行项目,或从冗长的法律合同中精准定位关键条款,将以往仅限人工审阅的任务转变为可靠的自动化工作流程。
数据生态系统集成: 结构化存储在云文件存储中的非结构化文档,并使用预构建的ETL管道自动将其推送到数据仓库和数据库。另外,通过调用 Unstract APIs,可以将提取功能直接嵌入到现有应用程序中,从而在数据摄取时实现无缝的文档结构化。
独特优势
Unstract 旨在超越传统文档处理解决方案的局限性,专注于速度、准确性和工程灵活性。
通过共识建立信任: LLMChallenge(双LLM共识引擎)是核心差异化优势,它能够捕获并消除“幻觉”,而传统系统则仅依赖于置信度分数或单一模型输出。这保证了生产级数据的完整性。
效率最大化,成本最小化: 通过 SinglePass 和 Summarized Extraction 等专业优化技术,可将token使用量减少高达7倍。这显著降低了运营成本,同时提升了处理速度。
开源灵活性: 作为一个开源、无代码平台,Unstract 为组织提供了完全的透明度和控制权。它支持多LLM环境(OpenAI、Claude、Azure GPT、Vertex),并允许您根据具体的合规性和性能需求,选择最佳的Vector DB、Embedding Model和文本提取服务。
超越IDP和RPA: 通过利用尖端的LLM能力,Unstract 解决了非结构化数据的核心挑战——特别是高变异性和不一致的格式——超越了传统智能文档处理(IDP)和机器人流程自动化(RPA)基于规则或依赖模板的局限性。
总结
Unstract 提供了必要的工具和生产架构,能将复杂、高变异性的文档转化为结构化、可信赖且可供部署的数据。专为精确性和规模化而构建,它使工程师能够实现更好的自动化扩展,并显著减少人工监督。
探索 Unstract 如何帮助您实现最大的提取效率,并部署您的下一个数据管道。立即开始14天免费试用。
More information on Unstract
Launched
2023-08
Pricing Model
Freemium
Starting Price
Global Rank
451302
Follow
Month Visit
74.5K
Tech used
WordPress,Elementor,Bootstrap,animate.css,Clipboard.js,Font Awesome,Google Analytics,Google Font API,Google Tag Manager,HubSpot Analytics,Linkedin Insight Tag,Prism,Slick,Swiper Slider,jQuery,jQuery Migrate
Top 5 Countries
14.99%
8.71%
8.58%
7.61%
6.02%
United States
Nigeria
India
Brazil
Germany
Traffic Sources
15.81%
0.86%
0.11%
9.05%
40.45%
33.65%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
Unstract was manually vetted by our editorial team and was first featured on 2024-06-19.
Related Searches
Unstract 替代方案
更多 替代方案-

-

-

-

Parse Extract:专为LLM管道打造的高级数据提取与OCR功能。将复杂的文档和网络数据转化为规整、可直接用于LLM的文本。成本效益高,安全可靠。
-
