
What is Unstract?
Unstract 是一個開源、無程式碼的平台,專為運用大型語言模型(LLM)從複雜的非結構化文件中實現高精準度資料擷取而打造。它有效消除了準備和處理高度變異文件時常見的人工複雜性,使具前瞻思維的工程師和對精準度與規模有要求的組織,能夠為其關鍵的非結構化資料資產部署可靠、可稽核的 API 和 ETL 管線。
主要功能
Unstract 提供必要的架構元件,將任意文件輸入轉化為清晰、可靠且可供系統使用的 JSON 或 CSV 資料。
🧠 LLMChallenge:雙LLM共識引擎
這種獨特的機制透過運用兩個獨立的LLM——一個作為提取器,一個作為挑戰者——來驗證結果,從而提升資料信任度。系統基於「 空值勝於錯誤 」的原則運作,在處理過程初期捕捉並排除不實資訊。這確保只傳回準確、經過驗證的值,大幅提升自動化工作流程的完整性。
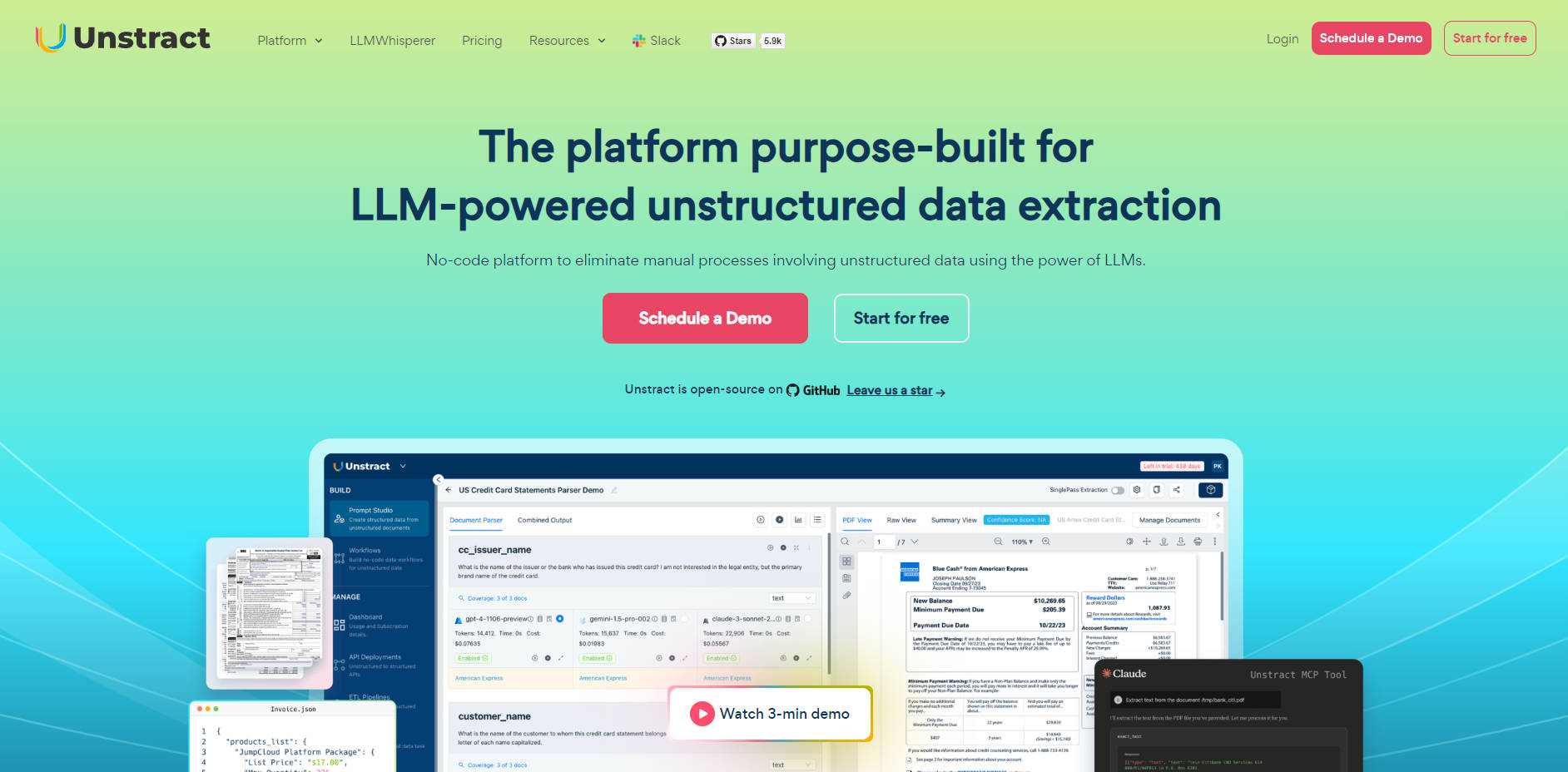
🛠️ Prompt Studio:專屬工程環境
Prompt Studio 提供一個專用的畫布,供提示工程師快速建構、測試和精進提取邏輯。您可以從少量具代表性的文件樣本中快速建立通用提示, 強制執行一致的結構描述 (從簡單文字到巢狀 JSON),並利用內建的 版本控制 功能,輕鬆進行測試和回溯。此功能提供所需的控制,以應對複雜、高可靠度的部署。
🖼️ LLMWhisperer:版面配置保留文件準備
處理真實世界的文件——例如掃描的PDF、多欄位表單或智慧型手機拍攝的影像——需要智慧化的預處理。LLMWhisperer 作為一個輔助服務,產生高度最佳化的輸出,以LLM最能理解的格式呈現。其 獨特的版面配置保留模式 使LLM能夠準確解讀多欄位版面、表單、表格,甚至可靠地偵測手寫文字、核取方塊和選項按鈕。
⚡ SinglePass 與 Summarized Extraction:提升成本效益
透過優化Token使用量,大幅節省成本並提升速度。 SinglePass Extraction 將所有欄位提取提示整合為對完整文件的一次性、大型執行。另一方面, Summarized Extraction 會自動建構一個極度精簡的輸入文件版本,並對此最佳化版本執行提示以處理較少量的文字。這些策略可將Token使用量減少高達 7倍,以最低成本提供最大化提取。
🧑💻 人機協作(HITL)驗證
對於需要絕對確定性的生產級資料,HITL功能彌合了自動提取與無瑕疵資料之間的差距。您可以根據信心分數或欄位值 配置智慧路由規則,確保您的團隊僅審查邊緣案例。使用者可以並排檢視提取的資料和來源文件,運用 來源文件高亮顯示 功能,進行即時驗證、編輯錯誤,並維護完整可稽核的軌跡。
使用案例
Unstract 旨在處理傳統智慧文件處理(IDP)和機器人流程自動化(RPA)系統難以應對的複雜性和規模。
高變異文件處理: 輕鬆自動化涉及高度變異文件的任務,例如處理 來自200家不同銀行的銀行對帳單 或處理在50個不同州有不同變體的相同表單。無論文件變體如何,Unstract 都能確保一致、結構化的JSON輸出。
自動化複雜合約分析: 工程師可以利用 LLMWhisperer 和 SinglePass extraction,從發票中高效提取特定、詳細的項目,或精確定位長篇法律合約中的關鍵條款,將過去僅限人工審核的任務轉化為可靠的自動化工作流程。
資料生態系統整合: 結構化儲存在雲端檔案儲存中的非結構化文件,並使用預建的 ETL 管線自動將其推送到資料倉儲和資料庫。或者,透過呼叫 Unstract API 將提取功能直接嵌入到現有應用程式中,實現在資料攝取時的無縫文件結構化。
獨特優勢
Unstract 旨在超越傳統文件處理解決方案的限制,著重於速度、準確性和工程靈活性。
透過共識建立信任: LLMChallenge (雙LLM共識引擎)是其核心區別所在,在傳統系統僅依賴信心分數或單模型輸出的情況下,它能捕捉並消除不實資訊。這確保了生產級資料的完整性。
最高效率,最低成本: 透過 SinglePass 和 Summarized Extraction 等專業優化技術,實現高達 7倍的Token使用量減少。這大幅降低營運成本,同時提升處理速度。
開源靈活性: 作為一個開源、無程式碼平台,Unstract 為組織提供完全的透明度和控制。它支援多LLM環境(OpenAI、Claude、Azure GPT、Vertex),並允許您根據特定的合規性和效能需求,選擇最佳的向量資料庫(Vector DB)、嵌入模型(Embedding Model)和文字提取服務。
超越IDP和RPA: 透過利用尖端的LLM能力,Unstract 解決了非結構化資料的核心挑戰——尤其是高變異和不一致的格式問題——超越了傳統IDP和RPA基於規則或模板的限制。
結論
Unstract 提供必要的工具和生產架構,將複雜、高變異的文件轉化為可供部署的結構化、可信任資料。專為精準度和規模而打造,它賦予工程師實現更好的自動化擴展,並大幅減少人工監管。
探索 Unstract 如何幫助您實現最大化的提取效率,並部署您的下一個資料管線。 立即開始您的14天免費試用。
More information on Unstract
Launched
2023-08
Pricing Model
Freemium
Starting Price
Global Rank
451302
Follow
Month Visit
74.5K
Tech used
WordPress,Elementor,Bootstrap,animate.css,Clipboard.js,Font Awesome,Google Analytics,Google Font API,Google Tag Manager,HubSpot Analytics,Linkedin Insight Tag,Prism,Slick,Swiper Slider,jQuery,jQuery Migrate
Top 5 Countries
14.99%
8.71%
8.58%
7.61%
6.02%
United States
Nigeria
India
Brazil
Germany
Traffic Sources
15.81%
0.86%
0.11%
9.05%
40.45%
33.65%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
Unstract was manually vetted by our editorial team and was first featured on 2024-06-19.
Related Searches
Unstract 替代方案
更多 替代方案-

-

-

-

Parse Extract: 先進的資料萃取與光學字元辨識技術,專為大型語言模型(LLM)管線設計。能將繁雜的文件與網路數據,轉化為清晰易懂、可供LLM使用的文本。兼具成本效益與安全保障。
-
