
What is Unstract?
Unstract는 대규모 언어 모델(LLM)을 활용하여 복잡한 비정형 문서에서 높은 정확도로 데이터를 추출하도록 특별히 제작된 오픈소스 노코드 플랫폼입니다. 이 플랫폼은 다양한 형태의 문서를 준비하고 처리하는 과정에서 발생하는 수동적인 복잡성을 효과적으로 제거합니다. 이를 통해 정밀함과 확장성을 추구하는 선도적인 엔지니어와 조직은 핵심 비정형 데이터 자산을 위해 신뢰할 수 있고 감사 가능한 API 및 ETL 파이프라인을 배포할 수 있습니다.
주요 기능
Unstract는 임의의 문서 입력을 깔끔하고 신뢰할 수 있으며 시스템에서 바로 사용할 수 있는 JSON 또는 CSV 데이터로 변환하는 데 필요한 아키텍처 구성 요소를 제공합니다.
🧠 LLMChallenge: Dual-LLM Consensus Engine
이 독자적인 메커니즘은 두 개의 독립적인 LLM(추출자 및 검증자)을 사용하여 결과를 검증함으로써 데이터 신뢰도를 높입니다. 이 시스템은 '틀린 것보다 NULL이 낫다'는 원칙에 따라 작동하며, 프로세스 초기에 환각(hallucination) 현상을 감지하고 걸러냅니다. 이를 통해 정확하게 검증된 값만 반환되어 자동화된 워크플로우의 무결성이 크게 향상됩니다.
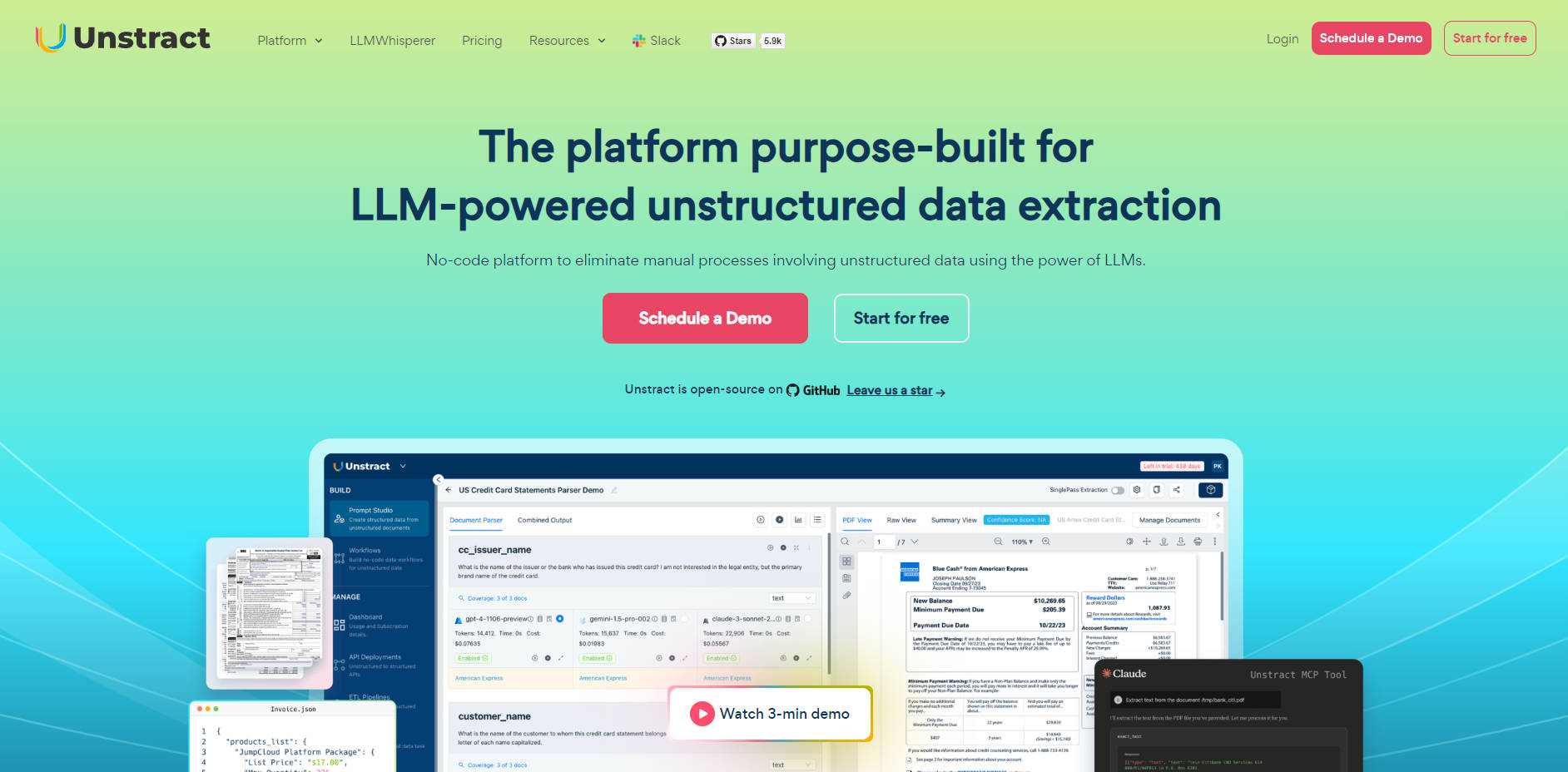
🛠️ Prompt Studio: Dedicated Engineering Environment
Prompt Studio는 프롬프트 엔지니어가 추출 로직을 신속하게 구축, 테스트 및 개선할 수 있도록 특화된 작업 공간을 제공합니다. 소수의 대표 문서 샘플로 일반적인 프롬프트를 빠르게 구축하고, 일관된 스키마를 강제 (단순 텍스트에서 중첩 JSON까지)하며, 내장된 버전 관리 기능을 활용하여 손쉬운 테스트 및 롤백을 수행할 수 있습니다. 이러한 기능은 복잡하고 높은 정밀도를 요구하는 배포에 필요한 제어 기능을 제공합니다.
🖼️ LLMWhisperer: Layout-Preserving Document Preparation
실제 문서(스캔된 PDF, 다단 양식 또는 스마트폰으로 촬영한 이미지)를 처리하려면 지능적인 사전 처리가 필수적입니다. LLMWhisperer는 보조 서비스 역할을 하여 LLM이 가장 잘 이해할 수 있는 형식으로 고도로 최적화된 결과물을 생성합니다. 이 서비스의 독자적인 레이아웃 보존 모드는 LLM이 다단 레이아웃, 양식, 표를 정확하게 해석하고, 심지어 손글씨 텍스트, 체크박스, 라디오 버튼까지 안정적으로 감지할 수 있도록 합니다.
⚡ SinglePass & Summarized Extraction for Cost Efficiency
토큰 사용을 최적화하여 비용 절감과 속도 향상을 극대화합니다. SinglePass Extraction은 전체 문서를 대상으로 모든 필드 추출 프롬프트를 하나의 대규모 단일 실행으로 통합합니다. 다른 방법으로, Summarized Extraction은 입력 문서의 극도로 압축된 버전을 자동으로 구성하고, 이 최적화된 버전을 대상으로 프롬프트를 실행하여 더 적은 텍스트를 처리합니다. 이러한 전략은 토큰 사용량을 최대 7배까지 줄여 최소한의 비용으로 최대의 추출 효과를 제공합니다.
🧑💻 Human-in-the-Loop (HITL) Validation
절대적인 확실성을 요구하는 프로덕션급 데이터의 경우, HITL 기능은 자동화된 추출과 완벽한 데이터 사이의 간극을 메워줍니다. 신뢰도 점수 또는 필드 값을 기반으로 스마트 라우팅 규칙을 구성하여 팀이 예외적인 경우(edge cases)만 검토하도록 할 수 있습니다. 사용자는 원본 문서와 나란히 추출된 데이터를 볼 수 있으며, 원본 문서 하이라이팅을 활용하여 즉각적인 검증, 오류 수정 및 완벽하게 감사 가능한 기록을 유지할 수 있습니다.
활용 사례
Unstract는 기존의 지능형 문서 처리(IDP) 및 로봇 프로세스 자동화(RPA) 시스템이 어려움을 겪는 복잡성과 확장성을 처리하도록 구축되었습니다.
고변동 문서 처리: 매우 다양한 문서와 관련된 작업을 쉽게 자동화할 수 있습니다. 예를 들어, 200개 은행의 은행 명세서를 처리하거나 50개 주에서 각기 다른 형태로 사용되는 동일한 양식을 처리하는 등의 작업이 포함됩니다. Unstract는 문서 유형(variant)에 관계없이 일관되고 구조화된 JSON 출력을 보장합니다.
복잡한 계약 분석 자동화: 엔지니어는 LLMWhisperer와 SinglePass extraction을 활용하여 송장에서 특정 세부 항목을 효율적으로 추출하거나, 긴 법률 계약서 내의 핵심 조항을 정확히 찾아낼 수 있습니다. 이는 기존에 사람만이 수행하던 검토 작업을 신뢰할 수 있는 자동화된 워크플로우로 전환합니다.
데이터 에코시스템 통합: 클라우드 파일 스토리지에 저장된 비정형 문서를 구조화하고, 사전 구축된 ETL 파이프라인을 사용하여 데이터 웨어하우스 및 데이터베이스로 자동 전송합니다. 또는 Unstract API를 호출하여 기존 애플리케이션에 추출 기능을 직접 통합함으로써, 데이터 수집 시점에서 문서 구조화를 원활하게 수행할 수 있습니다.
독점적 장점
Unstract는 속도, 정확성, 엔지니어링 유연성에 중점을 두어 기존 문서 처리 솔루션의 한계를 뛰어넘도록 설계되었습니다.
합의를 통한 신뢰: LLMChallenge (Dual-LLM 합의 엔진)는 핵심적인 차별화 요소로, 기존 시스템이 신뢰도 점수나 단일 모델 출력에만 의존하는 반면, 이 엔진은 환각 현상을 감지하고 제거합니다. 이는 프로덕션급 데이터 무결성을 보장합니다.
최대 효율, 최소 비용: SinglePass 및 Summarized Extraction과 같은 특화된 최적화 기술을 통해 최대 7배의 토큰 사용량 절감을 달성합니다. 이는 운영 비용을 크게 절감하고 처리 속도를 향상시킵니다.
오픈소스 유연성: 오픈소스 노코드 플랫폼인 Unstract는 조직에 완벽한 투명성과 제어권을 제공합니다. 이 플랫폼은 다중 LLM 환경(OpenAI, Claude, Azure GPT, Vertex)을 지원하며, 사용자의 특정 규정 준수 및 성능 요구사항에 맞춰 최적의 Vector DB, Embedding Model, Text Extraction 서비스를 선택할 수 있도록 합니다.
IDP 및 RPA를 넘어서: Unstract는 최첨단 LLM 기능을 활용하여 비정형 데이터의 핵심 과제(특히 높은 변동성과 일관되지 않은 형식)를 해결하며, 기존 IDP 및 RPA의 규칙 기반 또는 템플릿 의존적 한계를 뛰어넘습니다.
결론
Unstract는 복잡하고 변화무쌍한 문서를 배포 준비가 된 구조화되고 신뢰할 수 있는 데이터로 전환하는 데 필요한 도구와 프로덕션 아키텍처를 제공합니다. 정밀성과 확장성을 염두에 두고 구축된 Unstract는 엔지니어가 자동화 확장성을 향상시키고 수동 감독을 대폭 줄일 수 있도록 지원합니다.
Unstract가 어떻게 최대 추출 효율성을 달성하고 다음 데이터 파이프라인을 배포하는 데 도움이 될 수 있는지 알아보세요. 지금 14일 무료 체험을 시작하세요.
More information on Unstract
Launched
2023-08
Pricing Model
Freemium
Starting Price
Global Rank
451302
Follow
Month Visit
74.5K
Tech used
WordPress,Elementor,Bootstrap,animate.css,Clipboard.js,Font Awesome,Google Analytics,Google Font API,Google Tag Manager,HubSpot Analytics,Linkedin Insight Tag,Prism,Slick,Swiper Slider,jQuery,jQuery Migrate
Top 5 Countries
14.99%
8.71%
8.58%
7.61%
6.02%
United States
Nigeria
India
Brazil
Germany
Traffic Sources
15.81%
0.86%
0.11%
9.05%
40.45%
33.65%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
Unstract was manually vetted by our editorial team and was first featured on 2024-06-19.
Related Searches
Unstract 대체품
더보기 대체품-

-

Unsiloed AI는 고급 AI 에이전트를 활용하여 비정형 문서를 구조화된, 실행 가능한 데이터로 전환하는 최첨단 플랫폼입니다.
-

DocStrange: 오픈소스 파이썬 라이브러리. 모든 문서를 개인 정보 보호와 정확성을 겸비한, LLM 및 RAG 활용에 최적화된 AI 구조화 데이터로 전환합니다.
-

Parse Extract: LLM 파이프라인을 위한 고급 데이터 추출 및 OCR. 복잡한 문서와 웹 데이터를 LLM이 즉시 활용할 수 있는 깔끔한 텍스트로 전환합니다. 비용 효율성은 물론, 강력한 보안까지 제공합니다.
-

DeepTagger: 노코드 AI가 문서에서 지능적으로 데이터를 자동 추출합니다. 복잡한 문서를 구조화되고 즉시 활용 가능한 데이터로 전환하여 숨겨진 통찰력을 발굴하세요.