
2025 Лучших LangExtract Альтернативи
-

Автоматизируйте высокоточное извлечение структурированных данных из любого документа с NuExtract AI. Получайте надежные результаты с минимальными галлюцинациями для критически важных рабочих процессов.
-

Parse Extract: Передовое извлечение данных и ОРС для конвейеров LLM. Превращает сложные документы и веб-данные в чистый текст, готовый для обработки LLM. Экономично и безопасно.
-

ContextGem: LLM-фреймворк для точного извлечения структурированных данных из документов. Автоматизируйте рабочие процессы и сосредоточьтесь на анализе, а не на рутинных задачах.
-

Extractor API: Извлекайте чистые, структурированные данные с любой веб-страницы, из PDF или новостей с AI. Автоматизируйте сложный веб-скрейпинг и используйте LLMs для глубоких инсайтов.
-

Unstract: Открытая, бескодовая LLM-платформа для высокоточного извлечения неструктурированных данных. Получайте надежные, проверяемые данные из сложных документов.
-

LlamaParse — это решение для предоставления больших языковых моделям данных из сложных документов. Он обрабатывает таблицы, графики и другие элементы, предлагает возможности пользовательского парсинга, поддержку нескольких языков, простую интеграцию API и соответствует стандарту SOC 2.
-

С легкостью извлекайте структурированные веб-данные с любого сайта, используя ИИ. Код не нужен! Определяйте в точности, что вам нужно, с помощью промптов и схемы.
-
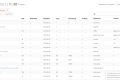
С легкостью находите, сравнивайте и ранжируйте крупные языковые модели с помощью LLM Extractum. Упростите процесс выбора и стимулируйте инновации в приложениях ИИ.
-

OneFileLLM: CLI-инструмент для унификации данных, предназначенных для LLM. Поддерживает GitHub, ArXiv, веб-скрейпинг и многое другое. Вывод в формате XML и подсчет токенов. Хватит бороться с данными!
-

Langfuse поможет вам раскрыть весь потенциал приложений LLM. Отслеживайте, отлаживайте и повышайте производительность с помощью наблюдаемости и аналитики. С открытым исходным кодом и возможностью настройки.
-

Spykio: Получайте действительно релевантные ответы от LLM. Контекстно-зависимый поиск, выходящий за рамки векторного поиска. Точные и содержательные результаты.
-

DocStrange: Библиотека Python с открытым исходным кодом. Преобразует любой документ в структурированные данные, готовые к обработке ИИ, для LLM и RAG, с сохранением конфиденциальности и высокой точности.
-

DeepTagger: Бескодовый ИИ автоматизирует интеллектуальное извлечение данных из документов. Преобразуйте сложные документы в структурированные, пригодные для анализа данные и получите ценные выводы.
-

DocExtractor использует искусственный интеллект для точного и быстрого извлечения данных из неструктурированных документов, экономя время, минимизируя ошибки и позволяя принимать решения на основе данных. Он обрабатывает различные форматы, легко интегрируется и имеет множество вариантов использования в разных отраслях.
-
Извлечение данных с точностью и простотой! Waveline Extract специализируется на точном извлечении из различных документов - данные для обучения не требуются. Попробуйте прямо сейчас!
-
Создавайте персонализированные ИИ-чат-боты на основе всех ваших источников данных. Получайте мгновенные и безопасные ценные сведения с помощью запросов на естественном языке — без кода.
-
Langbase – революционная платформа ИИ с модульной инфраструктурой. Обеспечивает скорость, гибкость и доступность. Развертывание за минуты. Поддерживает множество языковых моделей. Идеально подходит для разработчиков. Экономия средств. Универсальные варианты использования. Помогает в развитии ИИ.
-
Платформа LangWatch на базе открытого кода обеспечивает простое итерационное улучшение текущих конвейеров LLM, а также снижает риски, такие как побег из изоляции, утечка конфиденциальных данных и галлюцинации.
-

LangSearch предлагает бесплатные API для веб-поиска и переранжирования результатов. Улучшите свои AI-приложения, например, чат-боты. Получите доступ к миллиардам веб-документов. Бесплатно для индивидуальных пользователей и небольших команд. Присоединяйтесь к миссии AGI.
-

LanguageX: ИИ-агент для перевода. Организуйте работу кастомизированных ИИ-систем, редактирование в реальном времени и интеллектуальный подбор движков для получения профессиональных и высококачественных переводов.
-

Graphlit — это платформа с API-ориентированной архитектурой, созданная для разработчиков, занимающихся созданием приложений на базе искусственного интеллекта, работающих с неструктурированными данными и использующих знания предметной области в различных вертикальных рынках, таких как юриспруденция, продажи, индустрия развлечений, здравоохранение или инженерия.
-

Activeloop-L0: Your AI Knowledge Agent for accurate, traceable insights from all multimodal enterprise data. Securely in your cloud, beyond RAG.
-

Nanonets-OCR-s: Структурированный OCR: больше, чем просто текст. Извлекает таблицы, уравнения, подписи и многое другое из документов в markdown для ИИ.
-

LM Studio — это удобное настольное приложение для экспериментов с локальными и открытыми большими языковыми моделями (LLM). Кроссплатформенное настольное приложение LM Studio позволяет скачивать и запускать любую ggml-совместимую модель с Hugging Face, а также предоставляет простой, но мощный пользовательский интерфейс для настройки моделей и выполнения инференса. Приложение задействует ваш GPU по возможности.
-

Сложности с исследованиями? Linnk AI — ваш ИИ-копилот для академической и профессиональной работы. Анализируйте документы, выполняйте контекстный перевод и визуализируйте ключевые идеи.
-
Тестируйте, сравнивайте и дорабатывайте промты на свыше 50 LLM мгновенно — без API-ключей и регистрации. Применяйте JSON-схемы, проводите тесты и сотрудничайте. Разрабатывайте лучший ИИ быстрее с LangFast.
-

LangDB AI Gateway — это ваш универсальный командный центр для рабочих процессов ИИ. Он предлагает унифицированный доступ к более чем 150 моделям, экономию затрат до 70% благодаря интеллектуальной маршрутизации и простую интеграцию.
-

Извлекайте данные из любых неструктурированных документов с помощью Extracta.ai. Автоматически анализируйте отсканированные документы и извлекайте необходимую информацию.
-

Извлекайте текст с изображений по всему миру! EasyOCR — это библиотека Python для высокоточного многоязычного оптического распознавания символов (OCR), поддерживающая более 80 языков и сложные системы письма. Просто, мощно, глубокое обучение.
-

Специалисты по обработке данных тратят много времени на очистку данных для обучения больших языковых моделей, но Uniflow, библиотека с открытым исходным кодом для Python, упрощает процесс извлечения и структурирования текста из PDF-документов.