
What is Ludwig?
构建、训练和部署诸如大型语言模型 (LLMs) 或专用神经网络等定制 AI 模型,通常需要在复杂的代码库中摸索,并管理错综复杂的基础设施。而 Ludwig 提供了一条不同的路径。它是一个声明式的低代码框架,可以简化整个流程,让您专注于建模本身,而无需陷入工程的复杂性中。无论您是微调现有的 LLM,还是从头开始设计独特的多模态架构,Ludwig 都提供了以非凡的简易性构建复杂模型的工具。
主要特性
🛠️ 通过配置构建自定义模型: 使用简单的声明式 YAML 文件定义您的整个模型架构、特征和训练过程。Ludwig 可以处理底层代码的生成,无缝支持多任务和多模态学习。其全面的验证检查可以在运行前捕获错误。
⚡ 针对规模和效率进行了优化: 有效训练大型模型。Ludwig 整合了自动批量大小调整、分布式训练(DDP、DeepSpeed)、参数高效微调 (PEFT) 方法(如 LoRA 和 QLoRA(4 位量化))、分页优化器,并通过 Ray 集成支持大于内存的数据集。
📐 保留专家级控制: 低代码并不意味着低控制。您可以指定所有内容,直至激活函数。Ludwig 集成了超参数优化 (HPO) 工具,提供了解释性方法(特征重要性、反事实),并生成丰富的可视化效果来评估模型指标。
🧱 通过模块化快速进行实验: 将 Ludwig 视为深度学习的构建块。其模块化设计使您可以通过在配置文件中进行小的更改来交换编码器、组合器和解码器,试验不同的任务、特征或模态,从而促进快速迭代。
🚢 为生产而设计: 从实验到部署的平稳过渡。Ludwig 提供预构建的 Docker 容器,原生支持 Kubernetes 上的 Ray,并允许您将模型导出为标准格式,如 Torchscript 和 Triton Inference Server。您甚至可以使用单个命令将训练好的模型直接上传到 HuggingFace Hub。
用例:Ludwig 的实际应用
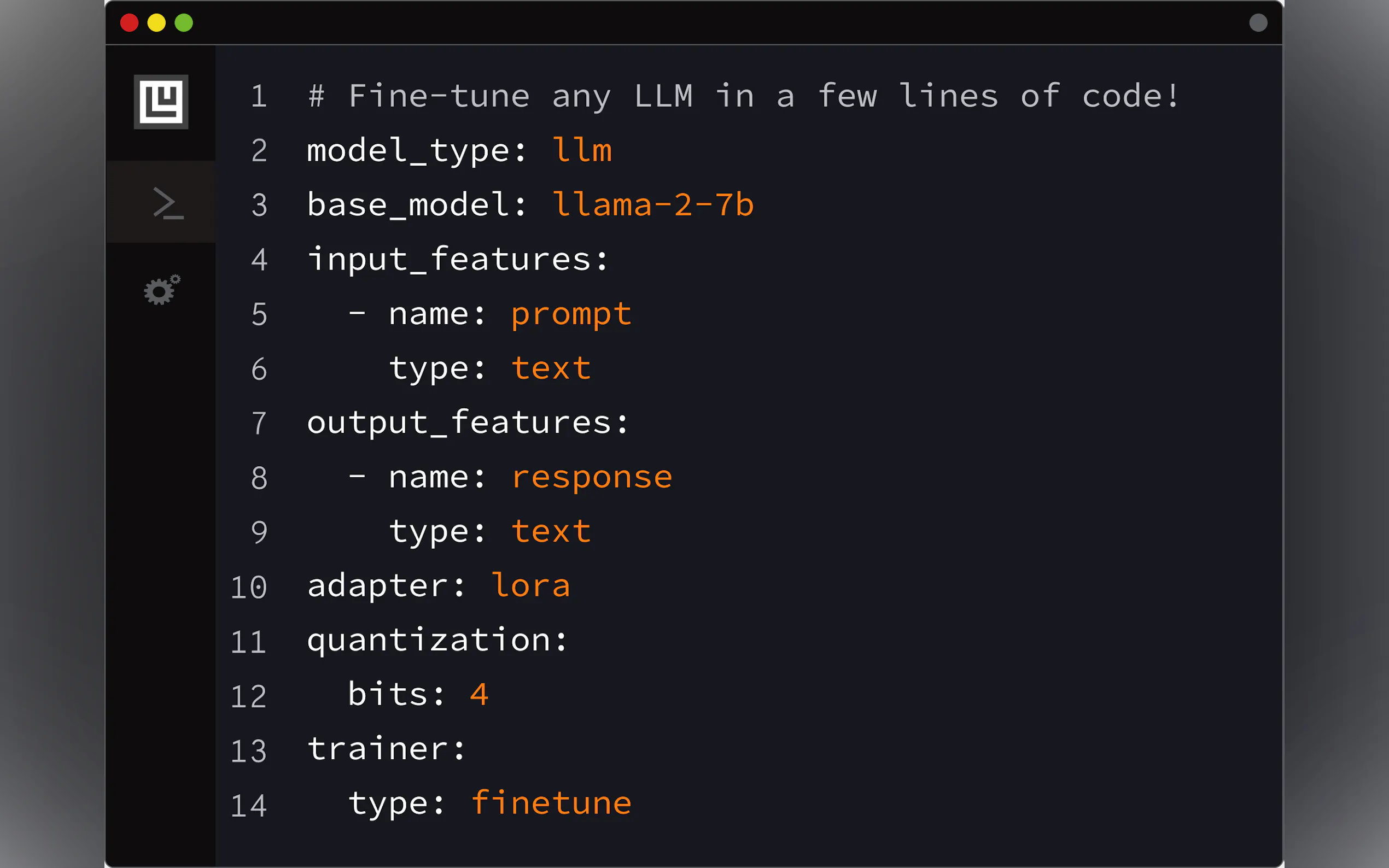
为特定任务微调 LLM: 假设您需要一个根据您公司内部文档定制的聊天机器人。使用 Ludwig,您可以采用像 Llama-2 或 Mistral-7b 这样的预训练模型,定义一个简单的 YAML 配置来指定您的数据(指令/响应对),设置 4 位量化 (QLoRA) 以提高效率,并通过单个命令 (
ludwig train) 启动微调过程。这使您可以在消费级 GPU(如 Nvidia T4)上创建专门的、遵循指令的 LLM,而无需编写大量的训练代码。构建多模态分类器: 假设您想根据文本评论、产品类别(集合)、内容评级(类别)、运行时长(数字)和评论者状态(二进制)来预测产品推荐的成功率。使用 Ludwig,您可以在 YAML 配置中定义每个不同的输入类型,指定它们各自的类型(
text、set、category、number、binary),选择合适的编码器(例如,embed用于文本),并定义二进制输出特征(recommended)。Ludwig 会自动构建适当的网络架构来处理这些混合数据类型,并训练分类器。快速原型设计和部署: 您有一个数据集,需要快速构建和部署分类模型。使用 Ludwig 的 AutoML 功能 (
ludwig.automl.auto_train),您只需提供数据集、目标变量和时间限制。Ludwig 会探索不同的模型配置和超参数,以找到性能优异的模型。训练完成后,您可以使用ludwig serve立即为您的模型启动 REST API,使其立即可用于预测。
结论
Ludwig 大大降低了构建复杂、定制 AI 模型的入门门槛。通过用声明式配置系统取代复杂的样板代码,它可以加速实验和开发。其内置的优化确保您可以高效地进行大规模训练,而其生产就绪的功能简化了部署。如果您希望微调 LLM、构建多模态系统,或者只是更快地迭代您的深度学习项目,Ludwig 提供了一个强大且易于访问的框架。



More information on Ludwig
Launched
2019-01
Pricing Model
Free
Starting Price
Global Rank
3670965
Follow
Month Visit
5.6K
Tech used
Fastly,GitHub Pages,Varnish
Top 5 Countries
44.66%
33.08%
12.24%
10.02%
United States
India
Canada
Germany
Traffic Sources
6.52%
1.17%
0.1%
8.54%
40.47%
42.96%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
Ludwig was manually vetted by our editorial team and was first featured on 2023-08-10.
Related Searches
Ludwig 替代方案
更多 替代方案-

-

-

LLaMA Factory 是一款开源的低代码大型模型微调框架,它集成了业界广泛使用的微调技术,并通过 Web UI 界面支持大型模型的零代码微调。
-
-

Transformer Lab:一个开源平台,无需编码即可在本地构建、微调和运行大型语言模型 (LLM)。下载数百个模型,跨硬件微调,聊天,评估等等。