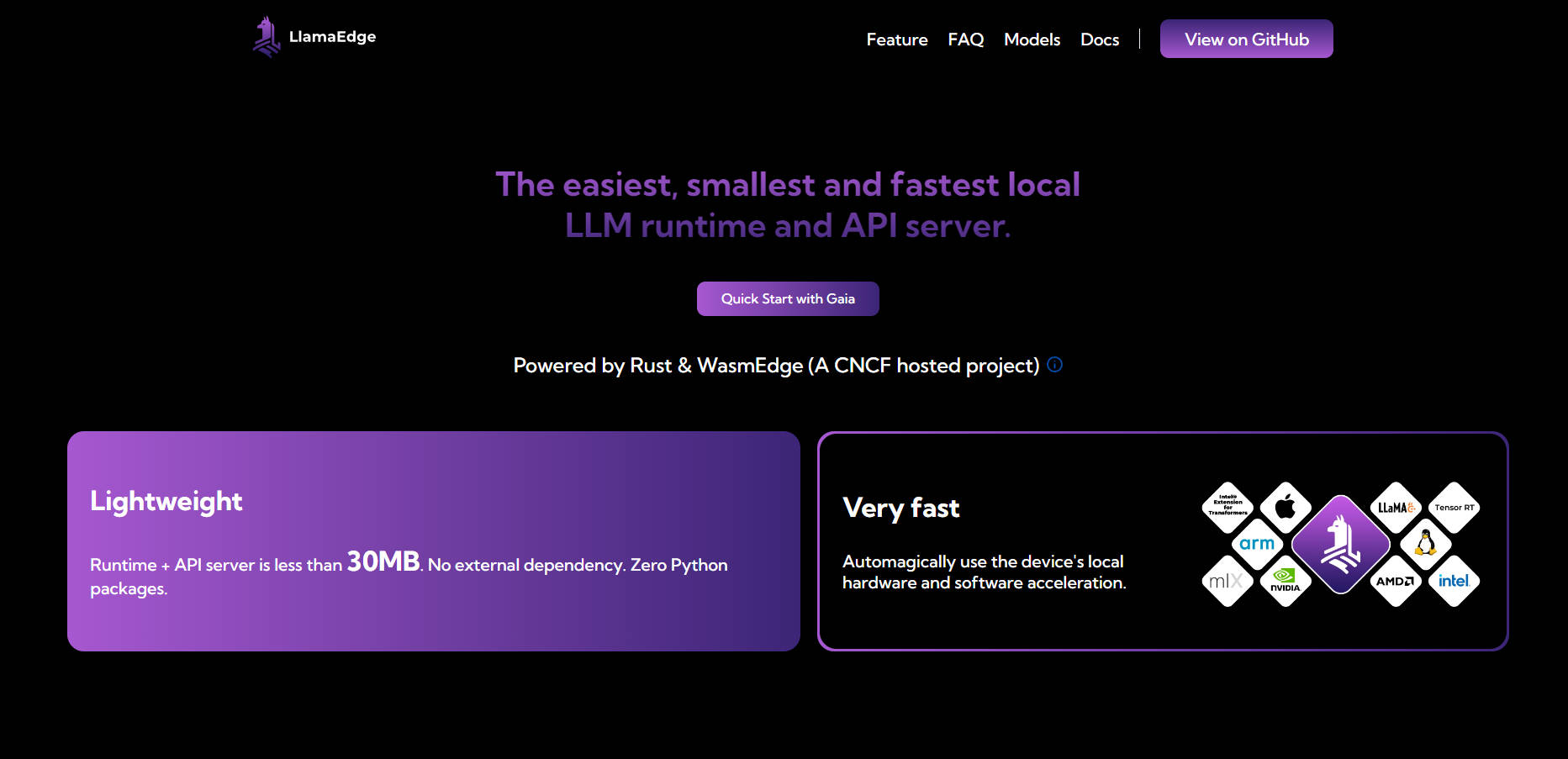
What is LlamaEdge?
想像一下,您有能力直接在您的裝置上執行和微調大型語言模型(LLM),無需雲端、無需複雜性,且不犧牲效能。這正是 LlamaEdge 所能提供的。無論您是開發人員,正在建構 AI 驅動的應用程式,還是企業,希望部署私有化的、客製化的 LLM,LlamaEdge 都是您一直在等待的輕量、快速且可攜式的解決方案。
LlamaEdge 的執行環境小於 30MB,且零依賴性,旨在簡化在本地或邊緣執行 LLM 的過程。它充分利用您裝置的硬體,確保原生速度和無縫的跨平台部署。
主要特色
💡 在本地或邊緣執行 LLM
直接在您的裝置上部署和微調 LLM,確保資料隱私,並消除對昂貴雲端服務的依賴。
🌐 跨平台相容性
一次編寫您的程式碼,並將其部署到任何地方,無論是在 MacBook、NVIDIA GPU 還是邊緣裝置上。無需為不同的平台重建或重新測試。
⚡ 輕量且快速
LlamaEdge 的執行環境小於 30MB,且沒有外部依賴性,非常輕巧。它可以自動利用您裝置的硬體加速,以獲得最佳效能。
🛠️ 用於客製化的模組化設計
使用 Rust 或 JavaScript 像樂高積木一樣組裝您的 LLM 代理程式和應用程式。建立緊湊、獨立的二進位檔案,這些檔案可以在各種裝置上無縫執行。
🔒 增強的隱私和安全性
確保您的資料位於本地且安全。LlamaEdge 在沙盒環境中執行,無需 root 權限,並確保您的互動保持私密。
使用案例
建構私有 AI 助理
建立完全在您的裝置上執行的 AI 驅動的聊天機器人或虛擬助理,在保護敏感資料的同時,提供快速、反應靈敏的互動。開發客製化的 LLM 應用程式
針對特定行業或使用案例微調 LLM,無論是法律文件分析、客戶支援還是醫療保健診斷,都無需基於雲端的解決方案。在邊緣裝置上部署 AI
將 AI 功能引入物聯網感測器或行動應用程式等邊緣裝置,實現即時決策,而不會產生延遲或連線問題。
為什麼選擇 LlamaEdge?
具成本效益: 避免託管 LLM API 的高昂成本,以及管理雲端基礎設施的複雜性。
可客製化: 根據您的特定需求客製化 LLM,不受通用模型的限制。
可攜式: 使用單一二進位檔案,跨不同的平台和裝置部署您的應用程式。
面向未來: 透過對多模態模型、替代執行環境和新興 AI 技術的支援,保持領先地位。
常見問題
問:LlamaEdge 與基於 Python 的解決方案相比如何?
答:基於 Python 的解決方案(如 PyTorch)帶有大量的依賴性,並且在生產級推論方面速度較慢。另一方面,LlamaEdge 輕量(小於 30MB)、更快,並且沒有依賴性衝突。
問:LlamaEdge 與 GPU 和硬體加速器相容嗎?
答:絕對相容。LlamaEdge 會自動利用您裝置的硬體加速,確保在 CPU、GPU 和 NPU 上實現原生速度。
問:我可以將 LlamaEdge 與現有的開源模型一起使用嗎?
答:可以。LlamaEdge 支援各種 AI/LLM 模型,包括整個 Llama2 系列,並允許您針對您的特定需求進行微調。
問:是什麼讓 LlamaEdge 比其他解決方案更安全?
答:LlamaEdge 在沙盒環境中執行,無需 root 權限,並確保您的資料永遠不會離開您的裝置,使其成為敏感應用程式更安全的選擇。
準備好開始了嗎?
有了 LlamaEdge,在本地執行和微調 LLM 從未如此簡單。無論您是建構 AI 驅動的應用程式,還是在邊緣裝置上部署模型,LlamaEdge 都能讓您以更少的資源做更多的事情。立即安裝它,體驗本地 LLM 部署的未來。
More information on LlamaEdge
Launched
2024-01
Pricing Model
Free
Starting Price
Global Rank
3992632
Follow
Month Visit
<5k
Tech used
Google Analytics,Google Tag Manager,Fastly,Google Fonts,GitHub Pages,Gzip,Varnish
Top 5 Countries
43.76%
37.88%
15.81%
2.54%
Germany
United States
India
France
Traffic Sources
4.01%
1.54%
0.13%
10.31%
25.52%
57.47%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 25, 2025)
LlamaEdge was manually vetted by our editorial team and was first featured on 2025-02-11.
Related Searches