
What is CogVLM & CogAgent?
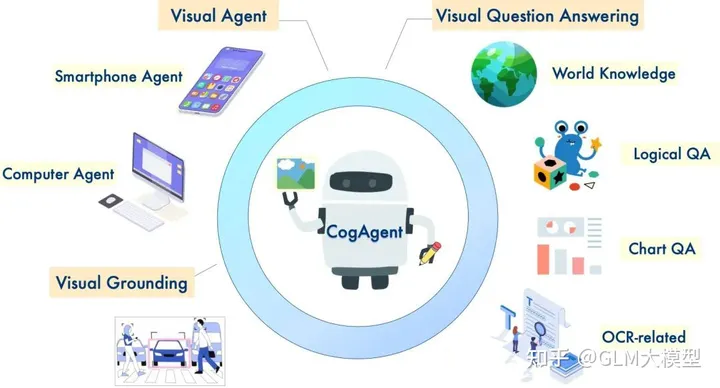
CogVLM и CogAgent — это мощные языковые модели с открытым исходным кодом, которые отлично подходят для понимания изображений и многоходового диалога. CogVLM-17B достигает передовых результатов в различных кросс-модальных тестах, демонстрируя свои надежные возможности в создании подписей к изображениям, ответе на визуальные вопросы и заземлении задач. Улучшенная версия CogAgent-18B еще больше расширяет эти возможности и представляет собой функциональность GUI Agent, позволяющую взаимодействовать с изображениями высокого разрешения и выполнять задачи с помощью скриншотов GUI.
Ключевые особенности:
1️⃣ Понимание изображений и диалог (CogVLM-17B):
?️ Обрабатывает понимание изображений и генерирует подробные описания.
? Участвует в многоходовых диалогах с визуальным контекстом.
2️⃣ GUI-агент и расширенные возможности (CogAgent-18B):
?️ Поддерживает входные изображения с высоким разрешением (1120x1120) для лучшего визуального восприятия.
?? Обладает возможностями GUI-агента, выполняя задачи и отвечая на вопросы, связанные со скриншотами GUI.
? Демонстрирует улучшенные возможности, связанные с OCR, благодаря специализированному обучению.
3️⃣ Заземление и несколько режимов диалога:
? Предоставляет описания изображений с координатами ограничивающего прямоугольника для объектов.
? Получает координаты ограничивающего прямоугольника на основе описаний объекта.
? Генерирует описания из указанных координат ограничивающего прямоугольника.
Варианты использования:
? Визуальное рассуждение на естественном языке:CogVLM и CogAgent отлично справляются с задачами, требующими визуального восприятия и генерации языка, такими как создание подписей к изображениям, ответ на визуальные вопросы и заземление задач.
? Взаимодействие и автоматизация GUI:Возможности GUI Agent у CogAgent делают его подходящим для задач, связанных со взаимодействием со скриншотами GUI, такими как веб-страницы, приложения и программное обеспечение.
? Ответы на вопросы с визуальным контекстом:Обе модели могут отвечать на вопросы, связанные с изображениями, предоставляя информативные ответы, основанные на понимании визуального контекста.
? Генерация языка с визуальным вводом:На основе изображения CogVLM и CogAgent могут генерировать подробные описания, истории или диалоги, которые согласуются с визуальным содержанием.
Заключение:
CogVLM и CogAgent — это универсальные языковые модели, которые сочетают в себе понимание изображений, многоходовой диалог и функциональность GUI Agent. Их мощные возможности делают их ценными активами для различных приложений, включая визуальное рассуждение на основе естественного языка, взаимодействие и автоматизацию GUI, ответы на вопросы с визуальным контекстом и генерацию языка с визуальным вводом.
More information on CogVLM & CogAgent
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
CogVLM & CogAgent was manually vetted by our editorial team and was first featured on 2024-01-28.
Related Searches




