
What is CogVLM & CogAgent?
CogV とCogQ は、画像認識とマルチターン対話において強力なオープンソースのビジュアル言語 モデルです。CogV-17B は、さまざまな交差モーダル ベンチマークで最先端のパフォーマンスを実現し、画像キャプショ ning、視覚的質問応答、グラウンディング タスクにおけるその能力を示しています。改良バージョの n のCogQ-18B は、これらの能力を向上させ、GUI 機能を導入し、高解像度画像とGUI スクリ ンショットに関するタスクを使用できるようにしています。
主な特長:
1️⃣ 画像認識と対話(CogV-17B):
画像認識を処理し、詳細な説明を します。
視覚的背景を使用して、マルチターン対話を行います。
2️⃣ 向上した能力(CogQ-18B):
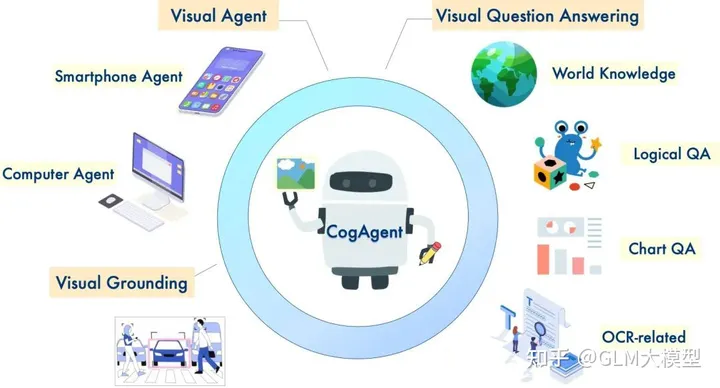
より優れた視覚認識のために、高解像度画像(1120x1120)をサポートしています。
GUI 機能を備えて おり、GUI スクリーンショットに関するタスクを実行したり、質問に答えたりできます。
大規模なトレーニングを通じて、OCR 関連の能力が向上しています。
3️⃣ 説明と対話モードの向上
物体のバウンディングボックスを使用して、画像説明を提供します。
物体の説明に基づいて、バウンディングボックスを取得します。
特定のバウンディングボックスから説明を します。
ユースケース:
視覚的認識と言語処理が必要なタスクで、CogV とCogQ は、画像キャプショ ning、視覚的質問応答、グラウンディング タスクなどで利用できます。
CogQ のGUI 機能は、Web ページ、アプリケーション、ソフトウェアなど、GUI スクリーンショットに関するタスクに適しています。
視覚的背景に関する質問に答えることができ、視覚的背景の理解を活用した有益な応答を提供します。
画像を入力すると、CogV とCogQ は、視覚的コンテンツと一致した詳細な説明、ストーリー、または文章を できます。
結論:
CogV とCogQ は、画像認識、マルチターン対話、GUI 機能を備えている汎用的なビジュアル言語 モデルです。その強力な能力は、自然言語ベースの視覚的認識、GUI インタラクションとオートメーション、視覚的背景を使用した質問応答、視覚的入力を用いた言語処理など、さまざまなアプリケーションで価値ある資産になります。
More information on CogVLM & CogAgent
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
CogVLM & CogAgent was manually vetted by our editorial team and was first featured on 2024-01-28.
Related Searches




