
What is CogVLM & CogAgent?
CogVLM 和 CogAgent 是强大的开源视觉语言模型,在图像理解和多轮对话方面表现出色。CogVLM-17B 在各种跨模态基准上实现了最先进的性能,展示了其在图像字幕、视觉问答和基础任务中的强大功能。作为改进版本,CogAgent-18B 进一步增强了这些能力,并引入了 GUI Agent 功能,支持与高分辨率图像交互,并在 GUI 屏幕截图上执行任务。
主要特性:
1️⃣ 图像理解与对话(CogVLM-17B):
?️ 处理图像理解并生成详细描述。
? 在视觉语境中进行多轮对话。
2️⃣ GUI 代理和增强能力(CogAgent-18B):
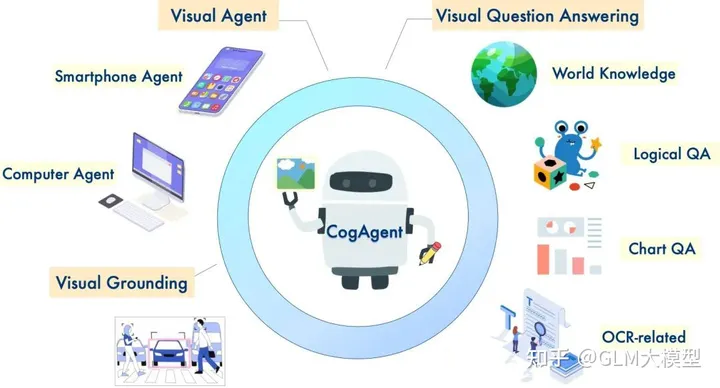
?️ 支持高分辨率图像输入(1120x1120),以实现更好的视觉理解。
?? 拥有 GUI 代理功能,执行任务并回答与 GUI 屏幕截图相关的问题。
? 通过专门训练展示了改进的 OCR 相关功能。
3️⃣ 基础和多种对话模式:
? 提供带有对象包围框坐标的图像描述。
? 根据对象描述检索包围框坐标。
? 根据指定的包围框坐标生成描述。
用例:
? 自然语言视觉推理:CogVLM 和 CogAgent 擅长需要视觉理解和语言生成的任务,例如图像字幕、视觉问答和基础任务。
? GUI 交互和自动化:CogAgent 的 GUI 代理功能使其适用于涉及 GUI 屏幕截图交互的任务,例如网页、应用程序和软件。
? 带有视觉语境的问答:这两个模型都可以回答与图像相关的提问,提供利用它们对视觉语境理解的信息丰富答复。
? 带有视觉输入的语言生成:给定一张图像,CogVLM 和 CogAgent 可以生成与视觉内容一致的详细描述、故事或对话。
结论:
CogVLM 和 CogAgent 是多功能的视觉语言模型,结合了图像理解、多轮对话和 GUI 代理功能。它们强大的功能使其成为各种应用的有价值资产,包括基于自然语言的视觉推理、GUI 交互和自动化、带有视觉语境的问答以及带有视觉输入的语言生成。
More information on CogVLM & CogAgent
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
CogVLM & CogAgent was manually vetted by our editorial team and was first featured on 2024-01-28.
Related Searches




