
What is CogVLM & CogAgent?
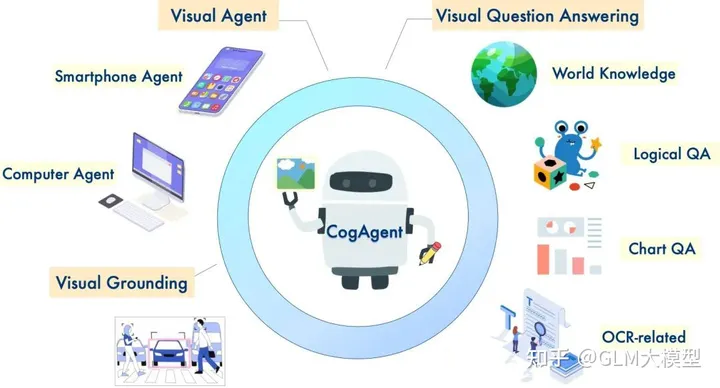
CogVLM 和 CogAgent 是強大的開源視覺語言模型,在影像理解和多輪對話方面表現優異。CogVLM-17B 在各種跨模式基準測試中達成最先進的效能,展示其在影像字幕、視覺問答和基底作業的強大功能。作為改良版本,CogAgent-18B 進一步增強這些功能,並導入 GUI 代理功能,讓使用者得以與高解析度影像互動並在 GUI 螢幕擷取上執行作業。
主要功能:
1️⃣ 影像理解與對話(CogVLM-17B):
?️ 處理影像理解並產生詳細說明。
? 參與具備視覺背景的多輪對話。
2️⃣ GUI 代理與增強功能(CogAgent-18B):
?️ 支援高解析度影像輸入(1120x1120),以獲得更好的視覺理解。
?? 擁有 GUI 代理功能,執行作業並回答與 GUI 螢幕擷取相關的問題。
? 透過專門訓練,展現改良的光學字元辨識相關功能。
3️⃣ 基底與多重對話模式:
? 提供影像說明,並標示物件的邊界框座標。
? 根據物件說明取得邊界框座標。
? 從指定的邊界框座標產生說明。
使用案例:
? 自然語言視覺推理:CogVLM 和 CogAgent 在需要視覺理解和語言生成的任務中表現優異,例如影像字幕、視覺問答和基底作業。
? GUI 互動和自動化:CogAgent 的 GUI 代理功能使其適合執行與 GUI 螢幕擷取互動的任務,例如網頁、應用程式和軟體。
? 具備視覺背景的問答:這兩個模型都可以回答與影像相關的問題,提供充分利用其視覺背景理解的資訊性回應。
? 具備視覺輸入的語言產生:給定影像,CogVLM 和 CogAgent 可以產生與視覺內容相符的詳細說明、故事或對話。
結論:
CogVLM 和 CogAgent 是多功能的視覺語言模型,結合了影像理解、多輪對話和 GUI 代理功能。它們強大的能力使它們成為各種應用程式的寶貴資產,包括基於自然語言的視覺推理、GUI 互動和自動化、具備視覺背景的問答,以及具備視覺輸入的語言產生。
More information on CogVLM & CogAgent
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
CogVLM & CogAgent was manually vetted by our editorial team and was first featured on 2024-01-28.
Related Searches




