
What is CogVLM & CogAgent?
CogVLM y CogAgent son potentes modelos de lenguaje visual de código abierto que destacan en la comprensión de imágenes y los diálogos multiturno. CogVLM-17B logra un rendimiento de vanguardia en varios puntos de referencia multimodales, lo que demuestra sus sólidas capacidades en el subtitulado de imágenes, la respuesta a preguntas visuales y las tareas básicas. CogAgent-18B, una versión mejorada, mejora aún más estas capacidades e introduce funcionalidades del agente de GUI, lo que permite interacciones con imágenes de alta resolución y la realización de tareas en capturas de pantalla de GUI.
Características principales:
1️⃣ Comprensión de imágenes y diálogo (CogVLM-17B):
?️ Gestiona la comprensión de imágenes y genera descripciones detalladas.
? Participa en diálogos multiturno con contexto visual.
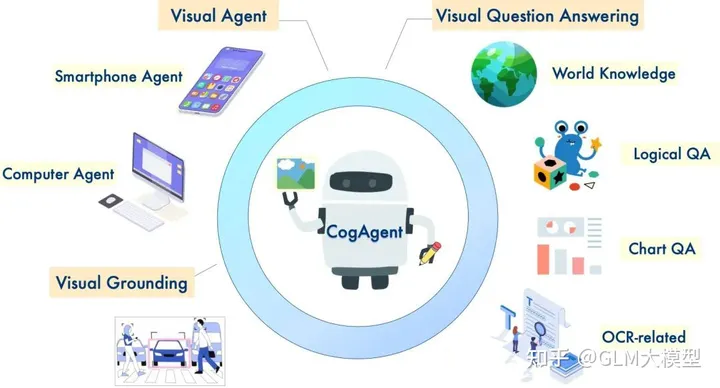
2️⃣ Agente de GUI y capacidades mejoradas (CogAgent-18B):
?️ Admite entradas de imágenes de alta resolución (1120x1120) para una mejor comprensión visual.
?? Posee capacidades de agente de GUI, realiza tareas y responde preguntas relacionadas con capturas de pantalla de GUI.
? Demuestra capacidades mejoradas relacionadas con OCR a través de capacitación especializada.
3️⃣ Conexión a tierra y múltiples modos de diálogo:
? Proporciona descripciones de imágenes con coordenadas de cuadro delimitador para objetos.
? Recupera las coordenadas del cuadro delimitador según las descripciones del objeto.
? Genera descripciones a partir de coordenadas de cuadro delimitador especificadas.
Casos de uso:
? Razonamiento visual del lenguaje natural: CogVLM y CogAgent destacan en tareas que requieren comprensión visual y generación de lenguaje, como el subtitulado de imágenes, la respuesta a preguntas visuales y las tareas básicas.
? Interacción y automatización de la GUI: Las capacidades del agente de GUI de CogAgent lo hacen adecuado para tareas que implican interacciones con capturas de pantalla de la GUI, como páginas web, aplicaciones y software.
? Respuestas a preguntas con contexto visual: Ambos modelos pueden responder preguntas relacionadas con imágenes, proporcionando respuestas informativas que aprovechan su comprensión del contexto visual.
? Generación de lenguaje con entrada visual: Dada una imagen, CogVLM y CogAgent pueden generar descripciones detalladas, historias o diálogos que sean coherentes con el contenido visual.
Conclusión:
CogVLM y CogAgent son modelos de lenguaje visual versátiles que combinan la comprensión de imágenes, el diálogo multiturno y las funcionalidades del agente de GUI. Sus potentes capacidades las convierten en activos valiosos para diversas aplicaciones, incluido el razonamiento visual basado en el lenguaje natural, la interacción y automatización de la GUI, la respuesta a preguntas con contexto visual y la generación de lenguaje con entrada visual.
More information on CogVLM & CogAgent
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
CogVLM & CogAgent was manually vetted by our editorial team and was first featured on 2024-01-28.
Related Searches




