
What is CogVLM & CogAgent?
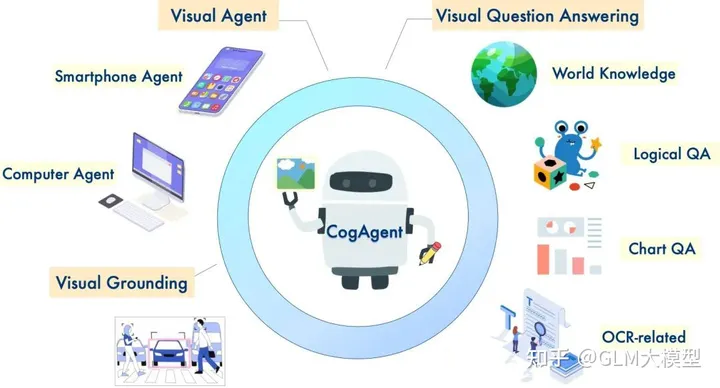
CogVLM 및 CogAgent는 이미지 이해와 여러 차례 대화에서 뛰어난 강력한 오픈 소스 시각적 언어 모델입니다. CogVLM-17B는 다양한 크로스 모달 벤치마크에서 최첨단 성능을 달성하여 이미지 캡션, 시각적 질문 답변, 그라운딩 과제에서 뛰어난 기능을 보여줍니다. 이를 개선한 버전인 CogAgent-18B는 이러한 기능을 더욱 향상시키고 GUI 에이전트 기능을 도입하여 고해상도 이미지와의 상호 작용 및 GUI 스크린샷에 대한 과제 수행이 가능해졌습니다.
주요 기능:
1️⃣ 이미지 이해 및 대화(CogVLM-17B):
?️ 이미지 이해를 처리하고 자세한 설명을 생성합니다.
? 시각적 맥락을 바탕으로 여러 차례 대화에 참여합니다.
2️⃣ GUI 에이전트 및 향상된 기능(CogAgent-18B):
?️ 시각적 이해 개선을 위해 고해상도 이미지 입력(1120x1120)을 지원합니다.
?? GUI 에이전트 기능을 보유하고 있으며, GUI 스크린샷과 관련된 과제를 수행하고 질문에 답변합니다.
? 특화된 교육을 통해 OCR 관련 기능을 개선합니다.
3️⃣ 그라운딩 및 다중 대화 모드:
? 개체의 경계 상자 좌표를 포함한 이미지 설명을 제공합니다.
? 개체 설명을 기반으로 경계 상자 좌표를 검색합니다.
? 지정된 경계 상자 좌표에서 설명을 생성합니다.
사용 사례:
? 자연어 시각적 추론: CogVLM과 CogAgent는 이미지 캡션, 시각적 질문 답변 및 그라운딩 과제와 같이 시각적 이해와 언어 생성이 필요한 과제에서 뛰어납니다.
? GUI 상호 작용 및 자동화: CogAgent의 GUI 에이전트 기능은 웹 페이지, 애플리케이션, 소프트웨어와 같은 GUI 스크린샷과의 상호 작용이 관련된 과제에 적합합니다.
? 시각적 맥락을 바탕으로 한 질문 답변: 두 모델 모두 이미지와 관련된 질문에 답변할 수 있으며, 시각적 맥락에 대한 이해를 활용한 유익한 응답을 제공합니다.
? 시각적 입력을 바탕으로 한 언어 생성: CogVLM과 CogAgent는 이미지를 제공받으면 시각적 컨텐츠와 일관성 있는 자세한 설명, 스토리 또는 대화를 생성할 수 있습니다.
결론:
CogVLM과 CogAgent는 이미지 이해, 여러 차례 대화, GUI 에이전트 기능을 결합한 다목적 시각적 언어 모델입니다. 강력한 기능 덕분에 자연어 기반 시각적 추론, GUI 상호 작용 및 자동화, 시각적 맥락을 바탕으로 한 질문 답변, 시각적 입력을 바탕으로 한 언어 생성 등 다양한 애플리케이션에 귀중한 자산이 됩니다.
More information on CogVLM & CogAgent
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
CogVLM & CogAgent was manually vetted by our editorial team and was first featured on 2024-01-28.
Related Searches




