
What is LLM Outputs?
LLM Outputsは、リアルタイム監視とシームレスな統合を提供することで、AI生成の構造化データの完全性を革命的に変革し、幻覚を検出、排除します。これにより、お客様が依存するデータは、正確で信頼性が高いだけでなく、文脈的に関連性があることが保証されます。LLM Outputsは、エラーや捏造を防ぐことで、運用効率とデータの信頼性を高め、大規模言語モデルを活用するあらゆる組織にとって不可欠なツールになります。
主な機能:
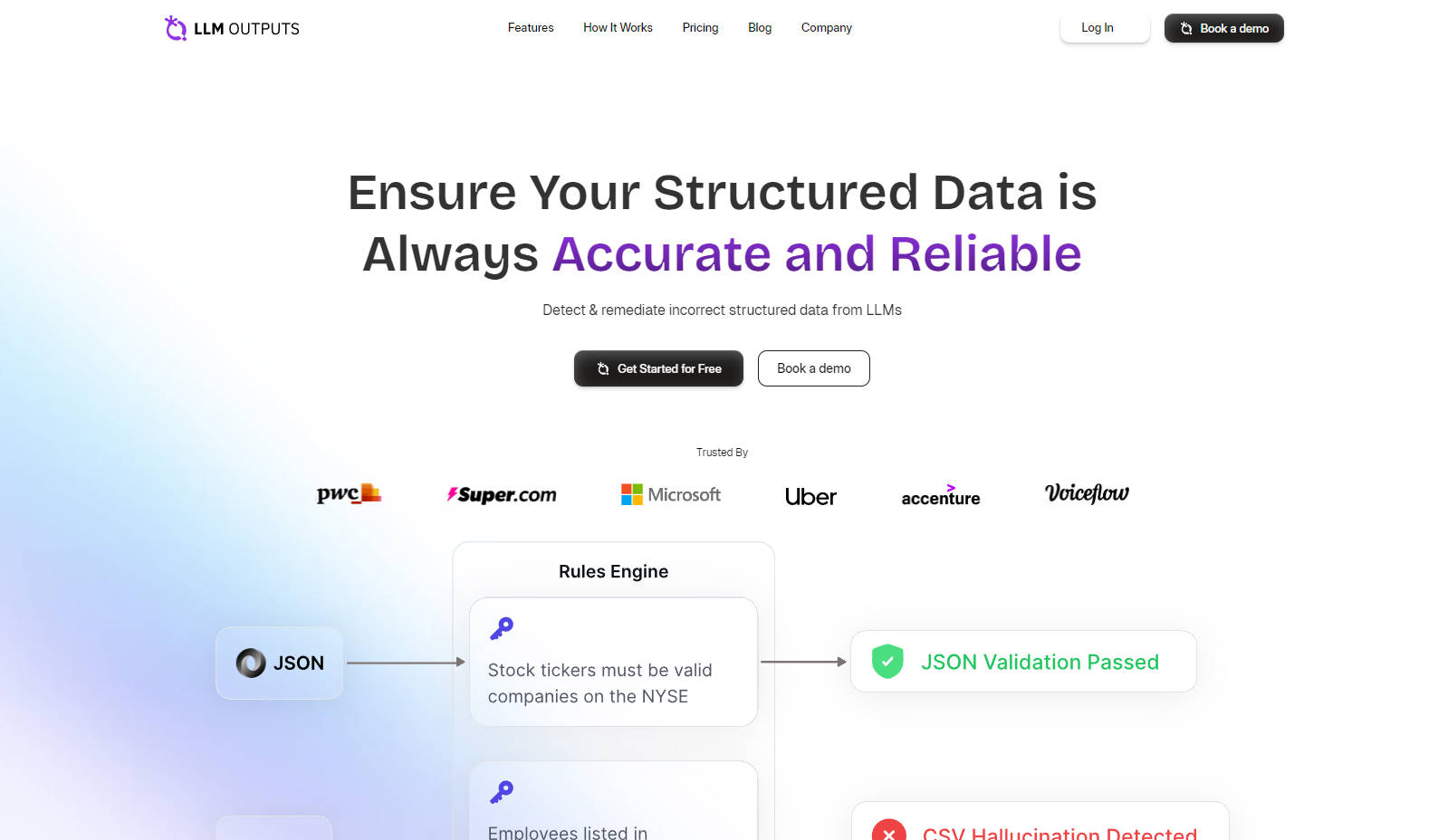
フォーマット適合性: JSON、CSV、XMLなど、指定されたフォーマットに構造化データが常に準拠することを保証し、フォーマットエラーを根絶します。
幻覚検出: 独自のAIモデルを採用して、構造化データの幻覚を特定し、修正することで、データの完全性を維持します。
文脈的正確性: 適切な文脈に合わせて、意図した用途に合わせたデータの関連性と精度を維持します。
シームレスな統合: 開発者フレンドリーなアプローチで、既存のシステムに迅速に統合できるコードスニペットを簡単に注入できます。
リアルタイム監視: 低レイテンシAPIを提供し、構造化データの差異を即座に検出、修正します。
ユースケース:
AIデータの完全性: AIモデルのトレーニングに使用されるデータの正確性を確保し、パフォーマンスと信頼性を向上させます。
金融データの検証: 高額なミスやコンプライアンスの問題につながる可能性のある、誤った金融データから保護します。
エンタープライズデータパイプライン: 大規模組織におけるデータワークフローを合理化し、構造化データをリアルタイムで検証します。
結論:
LLM Outputsは、構造化データの精度を維持するためのベンチマークであり、組織に既存のワークフローにシームレスに統合される革新的なソリューションを提供します。リアルタイム検証の力により、これまで以上にデータの信頼性を高めることができます。データの精度を向上させたいですか?LLM Outputsを今すぐ無料で試して、構造化データの管理方法を変革しましょう。
よくある質問:
Q: 構造化データにおける幻覚とは何ですか?なぜ検出することが重要なのでしょうか?
A:構造化データにおける幻覚とは、AIモデルによって不正確さや捏造が導入されることです。このような幻覚は、データの信頼性を損ない、誤った意思決定につながる可能性があるため、検出することが重要です。LLM Outputsは、データの完全性を維持するために、このような問題を特定することに特化しています。
Q: LLM Outputsはどのように既存のシステムに統合されますか?
A:LLM Outputsは、ワークフローに注入できるコードスニペットを提供することで、現在のシステムにシームレスに統合されます。これは、お客様のツールと連携して構造化データを検証し、運用を中断することなく精度を保証します。
Q: LLM Outputsの幻覚検出モデルが優れているのはなぜですか?
A:LLM Outputsは、構造化データにおける幻覚の検出と排除のために微調整された最先端のAIテクノロジーを採用しています。そのモデルは、AI生成コンテンツにおけるデータ検証の新しい基準を設定し、一貫した精度と信頼性を保証する上で他に類を見ません。
More information on LLM Outputs
Launched
2024-08
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Google Analytics,Google Tag Manager,Webflow,Amazon AWS CloudFront,Google Fonts,jQuery,Gzip,OpenGraph,HSTS
LLM Outputs was manually vetted by our editorial team and was first featured on 2024-09-09.
Related Searches
LLM Outputs 代替ソフト
もっと見る 代替ソフト-

Deepchecks: LLM評価を網羅するプラットフォーム。 AIアプリを開発から本番まで、体系的にテスト、比較、監視します。ハルシネーションを抑制し、迅速な提供を実現。
-

-

-

-
