
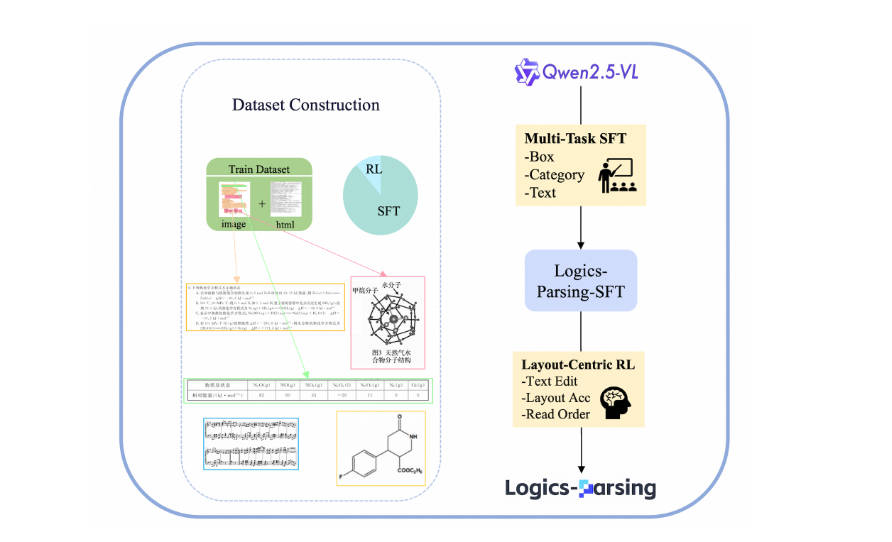
What is Logics-Parsing?
Logics-Parsingは、汎用VLM(Vision-Language Model)を基盤とし、教師ありファインチューニング(SFT)と強化学習(RL)を通じて構築された、強力なエンドツーエンドの文書解析モデルです。非常に複雑な文書を正確に分析し、構造化する能力に優れています。
主な特徴
シームレスなエンドツーエンド処理
単一モデルアーキテクチャにより、複雑な多段階パイプラインが不要です。文書画像から直接、構造化された出力が得られるため、デプロイメントと推論が簡単に行えます。
複雑なレイアウトの文書においても卓越したパフォーマンスを発揮します。
高度なコンテンツ認識
複雑な科学式を含む難解なコンテンツを正確に認識し、構造化します。
化学構造をインテリジェントに識別し、標準の SMILES 形式で表現できます。
豊富で構造化されたHTML出力
モデルは文書の論理構造を保持した、クリーンなHTML表現を生成します。
各コンテンツブロック(例:段落、表、図、式)には、その カテゴリ、 バウンディングボックス座標、および OCRテキスト がタグ付けされます。
ヘッダーやフッターなどの無関係な要素を自動的に識別して除外し、主要なコンテンツのみに焦点を当てます。
最先端のパフォーマンス
Logics-Parsingは、複雑なレイアウトの文書やSTEMコンテンツにおけるモデルの解析能力を包括的に評価するために特別に設計された、当社の社内ベンチマークにおいて最高のパフォーマンスを達成しています。
More information on Logics-Parsing
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Logics-Parsing was manually vetted by our editorial team and was first featured on 2025-10-03.
Logics-Parsing 代替ソフト
もっと見る 代替ソフト-

LlamaParseは、複雑なドキュメントからのデータを大規模言語モデル(LLM)に供給するためのソリューションです。テーブルやチャートなどを処理し、カスタム解析、多言語対応、簡単なAPI統合を提供し、SOC 2に準拠しています。
-

Parse Extract: LLMパイプライン向けの高度なデータ抽出とOCR。 複雑なドキュメントやウェブデータを、クリーンでLLMに最適なテキストへと変換します。 費用対効果に優れ、高いセキュリティを実現します。
-

-

-
