
What is Logics-Parsing?
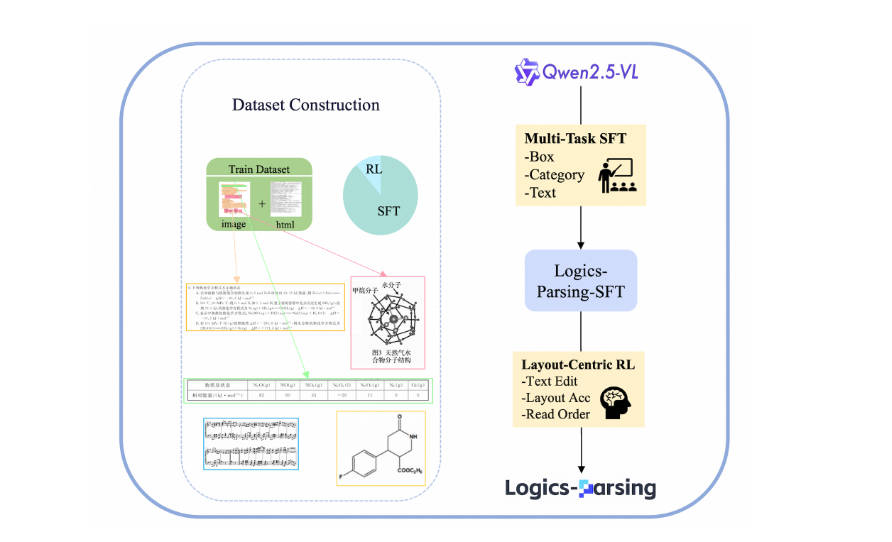
Logics-Parsing is a powerful, end-to-end document parsing model built upon a general Vision-Language Model (VLM) through Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL). It excels at accurately analyzing and structuring highly complex documents.
Key Features
Effortless End-to-End Processing
Our single-model architecture eliminates the need for complex, multi-stage pipelines. Deployment and inference are straightforward, going directly from a document image to structured output.
It demonstrates exceptional performance on documents with challenging layouts.
Advanced Content Recognition
It accurately recognizes and structures difficult content, including intricate scientific formulas.
Chemical structures are intelligently identified and can be represented in the standard SMILES format.
Rich, Structured HTML Output
The model generates a clean HTML representation of the document, preserving its logical structure.
Each content block (e.g., paragraph, table, figure, formula) is tagged with its category, bounding box coordinates, and OCR text.
It automatically identifies and filters out irrelevant elements like headers and footers, focusing only on the core content.
State-of-the-Art Performance
Logics-Parsing achieves the best performance on our in-house benchmark, which is specifically designed to comprehensively evaluate a model’s parsing capability on complex-layout documents and STEM content.
More information on Logics-Parsing
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Logics-Parsing was manually vetted by our editorial team and was first featured on 2025-10-03.
Logics-Parsing Alternatives
Load more Alternatives-

LlamaParse is the solution for feeding LLMs with data from complex documents. It handles tables, charts, and more, offers custom parsing, multi - language support, easy API integration, and is SOC 2 compliant.
-

Parse Extract: Advanced data extraction & OCR for LLM pipelines. Transform complex documents & web data into clean, LLM-ready text. Cost-efficient & secure.
-

-

-
