
What is RagMetrics?
信頼性と効果の高いLLM(大規模言語モデル)を活用したアプリケーションの構築には、特有の課題が伴います。客観的にパフォーマンスを測定し、異なるモデルやプロンプトを比較し、アプリケーションが一貫して高品質の結果を提供することをどのように保証すればよいのでしょうか。LLMの出力を手動で評価する方法は時間がかかり、アプリケーションの成長に合わせて拡張できません。LLMアプリケーションが提供する価値を検証し、反復し、証明するための体系的な方法が必要です。
RagMetricsは、データに基づいた洞察を活用して、LLMアプリケーションの評価、監視、改善を支援する専用プラットフォームを提供します。成功指標の定義、テストの自動化、アプローチの比較、そして展開前後のアプリケーションのパフォーマンスに対する信頼を得るためのツールを提供します。
主な機能:
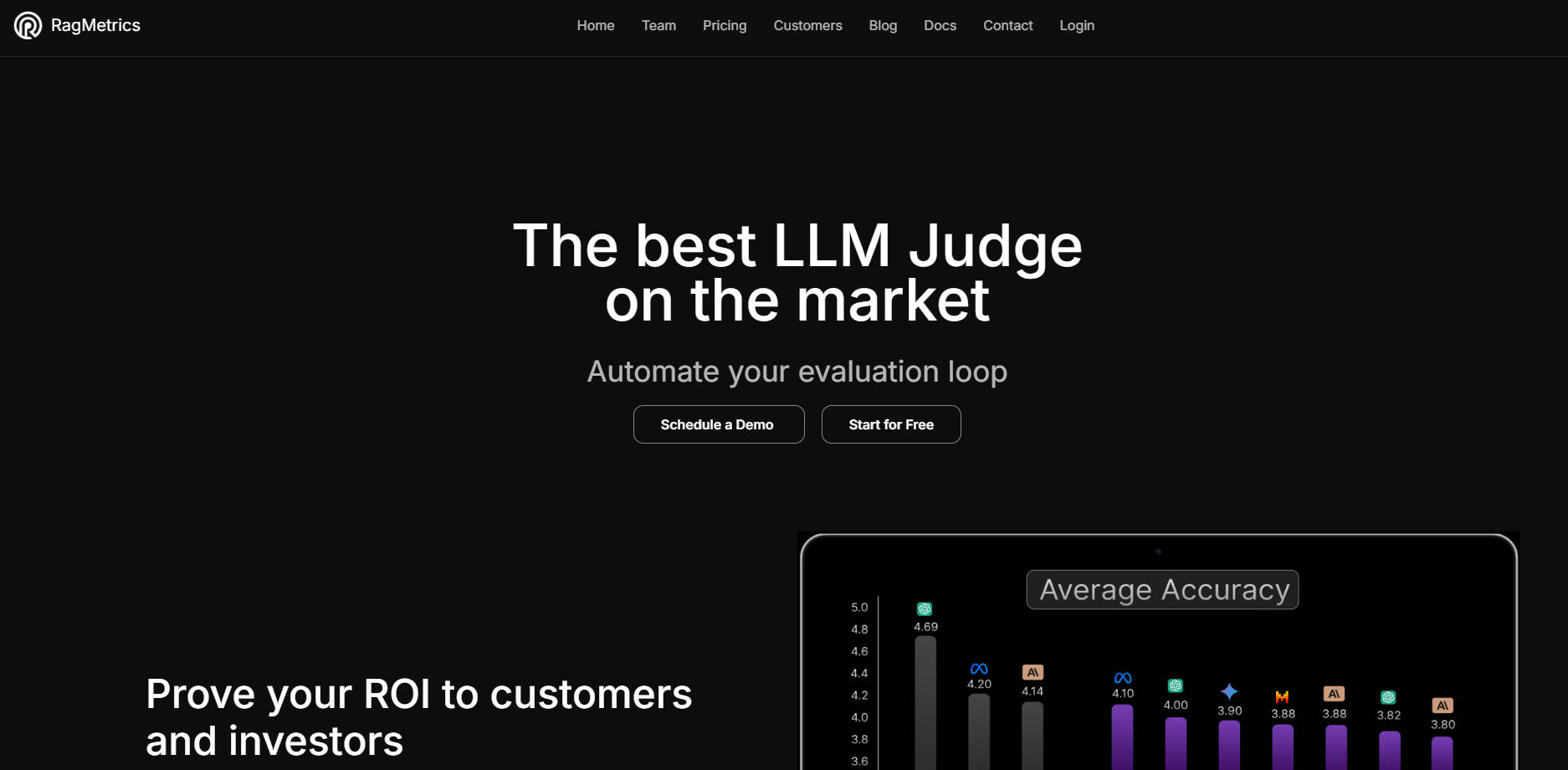
🤖 高度なLLM Judge: 人間の評価との一致率95%を誇る当社のLLM Judgeを活用することで、絶え間ない手動監視なしに、構造化されていないテキスト出力の評価を大規模に自動化できます。
📊 カスタムパフォーマンス指標: アプリケーションのユースケースに特有の指標に基づいて成功を定義し、測定することで、汎用的なランキングにとらわれず、ユーザーとビジネス目標にとって本当に重要なことに焦点を当てることができます。
🔬 A/Bテストフレームワーク: モデル、プロンプト、エージェント、検索戦略など、LLMパイプラインのさまざまなコンポーネントを構造化されたA/Bテストで試すことで、直感だけでなくデータに基づいて改善点を特定できます。
🔍 検索最適化ツール: 関連性の高いコンテキストのソースが重要なアプリケーション向けに、検索メカニズムの評価と改善を支援するように設計されたツールにアクセスし、RAGシステムの重要な課題に対処します。
🔄 自動評価ループ: 合成ラベル付きデータを生成し、LLM Judgeを使用して継続的な自動評価プロセスを作成することで、反復サイクルを加速し、本番環境への移行時間を短縮します。
🤝 広範な互換性: 主要な商用およびオープンソースLLMすべてとシームレスに連携し、既存のコードベースと直接統合することで、開発環境の柔軟性と制御を維持します。
📈 詳細な分析: 回答の質、レイテンシー、コストなど、複数の側面からLLMアプリケーションのパフォーマンスに関する洞察を得ることで、情報に基づいたトレードオフを行うことができます。
ユースケース:
新しいタスクのためのモデルの比較: 新しいカスタマーサポートチャットボットを開発しており、GPT-4o、Llama 3、およびファインチューニングされたオープンソースモデルの中からどれを選択するかを決定する必要があります。RagMetricsを使用して、評価基準(例:精度、有用性、簡潔さ)を定義し、各モデルで代表的なデータセットを使用した実験を実行し、詳細な結果を分析して、特定のニーズに最適なモデルを選択します。
RAGパイプラインの最適化: ナレッジベースのQ&Aシステムが、関連性のない情報を取得することがあります。RagMetricsでA/Bテストを設定し、現在の検索戦略(例:基本的な埋め込み検索)を代替戦略(例:リランキングまたはHyDEの使用)と比較します。コンテキストの関連性や回答の精度などの指標を使用して両方のアプローチを評価し、パフォーマンスを大幅に向上させる方法を特定します。
本番アプリケーションの監視と改善: LLMアプリケーションを展開した後、コードに単純なロギングを追加してRagMetricsを統合します。LLM Judgeを使用して、事前定義された基準に基づいて受信したユーザーインタラクションを自動的に評価するためのレビューキューを作成します。監視データを使用して、ハルシネーションなどの潜在的な問題を特定し、特定のトレースに関する人間のフィードバックを収集して、評価基準とアプリケーション自体を継続的に改善します。
結論:
RagMetricsは、LLMアプリケーションを効果的に開発、監視、および強化するための不可欠なフレームワークを提供します。評価の自動化、データに基づいた実験の実現、および詳細なパフォーマンスの洞察を提供することで、より信頼性の高いアプリケーションを構築し、開発サイクルを加速し、LLMソリューションが利害関係者に提供する価値を明確に示すことができます。
よくある質問:
LLMアプリケーションをRagMetricsに接続するにはどうすればよいですか? コード不要の実験にはWebインターフェース経由で接続するか、Python API(PullまたはPush)を使用して既存のコードベースと直接統合し、プログラムで評価をトリガーできます。
評価にはどのような種類のデータが必要ですか? 独自のラベル付きデータセット(質問、回答、コンテキスト)をアップロードしたり、参照ドキュメント(WebサイトやPDFなど)からデータセットを生成したり、プラットフォーム内でデータポイントを手動で作成したりできます。
RAGシステムの検索コンポーネントを評価できますか? はい、RagMetricsは、RAGパイプラインで取得されたコンテキストの品質と関連性を評価するために設計された特定の評価基準とツールを提供します。
自動評価はどのように機能しますか? RagMetricsは、定義した基準に基づいて応答を自動的に評価するために、「Judge」として構成された高度なLLMを利用します。このプロセスには、生成された回答と正解の比較、およびコンテキストの検索の評価が含まれます。
RagMetricsは、さまざまなLLMプロバイダーと互換性がありますか? はい、RagMetricsは、幅広い商用モデル(OpenAI、Geminiなど)およびオープンソースモデルと連携するように設計されており、さまざまなプロバイダー間で評価および比較できます。
More information on RagMetrics
Launched
2024-03
Pricing Model
Freemium
Starting Price
$750 / month
Global Rank
13055353
Follow
Month Visit
<5k
Tech used
cdnjs,Google Fonts
Top 5 Countries
89.72%
10.28%
United States
India
Traffic Sources
9.23%
1.3%
0.07%
5.99%
15.1%
68.24%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 25, 2025)
RagMetrics was manually vetted by our editorial team and was first featured on 2025-05-25.
Related Searches
RagMetrics 代替ソフト
もっと見る 代替ソフト-

-

-

Deepchecks: LLM評価を網羅するプラットフォーム。 AIアプリを開発から本番まで、体系的にテスト、比較、監視します。ハルシネーションを抑制し、迅速な提供を実現。
-

-
