
What is RagMetrics?
Building reliable and effective LLM-powered applications presents unique challenges. How do you objectively measure performance, compare different models or prompts, and ensure your application delivers consistent, high-quality results? Manually evaluating LLM outputs is time-consuming and doesn't scale as your application grows. You need a systematic way to test, iterate, and prove the value your LLM application provides.
RagMetrics offers a dedicated platform to help you evaluate, monitor, and improve your LLM applications with data-driven insights. It provides the tools to define success metrics, automate testing, compare approaches, and gain confidence in your application's performance before and after deployment.
Key Features:
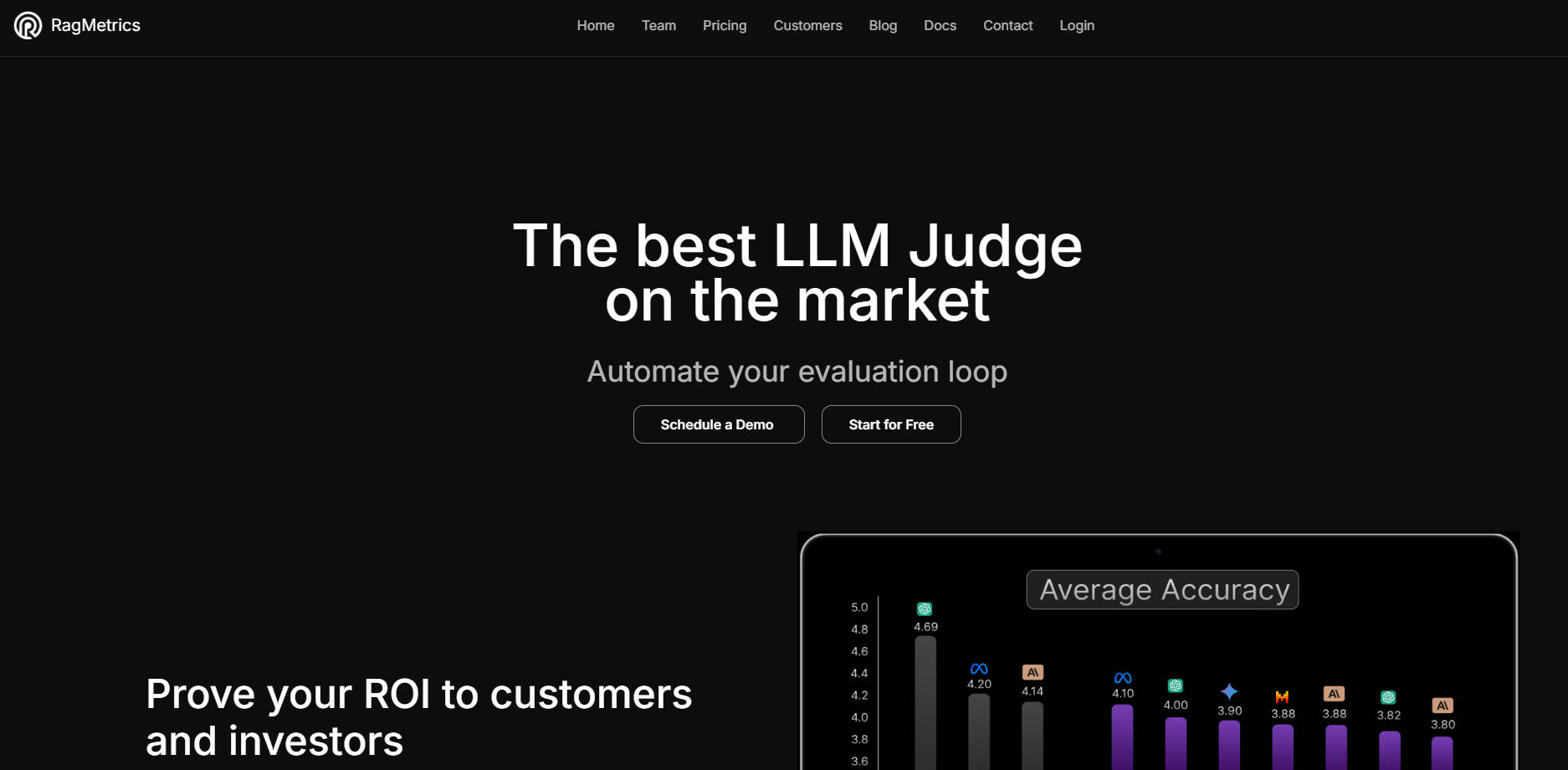
🤖 Advanced LLM Judge: Leverage our LLM judge, demonstrating 95% agreement with human evaluations, allowing you to automate the assessment of unstructured text outputs at scale without constant manual oversight.
📊 Custom Performance Metrics: Define and measure success based on metrics specific to your application's use case, moving beyond generic leaderboards to focus on what truly matters for your users and business goals.
🔬 A/B Testing Frameworks: Experiment with different components of your LLM pipeline – including models, prompts, agents, and retrieval strategies – using structured A/B tests to identify improvements based on data, not just intuition.
🔍 Retrieval Optimization Tools: For applications where sourcing relevant context is critical, access tools designed to help you evaluate and improve your retrieval mechanisms, addressing a key challenge in RAG systems.
🔄 Automated Evaluation Loop: Generate synthetic labeled data and use LLM judges to create a continuous, automated evaluation process, accelerating your iteration cycles and speeding up time to production.
🤝 Broad Compatibility: Works seamlessly with all major commercial and open-source LLMs and integrates directly with your existing codebase, preserving flexibility and control over your development environment.
📈 Detailed Analytics: Gain insights into the performance of your LLM application across multiple dimensions, including answer quality, latency, and cost, enabling you to make informed tradeoffs.
Use Cases:
Comparing Models for a New Task: You're developing a new customer support chatbot and need to decide between GPT-4o, Llama 3, and a fine-tuned open-source model. Use RagMetrics to define evaluation criteria (e.g., accuracy, helpfulness, conciseness), run experiments with each model on a representative dataset, and analyze the detailed results to select the best-performing model for your specific needs.
Optimizing a RAG Pipeline: Your knowledge base Q&A system is sometimes retrieving irrelevant information. Set up an A/B test in RagMetrics comparing your current retrieval strategy (e.g., basic embedding search) against an alternative (e.g., using reranking or HyDE). Evaluate both approaches using metrics like context relevance and answer accuracy to identify which method significantly improves performance.
Monitoring and Improving a Production Application: After deploying your LLM application, integrate RagMetrics by adding simple logging to your code. Create review queues to automatically evaluate incoming user interactions based on predefined criteria using LLM judges. Use the monitoring data to identify potential issues like hallucinations and collect human feedback on specific traces to continuously improve your evaluation criteria and the application itself.
Conclusion:
RagMetrics provides the essential framework for developing, monitoring, and enhancing LLM applications effectively. By automating evaluation, enabling data-driven experimentation, and offering deep performance insights, it helps you build more reliable applications, accelerate your development cycles, and clearly demonstrate the value your LLM solutions deliver to stakeholders.
FAQ:
How do I connect my LLM application to RagMetrics? You can connect via a web interface for no-code experiments or use our Python API (Pull or Push) to integrate directly with your existing codebase and trigger evaluations programmatically.
What kind of data is needed for evaluation? You can upload your own labeled datasets (Question, Answer, Context), generate datasets from reference documents (like a website or PDF), or manually create data points within the platform.
Can I evaluate the retrieval component of my RAG system? Yes, RagMetrics provides specific evaluation criteria and tools designed to assess the quality and relevance of retrieved contexts in your RAG pipelines.
How does the automated evaluation work? RagMetrics utilizes advanced LLMs, configured as "judges," to automatically evaluate responses based on the criteria you define. This process includes comparing generated answers to ground truth and assessing context retrieval.
Is RagMetrics compatible with different LLM providers? Yes, RagMetrics is designed to work with a wide range of commercial models (like OpenAI, Gemini) and open-source models, allowing you to evaluate and compare across different providers.
More information on RagMetrics
Launched
2024-03
Pricing Model
Freemium
Starting Price
$750 / month
Global Rank
13055353
Follow
Month Visit
<5k
Tech used
cdnjs,Google Fonts
Top 5 Countries
89.72%
10.28%
United States
India
Traffic Sources
9.23%
1.3%
0.07%
5.99%
15.1%
68.24%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 25, 2025)
RagMetrics was manually vetted by our editorial team and was first featured on 2025-05-25.
Related Searches
RagMetrics Alternatives
Load more Alternatives-

-

Companies of all sizes use Confident AI justify why their LLM deserves to be in production.
-

Deepchecks: The end-to-end platform for LLM evaluation. Systematically test, compare, & monitor your AI apps from dev to production. Reduce hallucinations & ship faster.
-

-
