
What is RagMetrics?
构建可靠且高效的基于 LLM 的应用程序面临着独特的挑战。 如何客观地衡量性能、比较不同的模型或提示,并确保您的应用程序提供一致的高质量结果? 手动评估 LLM 输出既耗时,也无法随着应用程序的增长而扩展。 您需要一种系统的方法来测试、迭代并证明您的 LLM 应用程序提供的价值。
RagMetrics 提供了一个专门的平台,通过数据驱动的洞察力来帮助您评估、监控和改进您的 LLM 应用程序。 它提供了定义成功指标、自动化测试、比较方法以及在部署前后获得对应用程序性能信心的工具。
主要特性:
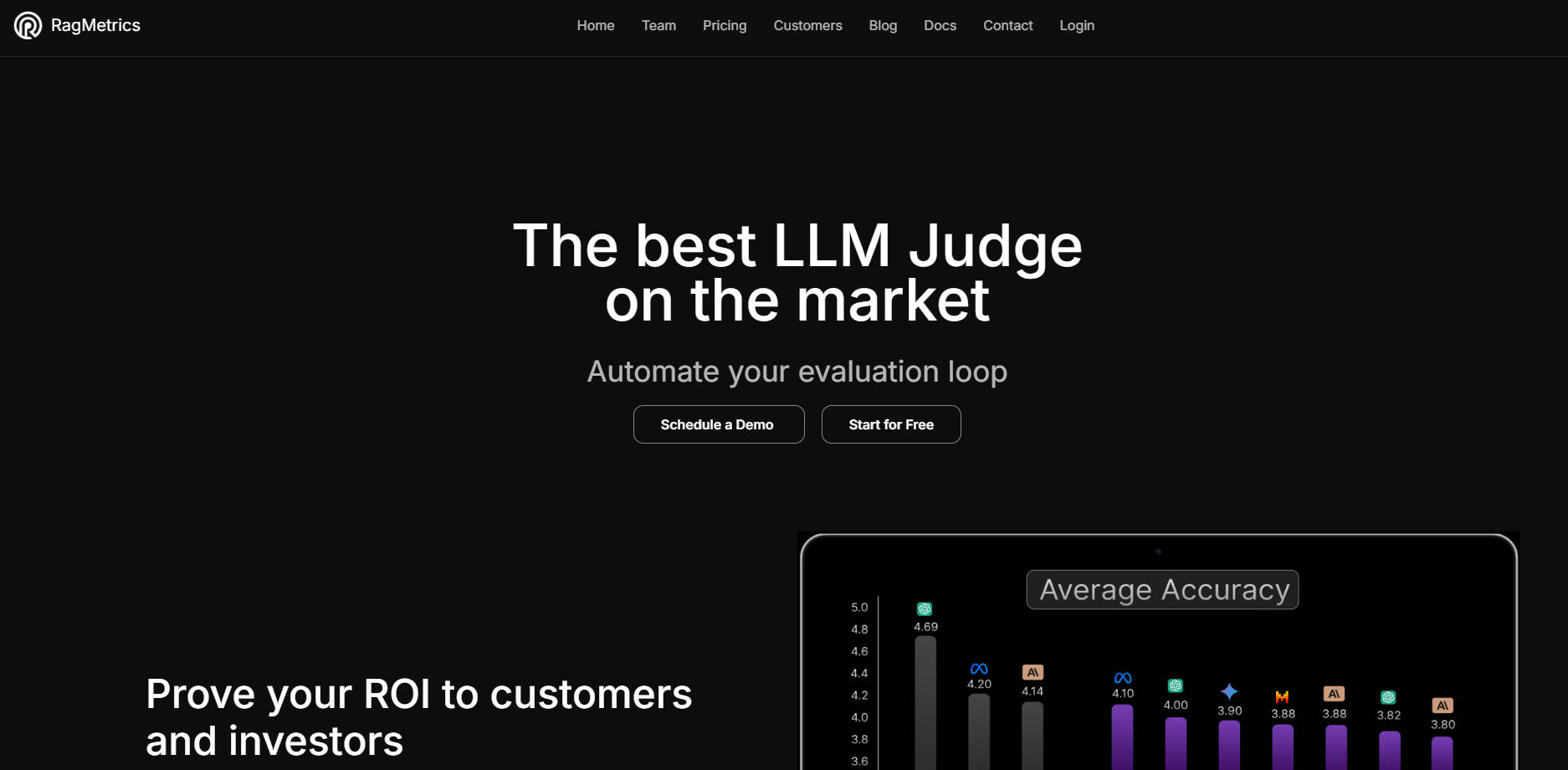
🤖 高级 LLM Judge: 利用我们的 LLM Judge,其评估结果与人工评估的吻合度高达 95%,使您能够大规模地自动评估非结构化文本输出,而无需持续的人工监督。
📊 自定义性能指标: 根据特定于您的应用程序用例的指标来定义和衡量成功,超越通用的排行榜,专注于对您的用户和业务目标真正重要的事情。
🔬 A/B 测试框架: 使用结构化的 A/B 测试来试验 LLM 管道的不同组件(包括模型、提示、代理和检索策略),以基于数据(而不仅仅是直觉)来识别改进。
🔍 检索优化工具: 对于需要获取相关上下文至关重要的应用程序,可以使用旨在帮助您评估和改进检索机制的工具,从而解决 RAG 系统中的一个关键挑战。
🔄 自动化评估循环: 生成合成的带标签数据,并使用 LLM Judge 创建一个连续的自动化评估过程,从而加速您的迭代周期并缩短上市时间。
🤝 广泛的兼容性: 与所有主要的商业和开源 LLM 无缝协作,并直接与您现有的代码库集成,从而保持灵活性并控制您的开发环境。
📈 详细的分析: 深入了解您的 LLM 应用程序在多个维度(包括答案质量、延迟和成本)上的性能,从而使您能够做出明智的权衡。
使用场景:
比较新任务的模型: 您正在开发一个新的客户支持聊天机器人,并且需要在 GPT-4o、Llama 3 和微调的开源模型之间做出决定。 使用 RagMetrics 定义评估标准(例如,准确性、有用性、简洁性),在代表性数据集上使用每个模型运行实验,并分析详细结果,以选择最适合您特定需求的模型。
优化 RAG 管道: 您的知识库问答系统有时会检索到不相关的信息。 在 RagMetrics 中设置 A/B 测试,将您当前的检索策略(例如,基本嵌入搜索)与替代策略(例如,使用重新排序或 HyDE)进行比较。 使用上下文相关性和答案准确性等指标评估这两种方法,以确定哪种方法可以显着提高性能。
监控和改进生产应用程序: 部署您的 LLM 应用程序后,通过向您的代码添加简单的日志记录来集成 RagMetrics。 创建审查队列,以使用 LLM Judge 根据预定义的标准自动评估传入的用户交互。 使用监控数据来识别潜在问题(如幻觉),并收集有关特定跟踪的人工反馈,以不断改进您的评估标准和应用程序本身。
结论:
RagMetrics 提供了一个基本的框架,用于有效地开发、监控和增强 LLM 应用程序。 通过自动化评估、启用数据驱动的实验以及提供深入的性能洞察,它可以帮助您构建更可靠的应用程序、加速您的开发周期,并清楚地向利益相关者展示您的 LLM 解决方案提供的价值。
常见问题解答:
如何将我的 LLM 应用程序连接到 RagMetrics? 您可以通过 Web 界面进行无代码实验进行连接,或者使用我们的 Python API(Pull 或 Push)直接与您现有的代码库集成并以编程方式触发评估。
评估需要什么样的数据? 您可以上传您自己的带标签数据集(问题、答案、上下文),从参考文档(如网站或 PDF)生成数据集,或者在平台内手动创建数据点。
我可以评估我的 RAG 系统的检索组件吗? 可以,RagMetrics 提供了专门的评估标准和工具,旨在评估您的 RAG 管道中检索到的上下文的质量和相关性。
自动化评估如何工作? RagMetrics 利用配置为“Judge”的高级 LLM,根据您定义的标准自动评估响应。 此过程包括将生成的答案与基本事实进行比较以及评估上下文检索。
RagMetrics 是否与不同的 LLM 提供商兼容? 是的,RagMetrics 旨在与各种商业模型(如 OpenAI、Gemini)和开源模型一起使用,从而使您能够跨不同的提供商进行评估和比较。
More information on RagMetrics
Top 5 Countries
89.72%
10.28%
United States
India
Traffic Sources
9.23%
1.3%
0.07%
5.99%
15.1%
68.24%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 25, 2025)
RagMetrics was manually vetted by our editorial team and was first featured on 2025-05-25.
Related Searches




