
Click outside to close
What is RagMetrics?
打造可靠且高效的 LLM 驅動應用程式,面臨著獨特的挑戰。您如何客觀地衡量效能、比較不同的模型或提示,並確保您的應用程式提供一致、高品質的結果?手動評估 LLM 輸出既耗時又難以隨著應用程式的成長而擴展。您需要一個系統化的方法來測試、迭代,並證明您的 LLM 應用程式所提供的價值。
RagMetrics 提供了一個專用的平台,協助您透過數據驅動的洞察,評估、監控和改善您的 LLM 應用程式。它提供各種工具,讓您定義成功指標、自動化測試、比較方法,並在部署前後對應用程式的效能充滿信心。
主要特色:
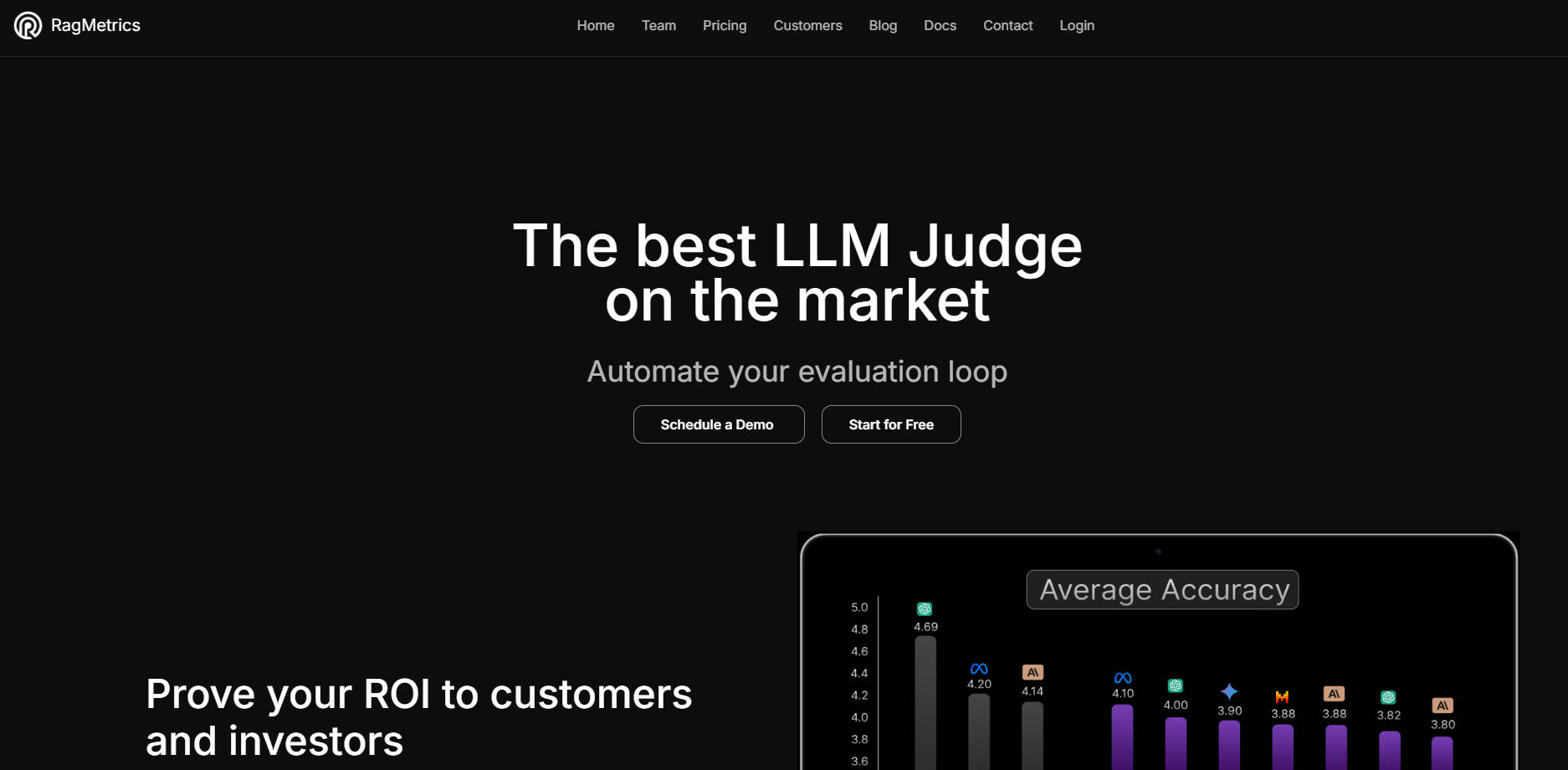
🤖 Advanced LLM Judge(進階 LLM 評審): 運用我們的 LLM 評審,其評估結果與人類評估的吻合度高達 95%,讓您能夠大規模自動評估非結構化文字輸出,而無需持續的人工監督。
📊 Custom Performance Metrics(自訂效能指標): 根據您的應用程式使用案例所特定的指標來定義和衡量成功,超越通用的排行榜,專注於對您的使用者和業務目標真正重要的事物。
🔬 A/B Testing Frameworks(A/B 測試架構): 使用結構化的 A/B 測試來實驗 LLM 流程的不同組件(包括模型、提示、代理和檢索策略),以根據數據(而不僅僅是直覺)來找出改善之處。
🔍 Retrieval Optimization Tools(檢索優化工具): 對於那些來源關聯情境至關重要的應用程式,可以使用專為協助您評估和改善檢索機制而設計的工具,解決 RAG 系統中的一個關鍵挑戰。
🔄 Automated Evaluation Loop(自動化評估迴圈): 產生合成的標記資料,並使用 LLM 評審來建立一個持續、自動化的評估流程,加速您的迭代週期並縮短上市時間。
🤝 Broad Compatibility(廣泛的相容性): 與所有主要的商業和開源 LLM 無縫協作,並直接與您現有的程式碼庫整合,從而保留您對開發環境的彈性和控制。
📈 Detailed Analytics(詳細的分析): 深入了解您的 LLM 應用程式在多個維度上的效能,包括答案品質、延遲和成本,讓您能夠做出明智的權衡。
使用案例:
Comparing Models for a New Task(比較新任務的模型): 您正在開發一個新的客戶支援聊天機器人,需要在 GPT-4o、Llama 3 和一個經過微調的開源模型之間做出選擇。使用 RagMetrics 來定義評估標準(例如,準確性、幫助性、簡潔性),在具代表性的資料集上對每個模型進行實驗,並分析詳細的結果,以選擇最適合您特定需求的模型。
Optimizing a RAG Pipeline(優化 RAG 流程): 您的知識庫問答系統有時會檢索到不相關的資訊。在 RagMetrics 中設定一個 A/B 測試,將您目前的檢索策略(例如,基本的嵌入搜尋)與另一種策略(例如,使用重新排序或 HyDE)進行比較。使用情境相關性和答案準確性等指標來評估這兩種方法,以確定哪種方法可以顯著提高效能。
Monitoring and Improving a Production Application(監控和改善生產應用程式): 在部署您的 LLM 應用程式後,透過將簡單的日誌記錄新增到您的程式碼中來整合 RagMetrics。建立審查佇列,以使用 LLM 評審根據預定義的標準自動評估傳入的使用者互動。使用監控數據來識別潛在問題(如幻覺),並收集關於特定追蹤的人工回饋,以持續改善您的評估標準和應用程式本身。
結論:
RagMetrics 提供了一個重要的架構,可有效地開發、監控和增強 LLM 應用程式。透過自動化評估、實現數據驅動的實驗,並提供深入的效能洞察,它有助於您建構更可靠的應用程式、加速您的開發週期,並清楚地向利害關係人展示您的 LLM 解決方案所提供的價值。
常見問題:
How do I connect my LLM application to RagMetrics?(如何將我的 LLM 應用程式連接到 RagMetrics?) 您可以透過網路介面進行無程式碼實驗,或使用我們的 Python API(Pull 或 Push)直接與您現有的程式碼庫整合,並以程式化的方式觸發評估。
What kind of data is needed for evaluation?(評估需要什麼樣的資料?) 您可以上傳您自己標記的資料集(問題、答案、情境)、從參考文件(如網站或 PDF)產生資料集,或在平台內手動建立資料點。
Can I evaluate the retrieval component of my RAG system?(我可以評估我的 RAG 系統的檢索組件嗎?) 可以,RagMetrics 提供了特定的評估標準和工具,旨在評估您的 RAG 流程中檢索到的情境的品質和相關性。
How does the automated evaluation work?(自動化評估如何運作?) RagMetrics 利用配置為「評審」的進階 LLM,根據您定義的標準自動評估回應。此流程包括將產生的答案與真實情況進行比較,並評估情境檢索。
Is RagMetrics compatible with different LLM providers?(RagMetrics 與不同的 LLM 提供者相容嗎?) 可以,RagMetrics 旨在與各種商業模型(如 OpenAI、Gemini)和開源模型協作,讓您可以跨不同的提供者進行評估和比較。
More information on RagMetrics
Top 5 Countries
89.72%
10.28%
United States (89.72%)
India (10.28%)
Traffic Sources
9.23%
5.99%
15.1%
68.24%
social (9.23%)
paidReferrals (1.3%)
mail (0.07%)
referrals (5.99%)
search (15.1%)
direct (68.24%)
Source: Similarweb (Sep 25, 2025)
RagMetrics was manually vetted by our editorial team and was first featured on 2025-05-25.
RagMetrics 替代
RagMetrics 替代-

-

-

Deepchecks:大型語言模型(LLM)的端對端評估平台。 從開發到上線,有系統地測試、比較並監控您的AI應用程式。 有效降低幻覺,並加速產品上市。
-

提升您的 LLMs,使用 RAG-FiT:一個模組化的檢索增強生成優化框架。輕鬆微調、評估和部署更聰明的模型。立即探索 RAG-FiT!
-

加速可靠的生成式AI開發。Ragbits 提供模組化、類型安全的建構區塊,適用於大型語言模型 (LLM)、檢索增強生成 (RAG) 及資料管線。加速打造穩固的AI應用程式。