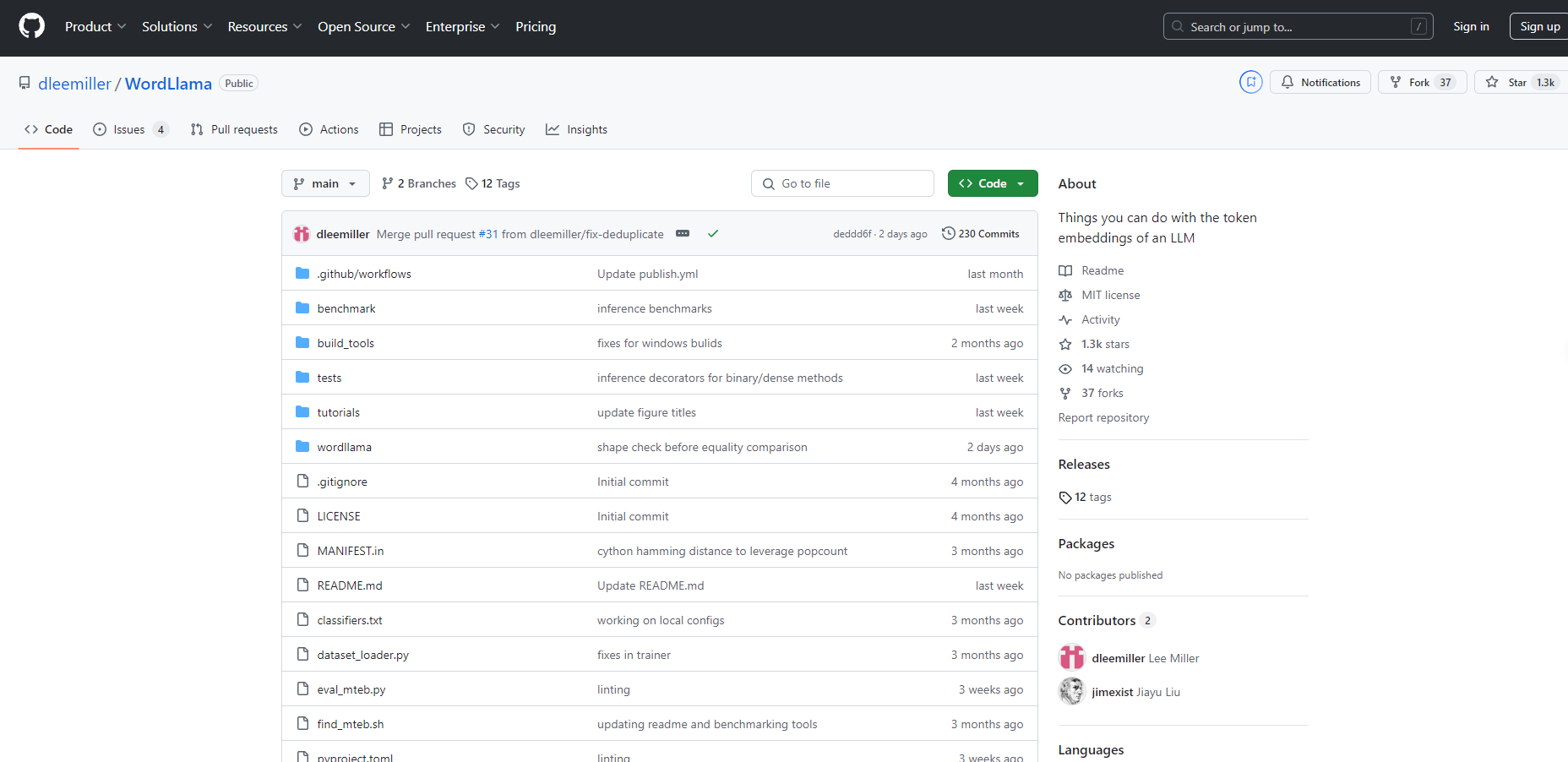
What is WordLlama?
WordLlamaは、CPUハードウェアでのパフォーマンスに最適化された、革新的な自然言語処理(NLP)ツールキットです。最先端の大規模言語モデルのコンポーネントを活用することで、ファジー重複排除、類似度計算、セマンティックテキスト分割などのタスクに適した、コンパクトで効率的な単語表現を作成します。WordLlamaは、軽量設計と低リソース要件により、従来の単語埋め込みを改善しながら、リソース制約のある環境に適した小さなフットプリントを維持しています。
主な機能:
? マトリョーシカ表現: モデルのサイズとパフォーマンスを適応させるために、埋め込み次元を柔軟に切り捨てることができます。
? 低リソース要件: 単純なトークンルックアップと平均プーリングを利用して、GPUを必要とせずにCPUで高速に動作します。
? バイナリ埋め込み: ストレートスルー推定器トレーニングによる高速なハミング距離計算のために、コンパクトな整数配列ストレージを可能にします。
? NumPyのみの推論: 軽量な推論は、NumPyのみに依存するため、簡単に展開および統合できます。
⚡ 汎用性の高いツール: 探索的分析とユーティリティアプリケーション向けに設計されており、LLM出力評価と準備的なNLPタスクを強化します。
ユースケース:
重複検出: WordLlamaは、大規模なドキュメントセット内の重複テキストを効果的に識別して削除し、さらなる分析のためのデータ品質を向上させます。
コンテンツクラスタリング: 大量のテキストデータを意味のあるグループに編成するのに最適で、コンテンツの分類と管理を支援します。
情報検索: クエリとの類似度に基づいてドキュメントをランク付けすることで、検索機能を強化し、情報へのアクセス効率を向上させます。
結論:
WordLlamaは、効率を損なうことなくパフォーマンスを実現する、堅牢でCPUフレンドリーなNLPツールキットとして際立っています。大規模言語モデルコンポーネントをコンパクトなフォームファクターで革新的に使用することで、計算リソースが限られた環境でのNLPタスクに不可欠なツールとなっています。重いインフラストラクチャのオーバーヘッドなしにテキストデータから洞察を得たいユーザーにとって、WordLlamaは最適なソリューションです。
よくある質問:
WordLlamaを実行するためのシステム要件は何ですか?
WordLlamaはCPU使用に最適化されており、ほとんどの最新のプロセッサで実行できます。推論にはGPUは必要ありません。WordLlamaは、GloVeなどの従来の単語埋め込みとどのように比較されますか?
WordLlamaモデルは、サイズが大幅に小さく、展開がより効率的であるため、すべてのMTEBベンチマークでGloVe 300dを上回ります。WordLlamaはリアルタイムのテキスト処理に使用できますか?
はい、高速なシングルコアパフォーマンスと最小限の依存関係により、WordLlamaは、迅速なテキスト分析と処理を必要とするリアルタイムアプリケーションに適しています。
More information on WordLlama
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
WordLlama was manually vetted by our editorial team and was first featured on 2024-10-11.
Related Searches