
Click outside to close
What is Turbopuffer?
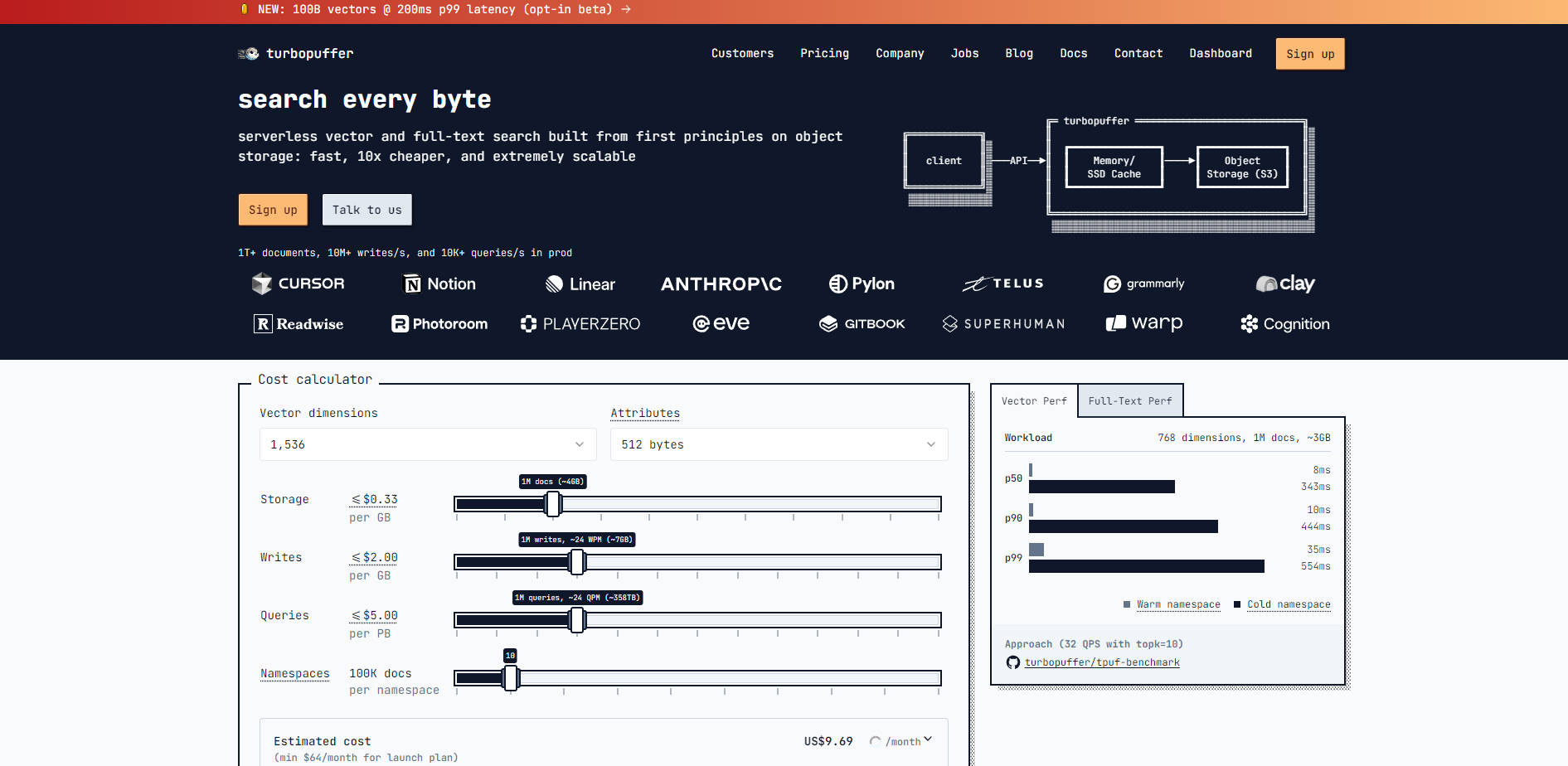
turbopuffer is a high-performance search engine designed for modern enterprise data workloads that demand massive scale without prohibitive infrastructure costs. By uniquely relying on low-cost object storage as its sole stateful dependency, turbopuffer efficiently combines vector and full-text search capabilities, solving the core challenge of maintaining petabyte-scale indices economically. Built specifically for B2B and enterprise customers, this platform delivers reliable, sub-10ms warm latency and supports strong data isolation for multi-tenant environments.
Key Features
turbopuffer is engineered to provide both performance and efficiency by separating compute (NVMe SSD and memory cache) from state (object storage). This architecture allows you to handle billions of documents while keeping costs managed.
🔍 Unified Vector and Full-Text Search
You gain the power of modern hybrid search in a single API call. turbopuffer utilizes a centroid-based Approximate Nearest Neighbour (ANN) index (SPFresh) for vector embeddings and an inverted BM25 index for keyword search. This combination ensures high recall and allows you to generate robust candidate sets for downstream refinement processes, delivering superior relevance out of the box.
☁️ Object Storage Native Architecture
State is managed exclusively in low-cost object storage (like S3 or GCS), allowing the system to scale horizontally to trillions of documents. Compute nodes utilize NVMe SSD and memory cache, caching only actively searched data. This approach significantly lowers storage costs compared to traditional replicated disk systems, even for frequently accessed namespaces.
✅ Strong Consistency and Durability (ACD)
Data integrity and reliability are paramount. turbopuffer provides Atomicity, Consistency, and Durability (ACD) properties. Writes are immediately committed to a Write-Ahead Log (WAL) and are durable upon API return. By default, subsequent queries see the write immediately, ensuring strong consistency essential for reliable applications.
🛡️ Enterprise-Grade Isolation and Security
Designed for B2B multi-tenancy, turbopuffer isolates each client's data within its own namespace prefix on object storage. For high-compliance enterprise needs, we support isolation through single-tenancy clusters, Bring Your Own Cloud (BYOC) deployment into your VPC, and Customer Managed Encryption Keys (CMEK), ensuring you maintain full control over your data encryption keys.
Use Cases
turbopuffer excels in scenarios requiring high throughput, massive scale, and strict data isolation while minimizing total cost of ownership (TCO).
1. Efficient First-Stage Retrieval
When dealing with millions or billions of documents, you need to quickly narrow the scope. Use turbopuffer’s hybrid search to efficiently generate a candidate set of tens or hundreds of relevant results. This capability is crucial for high-scale applications that rely on a second stage of re-ranking or refinement, ensuring the initial search is both fast and comprehensive.
2. Delivering Sub-10ms Latency Workloads
For user-facing applications where search speed directly impacts user experience, turbopuffer enables you to leverage its impressive warm-query performance (p50=8ms). You can implement a strategy of "prewarming" critical namespaces or specific user data segments with a pre-flight query, ensuring that subsequent user interactions only experience the low warm latency.
3. High-Compliance Data Storage and Search
Enterprises handling sensitive information, such as Protected Health Information (PHI), benefit from turbopuffer’s security stack. We support Customer Managed Encryption Keys (CMEK) and undergo SOC 2 Type 2 audits. Customers requiring HIPAA compliance can request a Business Associate Agreement (BAA), providing the necessary framework for secure, compliant data hosting within the region you select.
Why Choose turbopuffer?
turbopuffer's unique architecture provides distinct operational and financial advantages over traditional search and vector databases.
Superior Cost-Effective Performance
turbopuffer is designed to be as fast as in-memory search engines when data is cached (p50 warm latency of 8ms), but far cheaper to operate. By storing the vast majority of your index data in low-cost object storage rather than expensive, replicated disk systems, you drastically reduce your overall storage footprint and infrastructure expenditure.
Optimized for Object Storage Efficiency
Our indexing strategies are fundamentally optimized for cloud storage economics. The centroid-based SPFresh index minimizes the number of random roundtrips and write amplification required during indexing and querying, which are common bottlenecks for graph-based indexes (like HNSW or DiskANN) when interacting with high-latency object storage. This optimization results in faster cold starts and lower operational costs.
Simplified Operations and Reliability
With object storage serving as the sole stateful dependency, system operations and maintenance are significantly simplified. This architecture enhances reliability and high availability (HA), as any query node can instantly serve data for any namespace. Furthermore, the system is engineered to handle heavy writes (appends, updates, and deletes) with high throughput (~10,000+ vectors/sec), ensuring your index remains current and consistent.
Conclusion
turbopuffer delivers the speed and scalability demanded by the most intensive enterprise search applications while fundamentally reducing the total cost of ownership through its object storage-centric design. If you need robust hybrid search, strong consistency, and massive scalability for multi-tenant data, turbopuffer provides the reliable, cost-effective foundation you require.
More information on Turbopuffer
Top 5 Countries
67.9%
17.82%
3.4%
3.01%
United States (67.9%)
India (17.82%)
Vietnam (3.4%)
Pakistan (3.01%)
Denmark (2.36%)
Traffic Sources
53.8%
30.45%
6.76%
7.9%
mail (0.07%)
direct (53.8%)
search (30.45%)
social (6.76%)
referrals (7.9%)
paidReferrals (0.98%)
Source: Similarweb (Jan 4, 2026)
Turbopuffer was manually vetted by our editorial team and was first featured on 2025-11-02.
Turbopuffer Alternatives
Turbopuffer Alternatives-

TopK is a cloud-native database intended for search use cases. It comes with keyword search, vector search, and metadata filtering built-in.
-
OceanBase seekdb is an open-source, AI-native search database that unifies relational, vector, text, JSON and GIS in a single engine, enabling hybrid search and in-database AI workflows.
-

Turso is a database platform that takes the embedded libSQL database engine and makes it suitable for production-scale, distributed applications. It adds capabilities like replication, branching, point-in-time recovery, native vector search, and programmatic management via an API, while retaining the familiar SQLite developer experience.
-

CrateDB: High-performance distributed SQL for real-time analytics, search, & AI. Unify data & get instant insights from massive datasets.
-

TurboSeek is an AI-powered search engine, leveraging Bing API and advanced models. It offers natural language understanding, advanced results, speed, related questions, and open source collaboration. Ideal for research, tech problem-solving and content creation.