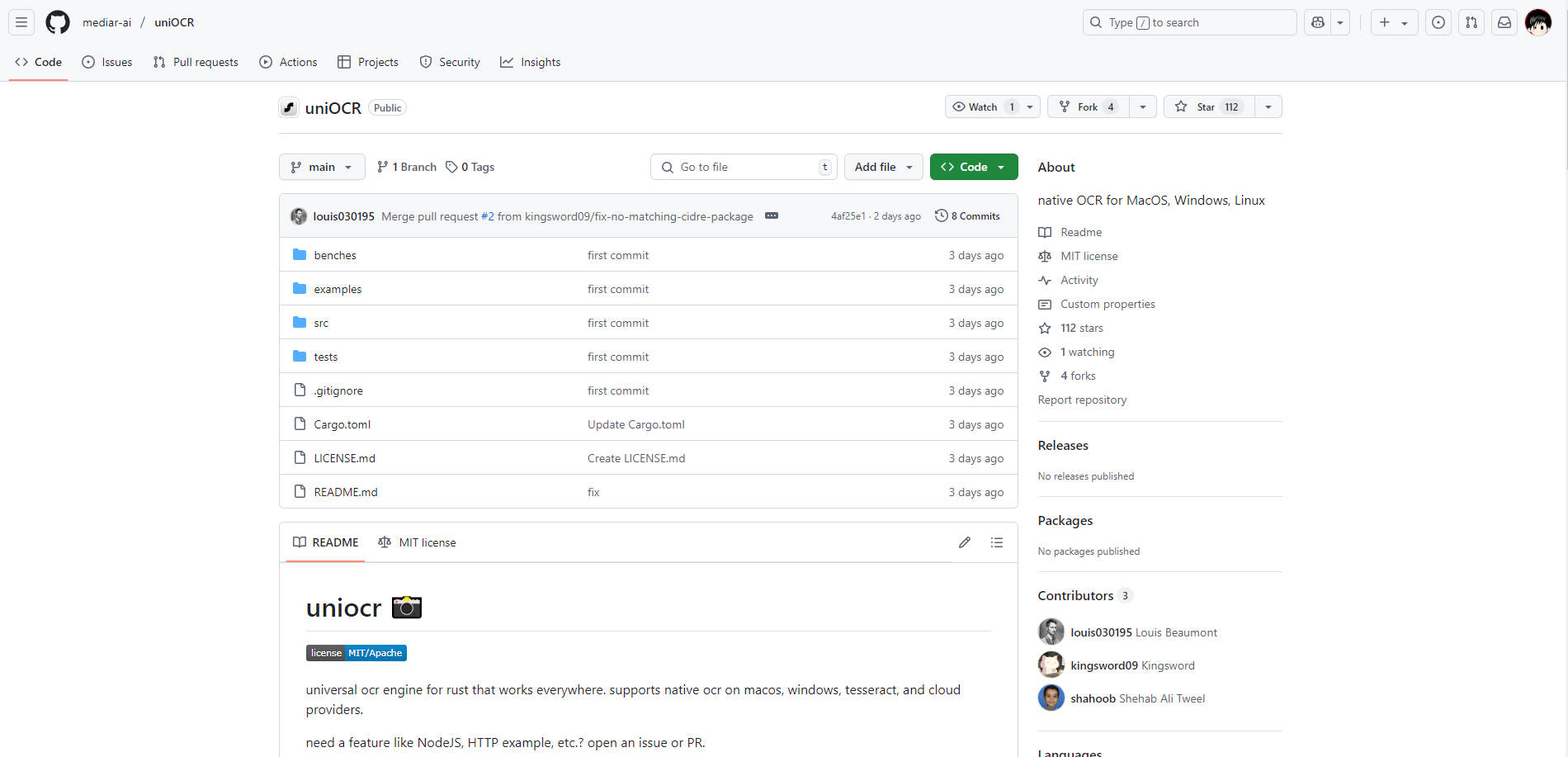
What is UniOCR?
将光学字符识别 (OCR) 集成到您的 Rust 应用程序中通常需要处理特定于平台的 API 或复杂的依赖项。uniocr 通过提供一个单一、一致的接口来访问各种 OCR 引擎(包括原生 OS 功能、Tesseract 和云提供商)来简化此过程。构建具有可靠文本识别功能的跨平台应用程序,无需为集成问题而烦恼。
uniocr 专为需要灵活且高性能的 OCR 解决方案的 Rust 开发人员而设计,该解决方案可在 macOS、Windows 和 Linux 上无缝运行。
主要特性
⚙️ 统一 API: 通过一个一致的 Rust 接口与各种 OCR 后端(原生、Tesseract、云)交互。只需少量代码更改即可切换提供商。
🍎 原生 macOS OCR: 利用 macOS 上内置的 Vision Kit 框架进行高效、无依赖的文本识别。无需额外设置。
🪟 原生 Windows OCR: 利用 Windows OCR 引擎(Windows 10+)在 Windows 平台上实现最佳性能和集成。
📚 Tesseract 集成: 提供对流行的开源 Tesseract 引擎的完全支持,包括自定义模型、语言选择和配置选项。
☁️ 云提供商就绪: 包含集成基于云的 OCR 服务的基础(例如,Google Cloud Vision - 目前需要用户自行实现)。
🚀 注重性能: 以速度和效率为设计理念,具有
async/await支持、用于批量操作的并行处理能力以及细致的内存管理。
使用场景
跨平台桌面应用程序: 您正在使用 Tauri 或 egui 构建一个 Rust 应用程序,该应用程序需要从 macOS 和 Windows 用户提供的屏幕截图或图像中提取文本。
uniocr通过OcrProvider::Auto自动选择最佳原生提供商(macOS 上的Vision Kit,Windows 上的Windows OCR),从而为用户提供最佳体验,而无需额外的依赖项。后端文档处理服务: 您的 Web 服务接收上传的文档(图像、转换为图像的 PDF),并且需要提取文本以在 Linux 服务器上进行索引或分析。您可以配置
uniocr以使用强大的 Tesseract 实例(可能带有专门的语言模型),从而利用其批量处理功能有效地处理处理队列。开发者工具: 您正在创建一个 CLI 工具,供开发人员分析包含代码片段或错误消息的图像。
uniocr允许该工具在不同的操作系统上本地运行,在可用时使用原生 OCR 以提高速度,或者在需要时回退到 Tesseract,所有这些都通过简单的OcrEngine接口进行管理。
结论
uniocr 为 Rust 开发人员提供了一种实用且高效的方式,将 OCR 功能整合到他们的项目中。通过将不同 OCR 后端的复杂性抽象到统一的异步 API 之后,它可以节省您的开发时间,并确保您的应用程序可以利用跨多个平台的最佳可用文本识别技术。它对原生集成和性能的关注使其成为要求严苛的 OCR 任务的可靠选择。
More information on UniOCR
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
UniOCR was manually vetted by our editorial team and was first featured on 2025-04-04.
Related Searches
UniOCR 替代方案
更多 替代方案-

Tesseract OCR:一款专为开发者设计的开源高精度引擎。凭借先进的LSTM技术,它能够支持逾百种语言,并提供灵活的API接口,助您轻松高效地从图像中提取文字。
-

-

-

-