
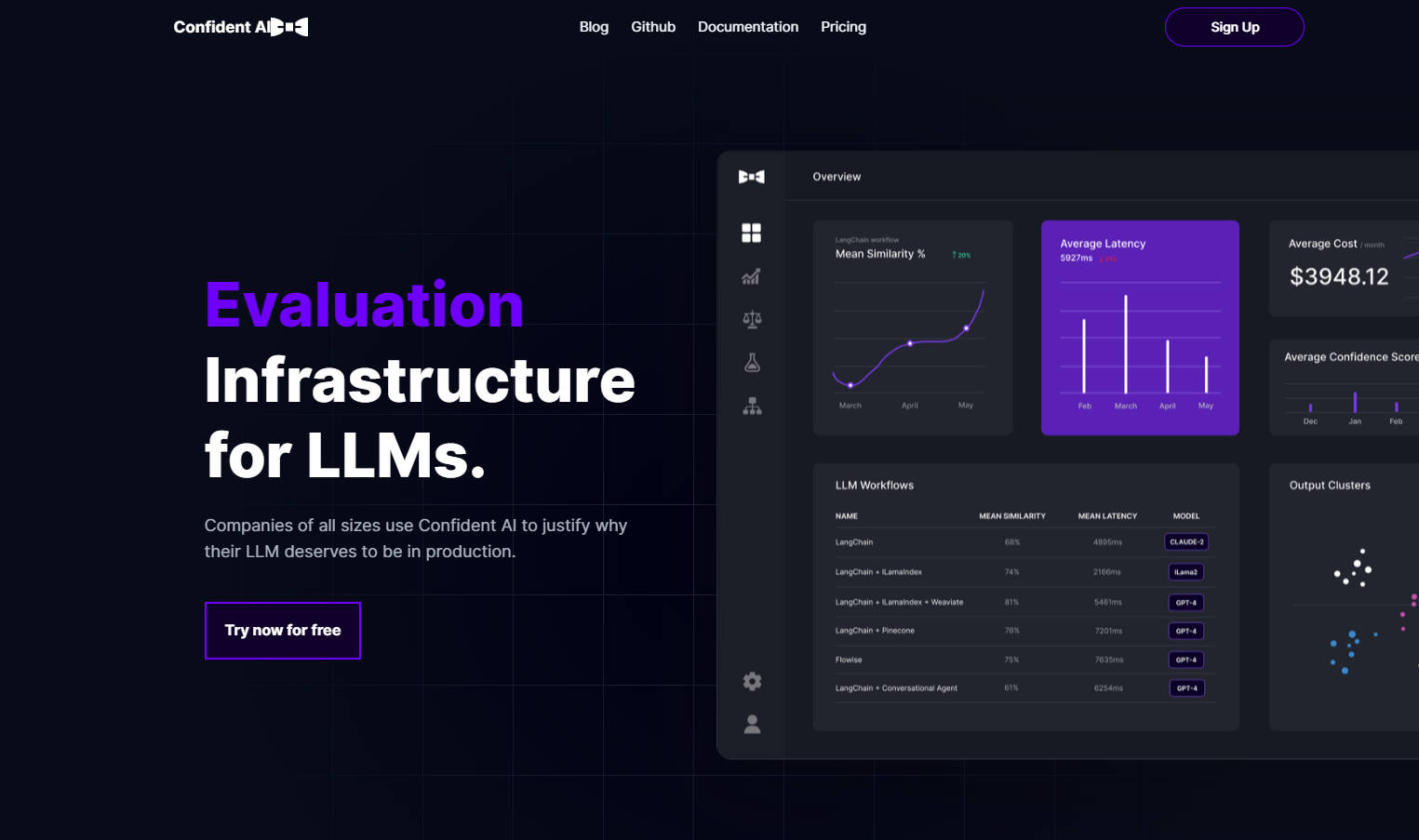
What is Confident AI?
Confident AI 是針對語言模型模型 (LLM) 的開源評估基礎架構。它提供一個集中式平台,用於判斷和部署 LLM 解決方案,並建立信心。此軟體提供進階功能,例如定義基本事實、全面分析,以及用於製作 LLM 的強大工具。使用 Confident AI,使用者可以針對預期基準評估其 LLM 輸出,透過詳細監控找出改進領域,並使用 A/B 測試和輸出分類來優化其工作流程。
主要功能:
1. 定義基本事實:Confident AI 允許使用者定義基本事實,作為基準來評估其 LLM 輸出的效能。透過將實際輸出與預期輸出進行比較,使用者可以找出反覆運算和改進的領域。
2. 全面分析:此軟體提供開箱即用的可觀察性,使用戶能夠找出和評估對其企業帶來最大投資報酬率 (ROI) 的使用案例。使用者可以利用詳細分析,隨著時間推移而減少成本並降低延遲。
3. 用於製作 LLM 的強大工具:Confident AI 提供了多項強大功能,以協助使用者在生產環境中自信地部署 LLM 解決方案。這些功能包括用於比較不同工作流程的 A/B 測試,透過評估指標量化並基準化 LLM 輸出與基本事實,找出重複的查詢和回應以進行最佳化,提供報告儀表板以深入了解降低成本的機會,自動產生資料集以進行評估,以及詳細監控能力以找出工作流程中的瓶頸。
使用案例:
- 評估反覆運算:Confident AI 使用者能夠透過追蹤提示範本之間的差異或選擇適當的知識庫,朝向最佳組態進行反覆運算。
- 最大化 ROI:透過使用 Confident AI 的報告儀表板所提供的 A/B 測試功能與全面分析,企業可以透過找出效能最佳的 LLM 工作流程,來最大化 ROI。
- 效能基準:使用者可以利用 Confident AI 提供的各種評估指標,針對預期基本事實量化其 LLM 模型的效能。
- 工作流程最佳化:此軟體透過詳細監控協助使用者找出 LLM 工作流程中的瓶頸,允許進行目標性反覆運算和改進。
Confident AI 是一個使用者友善的開源評估基礎架構,賦能使用者自信地部署和最佳化其 LLM 解決方案。透過其全面分析、強大的製作工具,以及定義基本事實的能力,Confident AI 可確保實質效益,同時解決 LLM 實作中的任何弱點。不論是針對預期輸出評估效能,或是找出最佳化重點領域,Confident AI 都提供必要的機能,以提升語言模型的效益。立即開始使用 Confident AI,解鎖 LLM 應用程式的全部潛力。
More information on Confident AI
Launched
2023-8
Pricing Model
Free
Starting Price
Global Rank
307106
Follow
Month Visit
113.4K
Tech used
Google Analytics,Google Tag Manager,Webflow,Amazon AWS CloudFront,Google Fonts,jQuery,Gzip,OpenGraph,HSTS
Top 5 Countries
19.63%
12%
7.2%
5.59%
4.14%
United States
India
Germany
Vietnam
United Kingdom
Traffic Sources
2.79%
0.8%
0.08%
7.64%
51.19%
37.49%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
Confident AI was manually vetted by our editorial team and was first featured on 2023-12-11.
Related Searches
Confident AI 替代方案
更多 替代方案-

Deepchecks:大型語言模型(LLM)的端對端評估平台。 從開發到上線,有系統地測試、比較並監控您的AI應用程式。 有效降低幻覺,並加速產品上市。
-

-
-

-
