
What is Berkeley Function-Calling Leaderboard?
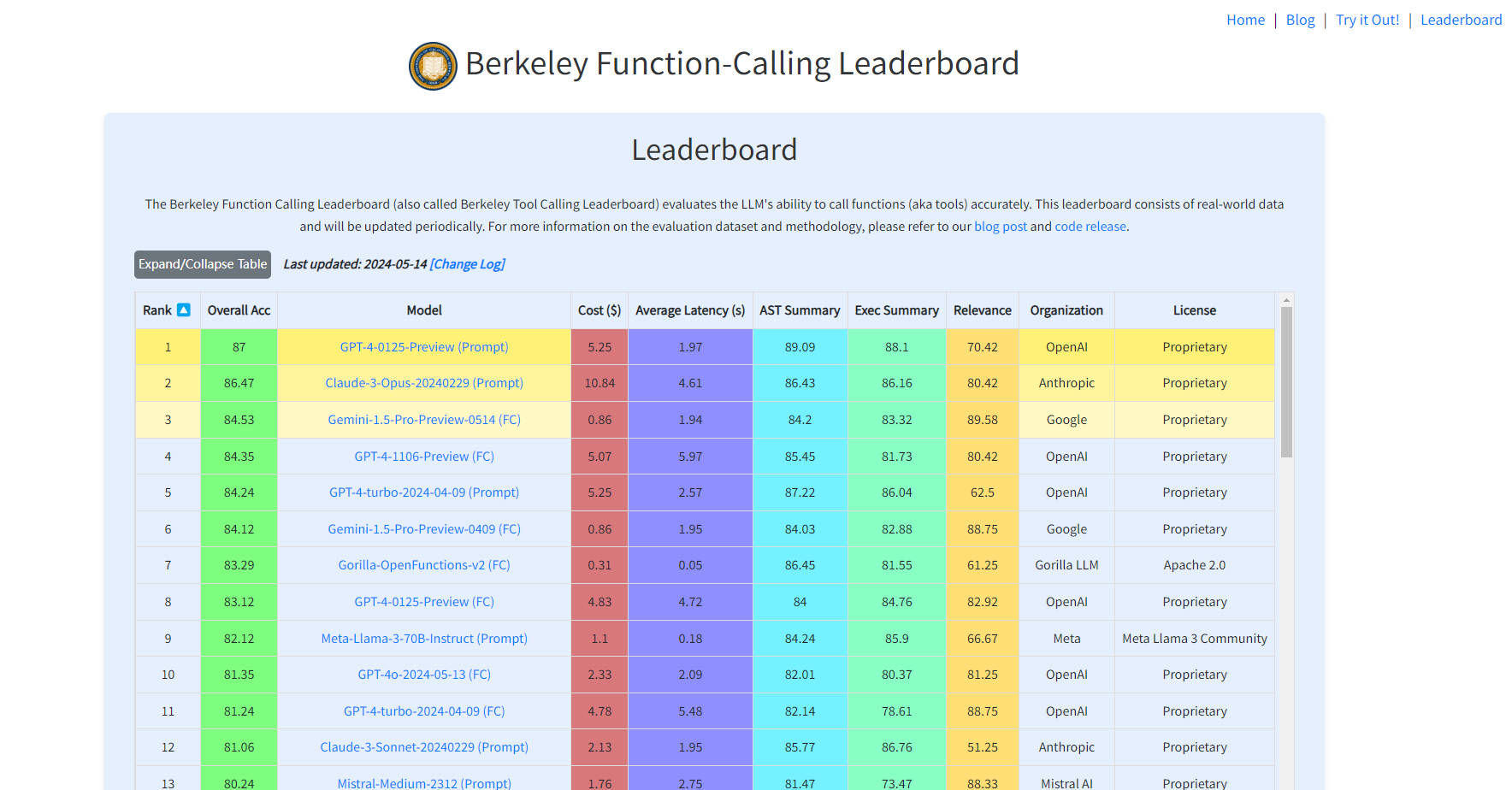
Berkeley Function-Calling Leaderboard is an innovative online platform designed to evaluate the capability of Large Language Models (LLMs) in accurately calling functions or tools. This benchmarking tool, based on real-world data and regularly updated, offers a valuable resource for developers, researchers, and users interested in AI programming abilities. It enables them to compare and choose the most suitable models for their specific needs, assessing both economic efficiency and performance.
Key Features
Comprehensive Evaluation of LLMs: Assesses the function-calling capabilities of large language models. 🤖
Real-World Data: Utilizes actual data sets for more accurate and relevant evaluations. 🌍
Regular Updates: Keeps the leaderboard current with the latest advancements in AI technology. 🔄
Detailed Error Analysis: Offers insights into the strengths and weaknesses of different models. 📊
Model Comparison: Facilitates easy comparison between models for informed decision-making. 🆚
Cost and Latency Estimations: Provides estimates for economic and timely model selection. 💰⏳
Use Cases
Research Comparison: Researchers utilize the leaderboard to compare the performance of various LLMs on specific programming tasks.
Developer Model Selection: Developers choose the most suitable AI model for their application based on leaderboard data.
Educational Resource: Educational institutions use the platform to showcase the latest advancements in AI technology.
How to Use
Visit the Website: Access the Berkeley Function-Calling Leaderboard online.
View the Leaderboard: Check the current scores and rankings of different models.
Explore Model Details: Click on a model to get detailed information and evaluation data.
Analyze Error Types: Use the provided tools to understand the model’s performance across various error types.
Assess Cost and Latency: Refer to the cost and delay estimates for economic and response speed evaluation.
Contribute or Submit: Contact the platform to submit your own model or contribute test cases.
Conclusion
Berkeley Function-Calling Leaderboard stands as a pivotal tool for the AI community, offering a transparent and data-driven approach to evaluating and selecting the most effective large language models for programming tasks. By providing comprehensive evaluations, real-world insights, and practical comparisons, it empowers users to make informed decisions that enhance the efficiency and effectiveness of their AI applications. Join the ranks of forward-thinking professionals and explore the potential of AI programming with Berkeley Function-Calling Leaderboard.
More information on Berkeley Function-Calling Leaderboard
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Google Analytics,Google Tag Manager,cdnjs,Fastly,Google Fonts,Bootstrap,GitHub Pages,Gzip,Varnish,YouTube
Berkeley Function-Calling Leaderboard was manually vetted by our editorial team and was first featured on 2024-05-29.
Related Searches
Berkeley Function-Calling Leaderboard Alternatives
Load more Alternatives-

Real-time Klu.ai data powers this leaderboard for evaluating LLM providers, enabling selection of the optimal API and model for your needs.
-

Huggingface’s Open LLM Leaderboard aims to foster open collaboration and transparency in the evaluation of language models.
-

The SEAL Leaderboards show that OpenAI’s GPT family of LLMs ranks first in three of the four initial domains it’s using to rank AI models, with Anthropic PBC’s popular Claude 3 Opus grabbing first place in the fourth category. Google LLC’s Gemini models also did well, ranking joint-first with the GPT models in a couple of the domains.
-

-

Choose the best AI agent for your needs with the Agent Leaderboard—unbiased, real-world performance insights across 14 benchmarks.