
What is Berkeley Function-Calling Leaderboard?
Berkeley Function-Calling Leaderboard는 대규모 언어 모델(LLM)의 함수 또는 도구 호출 기능을 정확하게 평가하기 위해 설계된 혁신적인 온라인 플랫폼입니다. 실제 데이터를 기반으로 하고 정기적으로 업데이트되는 이 벤치마킹 도구는 AI 프로그래밍 기능에 관심 있는 개발자, 연구자 및 사용자에게 귀중한 리소스를 제공합니다. 이를 통해 사용자는 경제적 효율성과 성능을 모두 평가하여 특정 요구 사항에 가장 적합한 모델을 비교하고 선택할 수 있습니다.
주요 기능
LLM의 종합적인 평가: 대규모 언어 모델의 함수 호출 기능을 평가합니다. ?
실제 데이터: 더 정확하고 관련성 있는 평가를 위해 실제 데이터 세트를 사용합니다. ?
정기 업데이트: AI 기술의 최신 발전을 반영하여 순위표를 최신 상태로 유지합니다. ?
상세한 오류 분석: 다양한 모델의 강점과 약점에 대한 통찰력을 제공합니다. ?
모델 비교: 정보에 입각한 의사 결정을 위해 모델 간의 쉬운 비교를 용이하게 합니다. ?
비용 및 지연 시간 추정: 경제적이고 적시에 모델을 선택하기 위한 추정치를 제공합니다. ?⏳
사용 사례
연구 비교: 연구자는 순위표를 사용하여 특정 프로그래밍 작업에서 다양한 LLM의 성능을 비교합니다.
개발자 모델 선택: 개발자는 순위표 데이터를 기반으로 애플리케이션에 가장 적합한 AI 모델을 선택합니다.
교육 자료: 교육 기관은 이 플랫폼을 사용하여 AI 기술의 최신 발전을 보여줍니다.
사용 방법
웹사이트 방문: Berkeley Function-Calling Leaderboard에 온라인으로 접속합니다.
순위표 보기: 다양한 모델의 현재 점수와 순위를 확인합니다.
모델 세부 정보 탐색: 모델을 클릭하여 자세한 정보와 평가 데이터를 얻습니다.
오류 유형 분석: 제공된 도구를 사용하여 다양한 오류 유형에서 모델의 성능을 이해합니다.
비용 및 지연 시간 평가: 경제적 및 응답 속도 평가를 위해 비용 및 지연 시간 추정치를 참조합니다.
기여 또는 제출: 플랫폼에 연락하여 자신의 모델을 제출하거나 테스트 케이스에 기여합니다.
결론
Berkeley Function-Calling Leaderboard는 AI 커뮤니티에서 프로그래밍 작업에 가장 효과적인 대규모 언어 모델을 평가하고 선택하는 데 투명하고 데이터 중심적인 접근 방식을 제공하는 핵심 도구입니다. 종합적인 평가, 실제 통찰력 및 실용적인 비교를 제공함으로써 사용자가 AI 애플리케이션의 효율성과 효과를 향상시키는 정보에 입각한 결정을 내릴 수 있도록 지원합니다. 미래 지향적인 전문가 그룹에 합류하여 Berkeley Function-Calling Leaderboard를 사용하여 AI 프로그래밍의 잠재력을 탐구하십시오.
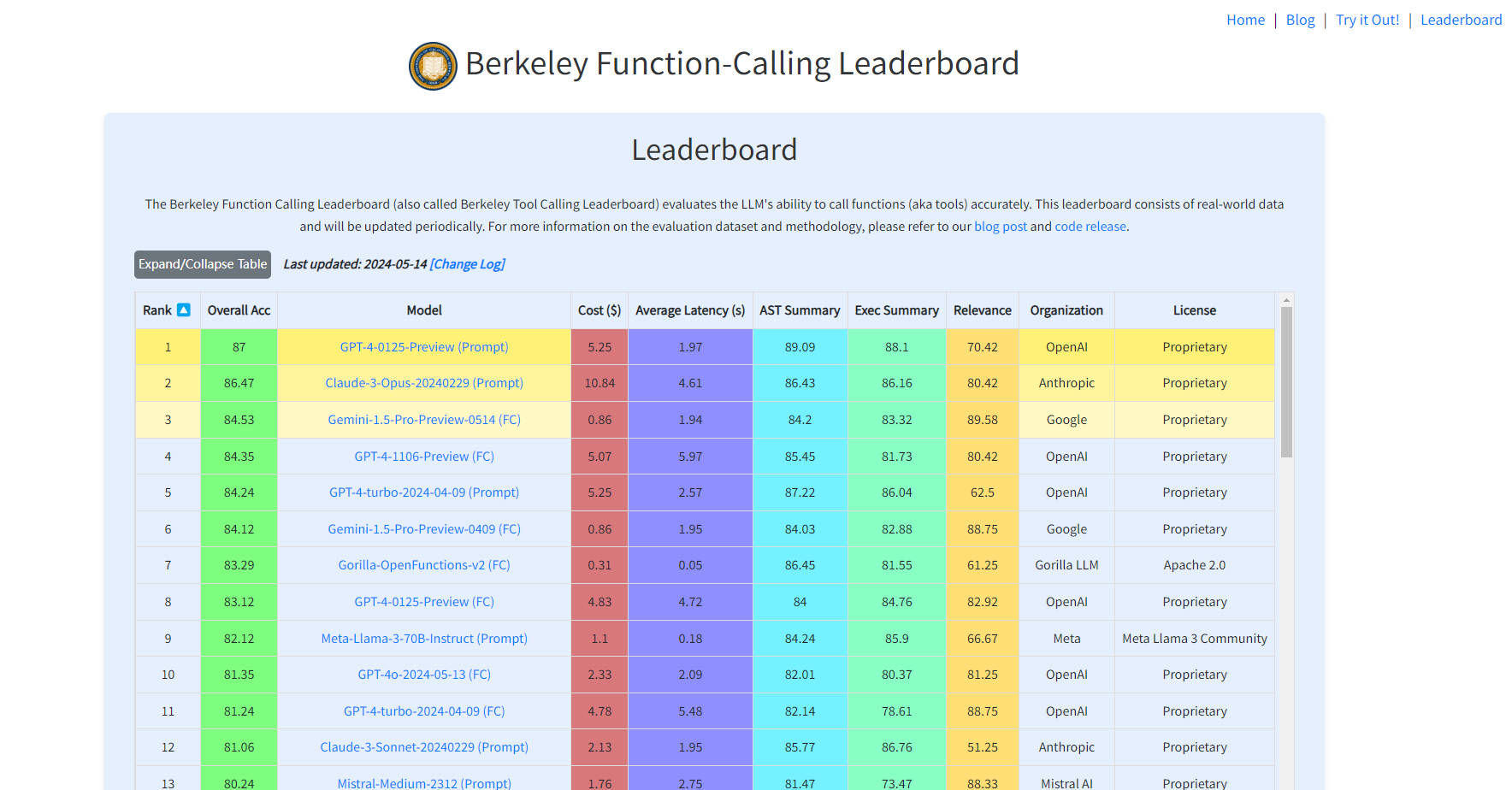
More information on Berkeley Function-Calling Leaderboard
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Google Analytics,Google Tag Manager,cdnjs,Fastly,Google Fonts,Bootstrap,GitHub Pages,Gzip,Varnish,YouTube
Berkeley Function-Calling Leaderboard was manually vetted by our editorial team and was first featured on 2024-05-29.
Related Searches
Berkeley Function-Calling Leaderboard 대체품
더보기 대체품-

실시간 Klu.ai 데이터는 LLM 제공업체를 평가하기 위한 이 리더보드를 구동하여 사용자의 요구에 맞는 최적의 API 및 모델을 선택할 수 있도록 지원합니다.
-

Huggingface의 Open LLM Leaderboard는 언어 모델 평가에 대한 개방적인 협업과 투명성을 촉진하기 위한 목표를 가지고 있습니다.
-

SEAL 리더보드에 따르면 OpenAI의 GPT 계열 LLM은 AI 모델을 평가하는 데 사용되는 초기 4개 도메인 중 3개에서 1위를 차지했습니다. Anthropic PBC의 인기 모델인 Claude 3 Opus는 나머지 하나의 카테고리에서 1위를 차지했습니다. Google LLC의 Gemini 모델도 좋은 성적을 거두어 몇몇 도메인에서 GPT 모델과 공동 1위를 차지했습니다.
-

-

Agent Leaderboard를 통해 귀사의 요구사항에 가장 적합한 AI 에이전트를 선택하십시오. 14개의 벤치마크 전반에 걸쳐 편향 없는 실제 성능 통찰력을 제공합니다.