
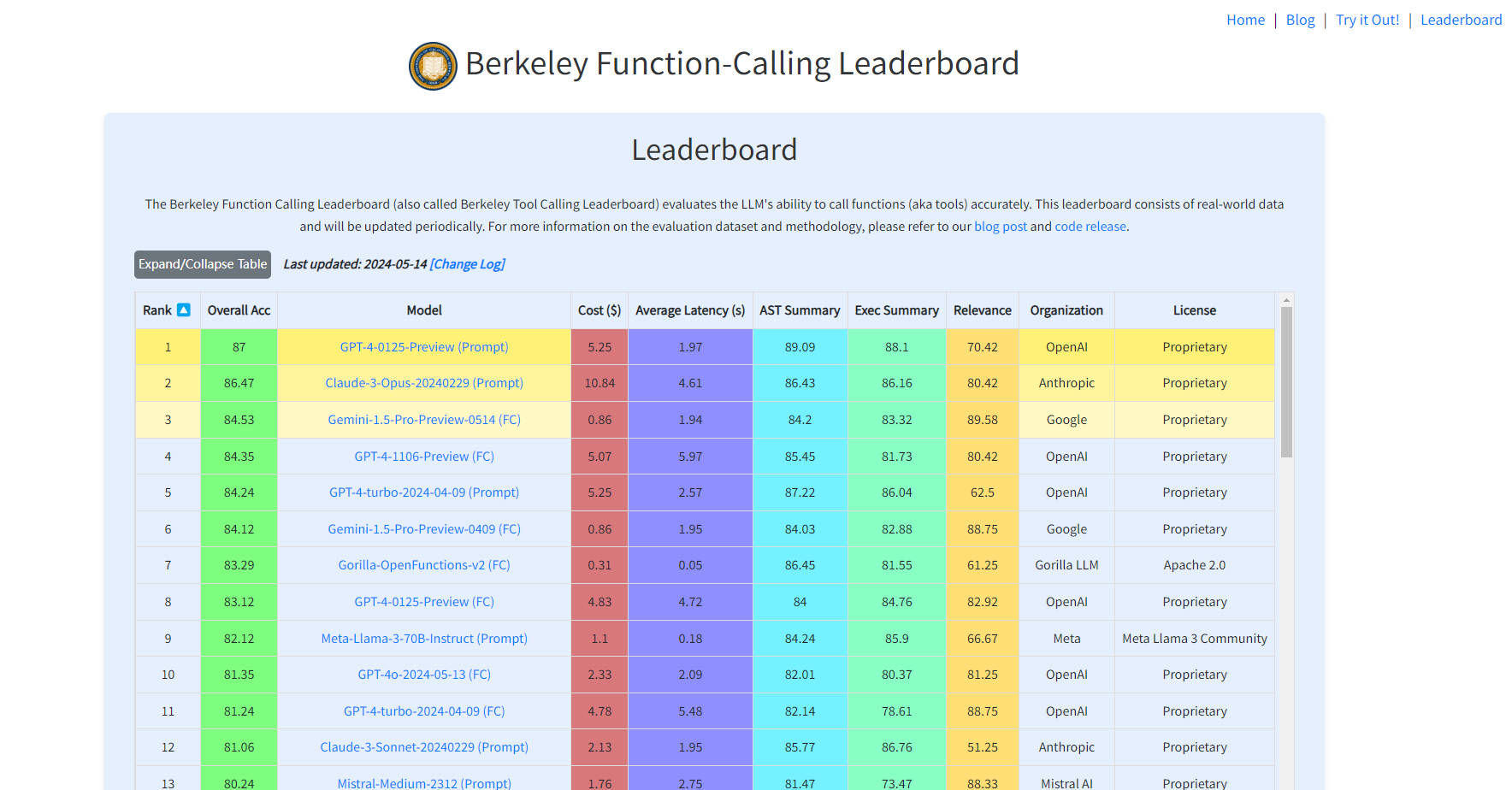
What is Berkeley Function-Calling Leaderboard?
Berkeley Function-Calling Leaderboard - это инновационная онлайн-платформа, разработанная для оценки способности больших языковых моделей (LLM) к точному вызову функций или инструментов. Этот инструмент бенчмаркинга, основанный на реальных данных и регулярно обновляемый, представляет собой ценный ресурс для разработчиков, исследователей и пользователей, интересующихся возможностями программирования ИИ. Он позволяет им сравнивать и выбирать наиболее подходящие модели для своих конкретных потребностей, оценивая как экономическую эффективность, так и производительность.
Ключевые возможности
Комплексная оценка LLM: Оценивает возможности вызова функций больших языковых моделей. ?
Реальные данные: Использует актуальные наборы данных для более точной и релевантной оценки. ?
Регулярные обновления: Поддерживает актуальность рейтинга с учетом последних достижений в области технологий ИИ. ?
Детальный анализ ошибок: Предоставляет информацию о сильных и слабых сторонах различных моделей. ?
Сравнение моделей: Обеспечивает простое сравнение моделей для принятия обоснованных решений. ?
Оценки стоимости и задержки: Предоставляет оценки для экономичного и своевременного выбора модели. ?⏳
Сферы применения
Исследовательское сравнение: Исследователи используют рейтинг для сравнения производительности различных LLM в решении конкретных задач программирования.
Выбор модели разработчиком: Разработчики выбирают наиболее подходящую модель ИИ для своего приложения на основе данных рейтинга.
Образовательный ресурс: Образовательные учреждения используют платформу для демонстрации последних достижений в области технологий ИИ.
Как использовать
Посетите веб-сайт: Получите доступ к Berkeley Function-Calling Leaderboard онлайн.
Просмотрите рейтинг: Проверьте текущие баллы и рейтинги различных моделей.
Изучите подробности о модели: Нажмите на модель, чтобы получить подробную информацию и данные оценки.
Анализируйте типы ошибок: Используйте предоставленные инструменты, чтобы понять производительность модели по различным типам ошибок.
Оцените стоимость и задержку: Ознакомьтесь с оценками стоимости и задержки для оценки экономической эффективности и скорости отклика.
Внесите свой вклад или отправьте: Свяжитесь с платформой, чтобы отправить свою собственную модель или внести тестовые случаи.
Заключение
Berkeley Function-Calling Leaderboard является ключевым инструментом для сообщества ИИ, предлагая прозрачный и основанный на данных подход к оценке и выбору наиболее эффективных больших языковых моделей для задач программирования. Предоставляя комплексные оценки, реальные сведения и практические сравнения, он позволяет пользователям принимать обоснованные решения, повышающие эффективность и результативность их приложений ИИ. Присоединяйтесь к рядам дальновидных специалистов и изучите потенциал программирования ИИ с помощью Berkeley Function-Calling Leaderboard.
More information on Berkeley Function-Calling Leaderboard
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Google Analytics,Google Tag Manager,cdnjs,Fastly,Google Fonts,Bootstrap,GitHub Pages,Gzip,Varnish,YouTube
Berkeley Function-Calling Leaderboard was manually vetted by our editorial team and was first featured on 2024-05-29.
Related Searches
Berkeley Function-Calling Leaderboard Альтернативи
Больше Альтернативи-

Данная таблица лидеров для оценки поставщиков LLM работает на основе данных Klu.ai в режиме реального времени, что позволяет выбрать оптимальный API и модель для ваших нужд.
-

Рейтинг открытых языковых моделей Huggingface направлен на поощрение открытого сотрудничества и прозрачности в оценке языковых моделей.
-

Рейтинг SEAL демонстрирует, что семейство больших языковых моделей (LLM) GPT от OpenAI занимает первое место в трех из четырех начальных областей, которые они используют для ранжирования моделей ИИ, а популярный Claude 3 Opus от Anthropic PBC занимает первое место в четвертой категории. Модели Gemini от Google LLC также показали хорошие результаты, разделив первое место с моделями GPT в паре областей.
-

-

Выбирайте лучшего AI-агента, отвечающего вашим потребностям, с помощью Agent Leaderboard — объективного анализа производительности в реальных условиях, основанного на 14 критериях оценки.