
What is Berkeley Function-Calling Leaderboard?
Berkeley Function-Calling Leaderboard est une plateforme en ligne innovante conçue pour évaluer la capacité des grands modèles de langage (LLM) à appeler des fonctions ou des outils avec précision. Cet outil de référence, basé sur des données réelles et régulièrement mis à jour, offre une ressource précieuse pour les développeurs, les chercheurs et les utilisateurs intéressés par les capacités de programmation de l'IA. Il leur permet de comparer et de choisir les modèles les plus adaptés à leurs besoins spécifiques, en évaluant à la fois l'efficacité économique et les performances.
Fonctionnalités clés
Évaluation complète des LLM : Évalue les capacités d'appel de fonctions des grands modèles de langage. ?
Données du monde réel : Utilise des ensembles de données réels pour des évaluations plus précises et pertinentes. ?
Mises à jour régulières : Maintient le classement à jour avec les dernières avancées en matière de technologie de l'IA. ?
Analyse d'erreur détaillée : Offre des informations sur les forces et les faiblesses des différents modèles. ?
Comparaison des modèles : Facilite la comparaison entre les modèles pour une prise de décision éclairée. ?
Estimations de coût et de latence : Fournit des estimations pour la sélection de modèles économiques et opportuns. ?⏳
Cas d'utilisation
Comparaison de la recherche : Les chercheurs utilisent le classement pour comparer les performances de divers LLM sur des tâches de programmation spécifiques.
Sélection du modèle de développement : Les développeurs choisissent le modèle d'IA le plus adapté à leur application en fonction des données du classement.
Ressource éducative : Les établissements d'enseignement utilisent la plateforme pour présenter les dernières avancées en matière de technologie de l'IA.
Mode d'emploi
Visitez le site Web : Accédez à Berkeley Function-Calling Leaderboard en ligne.
Consultez le classement : Vérifiez les scores et les classements actuels des différents modèles.
Explorez les détails du modèle : Cliquez sur un modèle pour obtenir des informations détaillées et des données d'évaluation.
Analysez les types d'erreurs : Utilisez les outils fournis pour comprendre les performances du modèle sur différents types d'erreurs.
Évaluez le coût et la latence : Consultez les estimations de coût et de délai pour une évaluation économique et de la vitesse de réponse.
Contribuez ou soumettez : Contactez la plateforme pour soumettre votre propre modèle ou contribuer à des cas de test.
Conclusion
Berkeley Function-Calling Leaderboard constitue un outil essentiel pour la communauté de l'IA, offrant une approche transparente et axée sur les données pour évaluer et sélectionner les grands modèles de langage les plus efficaces pour les tâches de programmation. En fournissant des évaluations complètes, des informations du monde réel et des comparaisons pratiques, il permet aux utilisateurs de prendre des décisions éclairées qui améliorent l'efficacité et l'efficience de leurs applications d'IA. Rejoignez les rangs des professionnels avant-gardistes et explorez le potentiel de la programmation de l'IA avec Berkeley Function-Calling Leaderboard.
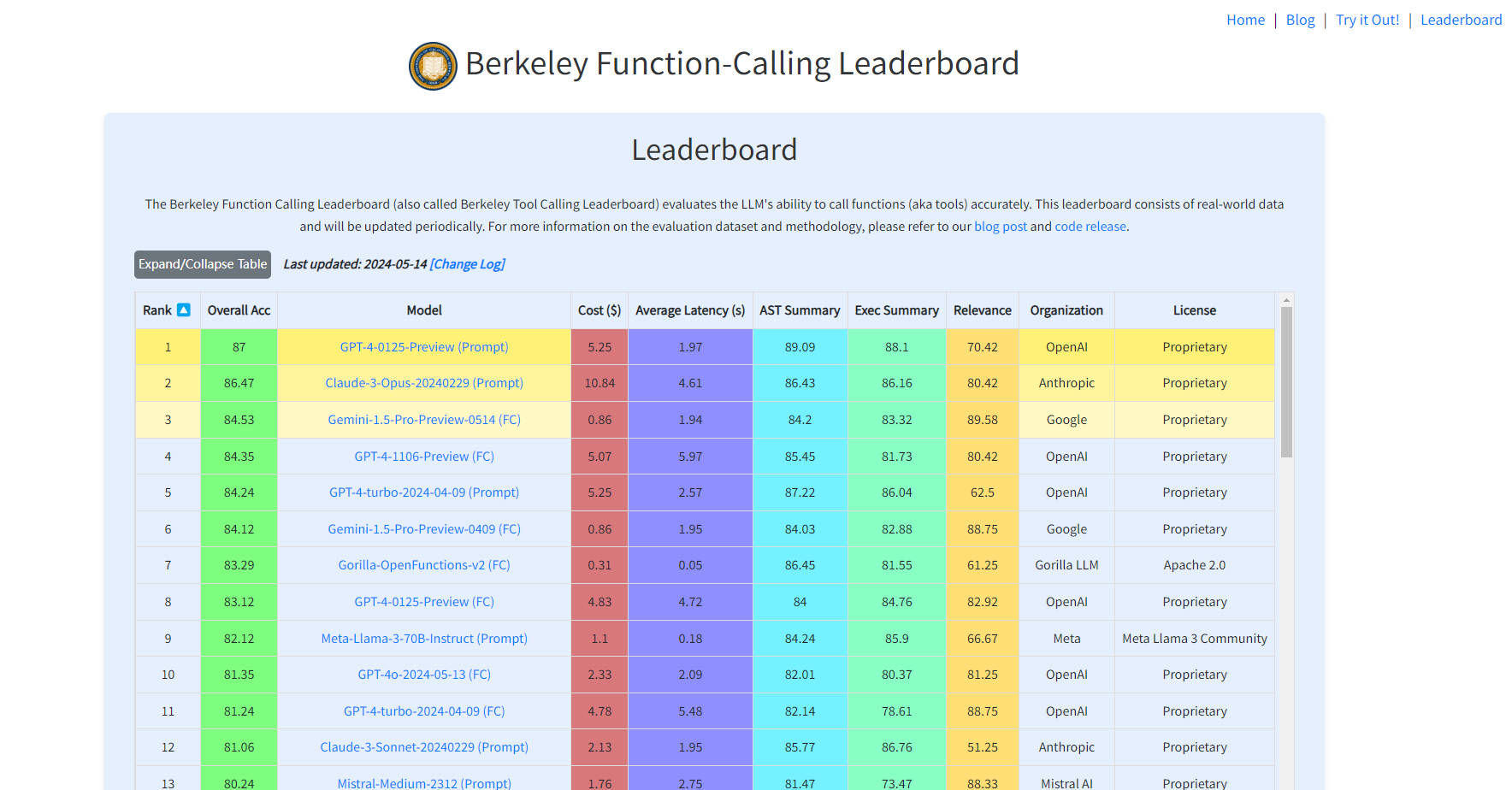
More information on Berkeley Function-Calling Leaderboard
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Google Analytics,Google Tag Manager,cdnjs,Fastly,Google Fonts,Bootstrap,GitHub Pages,Gzip,Varnish,YouTube
Berkeley Function-Calling Leaderboard was manually vetted by our editorial team and was first featured on 2024-05-29.
Related Searches
Berkeley Function-Calling Leaderboard Alternatives
Plus Alternatives-

Les données de Klu.ai en temps réel alimentent ce classement pour évaluer les fournisseurs de LLM, permettant la sélection de l'API et du modèle optimaux pour vos besoins.
-

Le classement Open LLM Leaderboard de Huggingface vise à promouvoir une collaboration ouverte et la transparence dans l'évaluation des modèles de langage.
-

Le classement SEAL montre que la famille GPT d'OpenAI occupe la première place dans trois des quatre domaines initiaux utilisés pour classer les modèles d'IA, Claude 3 Opus d'Anthropic PBC s'emparant de la première place dans la quatrième catégorie. Les modèles Gemini de Google LLC ont également bien performé, se classant en tête à égalité avec les modèles GPT dans quelques-uns des domaines.
-

-

Choisissez l'agent d'IA le plus adapté à vos besoins grâce au Agent Leaderboard : des données de performance impartiales et concrètes, basées sur 14 benchmarks.