
What is Berkeley Function-Calling Leaderboard?
Berkeley Function-Calling Leaderboard es una plataforma en línea innovadora diseñada para evaluar la capacidad de los Modelos de Lenguaje Extensos (LLM) para llamar funciones o herramientas con precisión. Esta herramienta de evaluación comparativa, basada en datos del mundo real y actualizada periódicamente, ofrece un recurso valioso para desarrolladores, investigadores y usuarios interesados en las capacidades de programación de la IA. Les permite comparar y elegir los modelos más adecuados para sus necesidades específicas, evaluando tanto la eficiencia económica como el rendimiento.
Características clave
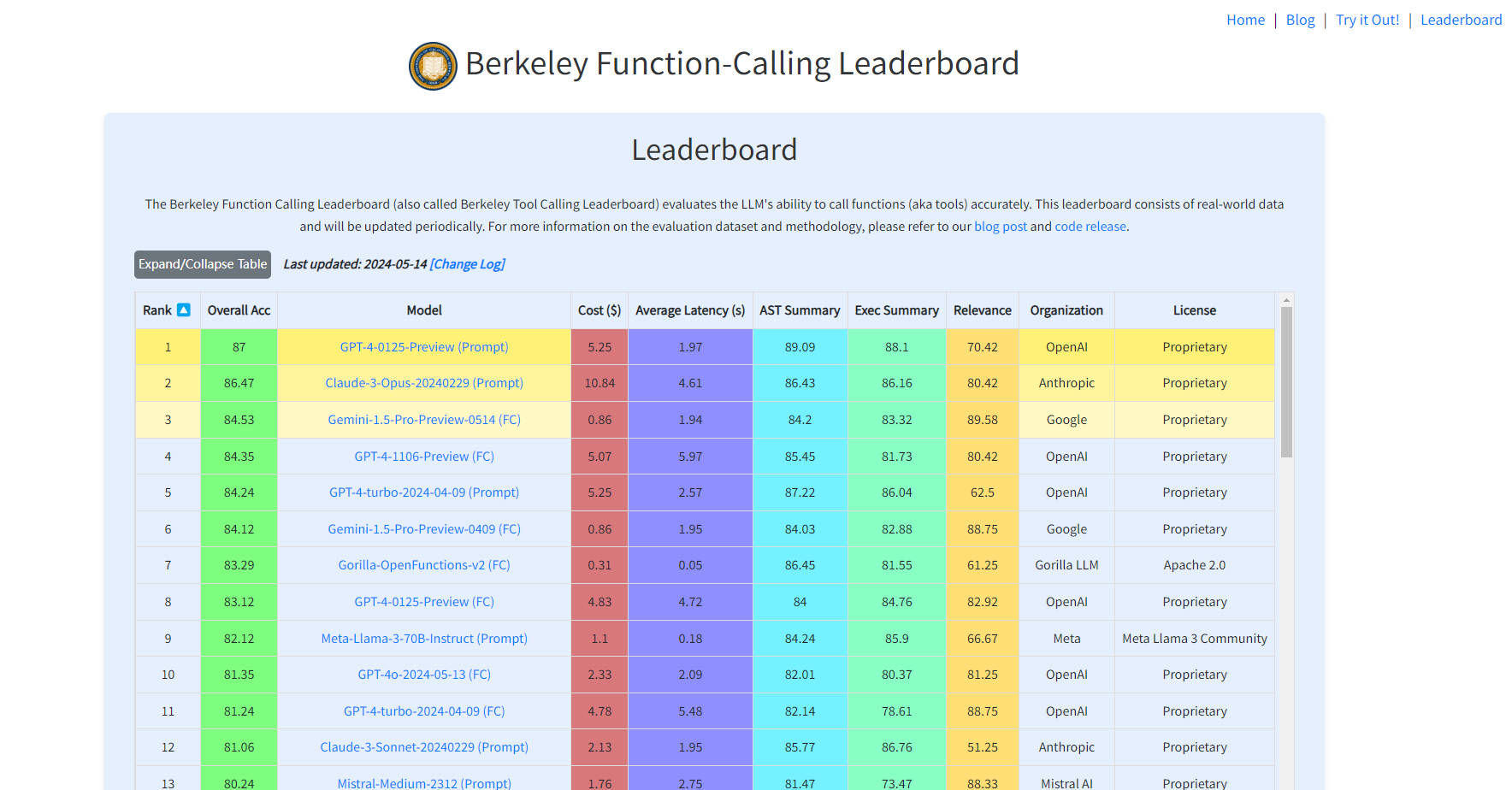
Evaluación integral de los LLM: Evalúa las capacidades de llamada de funciones de los modelos de lenguaje grandes. ?
Datos del mundo real: Utiliza conjuntos de datos reales para evaluaciones más precisas y relevantes. ?
Actualizaciones periódicas: Mantiene el marcador actualizado con los últimos avances en tecnología de IA. ?
Análisis detallado de errores: Ofrece información sobre las fortalezas y debilidades de los diferentes modelos. ?
Comparación de modelos: Facilita la comparación entre modelos para una toma de decisiones informada. ?
Estimaciones de costo y latencia: Proporciona estimaciones para la selección de modelos económicos y oportunos. ?⏳
Casos de uso
Comparación de investigación: Los investigadores utilizan el marcador para comparar el rendimiento de varios LLM en tareas de programación específicas.
Selección de modelos para desarrolladores: Los desarrolladores eligen el modelo de IA más adecuado para su aplicación en función de los datos del marcador.
Recurso educativo: Las instituciones educativas utilizan la plataforma para mostrar los últimos avances en tecnología de IA.
Cómo usar
Visita el sitio web: Accede a Berkeley Function-Calling Leaderboard en línea.
Ver el marcador: Consulta las puntuaciones y clasificaciones actuales de los diferentes modelos.
Explora los detalles del modelo: Haz clic en un modelo para obtener información detallada y datos de evaluación.
Analiza los tipos de errores: Utiliza las herramientas proporcionadas para comprender el rendimiento del modelo en varios tipos de errores.
Evalúa el costo y la latencia: Consulta las estimaciones de costo y retraso para la evaluación económica y de velocidad de respuesta.
Contribuye o envía: Ponte en contacto con la plataforma para enviar tu propio modelo o contribuir con casos de prueba.
Conclusión
Berkeley Function-Calling Leaderboard se erige como una herramienta fundamental para la comunidad de IA, ofreciendo un enfoque transparente y basado en datos para evaluar y seleccionar los modelos de lenguaje grandes más efectivos para las tareas de programación. Al proporcionar evaluaciones integrales, información del mundo real y comparaciones prácticas, permite a los usuarios tomar decisiones informadas que mejoran la eficiencia y la eficacia de sus aplicaciones de IA. Únase a las filas de profesionales con visión de futuro y explore el potencial de la programación de IA con Berkeley Function-Calling Leaderboard.
More information on Berkeley Function-Calling Leaderboard
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Google Analytics,Google Tag Manager,cdnjs,Fastly,Google Fonts,Bootstrap,GitHub Pages,Gzip,Varnish,YouTube
Berkeley Function-Calling Leaderboard was manually vetted by our editorial team and was first featured on 2024-05-29.
Related Searches
Berkeley Function-Calling Leaderboard Alternativas
Más Alternativas-

Los datos de Klu.ai en tiempo real impulsan esta tabla de clasificación para evaluar proveedores de LLM, permitiendo la selección de la API y el modelo óptimos para sus necesidades.
-

El Leaderboard de Modelos de Lenguaje Abiertos de Huggingface tiene como objetivo fomentar la colaboración abierta y la transparencia en la evaluación de modelos de lenguaje.
-

Las tablas de clasificación de SEAL muestran que la familia GPT de LLMs de OpenAI ocupa el primer lugar en tres de los cuatro dominios iniciales que utiliza para clasificar los modelos de IA, mientras que Claude 3 Opus, el popular modelo de Anthropic PBC, se lleva el primer lugar en la cuarta categoría. Los modelos Gemini de Google LLC también se desempeñaron bien, ocupando el primer lugar junto con los modelos GPT en un par de los dominios.
-

-

Seleccione el mejor agente de IA para sus necesidades con la Agent Leaderboard: análisis de rendimiento imparciales y del mundo real en 14 pruebas de referencia.