
What is Berkeley Function-Calling Leaderboard?
Berkeley Function-Calling Leaderboardは、大規模言語モデル(LLM)が関数やツールを正確に呼び出す能力を評価するために設計された革新的なオンラインプラットフォームです。このベンチマークツールは、現実世界のデータに基づいており、定期的に更新されるため、AIプログラミング能力に関心のある開発者、研究者、ユーザーにとって貴重なリソースとなります。これにより、経済効率とパフォーマンスの両方を評価して、特定のニーズに最適なモデルを比較して選択することができます。
主な機能
LLMの包括的な評価:大規模言語モデルの関数呼び出し能力を評価します。?
現実世界のデータ:より正確で関連性の高い評価のために、実際のデータセットを使用します。?
定期的な更新:AI技術の最新の発展に合わせてリーダーボードを最新の状態に保ちます。?
詳細なエラー分析:さまざまなモデルの長所と短所に関する洞察を提供します。?
モデル比較:情報に基づいた意思決定のために、モデル間の簡単な比較を容易にします。?
コストとレイテンシの推定:経済的でタイムリーなモデル選択のための推定値を提供します。?⏳
ユースケース
研究比較:研究者は、リーダーボードを使用して、特定のプログラミングタスクにおけるさまざまなLLMのパフォーマンスを比較します。
開発者モデルの選択:開発者は、リーダーボードのデータに基づいて、アプリケーションに最適なAIモデルを選択します。
教育リソース:教育機関は、プラットフォームを使用して、AI技術の最新の発展を展示します。
使用方法
ウェブサイトにアクセスする:Berkeley Function-Calling Leaderboardにオンラインでアクセスします。
リーダーボードを見る:さまざまなモデルの現在のスコアとランキングを確認します。
モデルの詳細を調べる:モデルをクリックして、詳細情報と評価データを取得します。
エラータイプを分析する:提供されたツールを使用して、さまざまなエラータイプにおけるモデルのパフォーマンスを理解します。
コストとレイテンシを評価する:経済性と応答速度の評価のために、コストと遅延の推定値を参照してください。
貢献または提出:独自のモデルを提出するか、テストケースを提供するためにプラットフォームに連絡してください。
結論
Berkeley Function-Calling Leaderboardは、AIコミュニティにとって重要なツールであり、プログラミングタスクに最も効果的な大規模言語モデルを評価および選択するための透明でデータ駆動型のアプローチを提供します。包括的な評価、現実世界の洞察、実用的な比較を提供することで、ユーザーはAIアプリケーションの効率と有効性を高めるための情報に基づいた意思決定を下すことができます。先見の明のある専門家の仲間入りをして、Berkeley Function-Calling LeaderboardでAIプログラミングの可能性を探求しましょう。
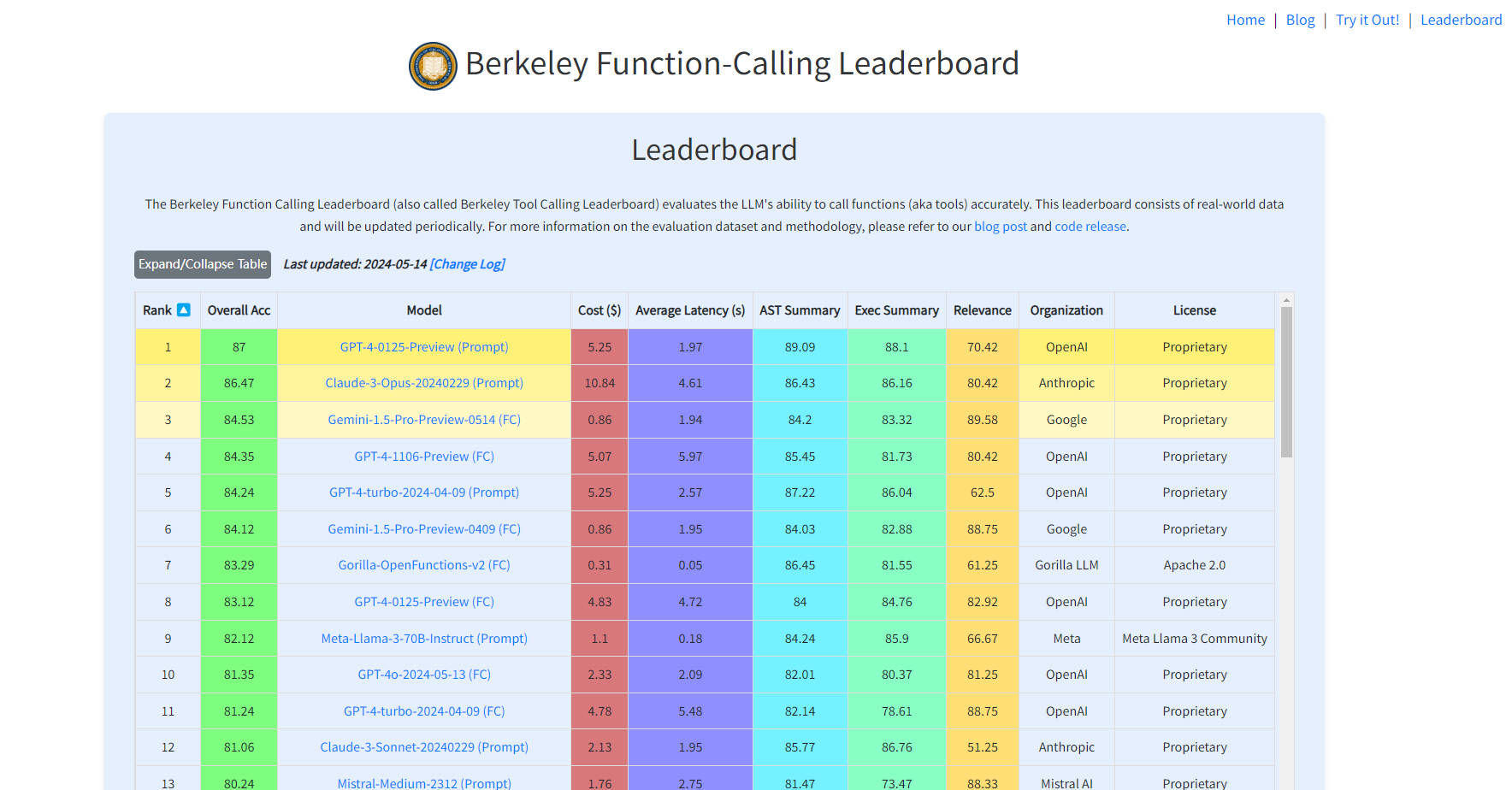
More information on Berkeley Function-Calling Leaderboard
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Google Analytics,Google Tag Manager,cdnjs,Fastly,Google Fonts,Bootstrap,GitHub Pages,Gzip,Varnish,YouTube
Berkeley Function-Calling Leaderboard was manually vetted by our editorial team and was first featured on 2024-05-29.
Related Searches
Berkeley Function-Calling Leaderboard 代替ソフト
もっと見る 代替ソフト-

リアルタイムのKlu.aiデータがこのリーダーボードを支え、LLMプロバイダーの評価を可能にし、ニーズに最適なAPIとモデルを選択できます。
-

HuggingfaceのオープンLLMリーダーボードは、言語モデルの評価におけるオープンなコラボレーションと透明性を促進することを目的としています。
-

SEAL Leaderboardによると、OpenAIのGPTファミリーのLLMは、AIモデルのランキングに使用されている最初の4つのドメインのうち3つで1位にランクインしています。Anthropic PBCのClaude 3 Opusは、4つ目のカテゴリで1位を獲得しました。Google LLCのGeminiモデルも好成績を収め、いくつかのドメインでGPTモデルと共同で1位にランクインしました。
-

-

14種類のベンチマークに基づいた、偏りのないリアルな性能評価を提供する「Agent Leaderboard」で、ニーズに最適なAIエージェントを見つけましょう。