
What is DeepSeek-OCR?
DeepSeek-OCR es un novedoso Modelo de Lenguaje Visual (VLM) diseñado para mejorar drásticamente la eficiencia de procesamiento de documentos de contexto largo para los grandes modelos de lenguaje (LLMs). Mediante la implementación pionera de una técnica denominada Contexts Optical Compression, este modelo de 3 mil millones de parámetros aborda el enorme desafío computacional de digitalizar y analizar extensos archivos de documentos, permitiendo a investigadores y empresas manejar grandes volúmenes de datos con una velocidad y precisión sin precedentes. Ahora puede transformar eficientemente las representaciones visuales de documentos en datos altamente comprimidos y de alta fidelidad, idóneos para la capacitación y aplicación de la próxima generación de IA.
Características Principales
DeepSeek-OCR se basa en una arquitectura VLM innovadora, unificada y de extremo a extremo, que se centra en utilizar la modalidad visual como un medio de compresión de texto de alta eficiencia.
🖼️ Compresión Óptica de Contexto
DeepSeek-OCR aprovecha el mapeo óptico 2D para comprimir contenido textual complejo directamente en píxeles visuales, representados por un número mínimo de tokens visuales. Esta capacidad implica que una imagen de documento puede transmitir información rica utilizando significativamente menos tokens que su texto sin formato equivalente, logrando tasas de compresión notablemente más altas. Esto reduce drásticamente la longitud del contexto que los LLMs deben procesar.
⚡ Arquitectura Dual Altamente Eficiente
El modelo se compone de dos componentes principales: el DeepEncoder y el decodificador DeepSeek3B-MoE-A570M. El DeepEncoder está diseñado específicamente para mantener una baja activación computacional incluso con entradas de alta resolución, al tiempo que logra altas tasas de compresión. El decodificador Mixture-of-Experts (MoE), a pesar de poseer 3 mil millones de parámetros, activa dinámicamente solo los expertos necesarios, lo que resulta en un bajo costo operativo de solo 570 millones de parámetros activos durante el tiempo de ejecución.
🎯 Precisión Superior con Alta Compresión
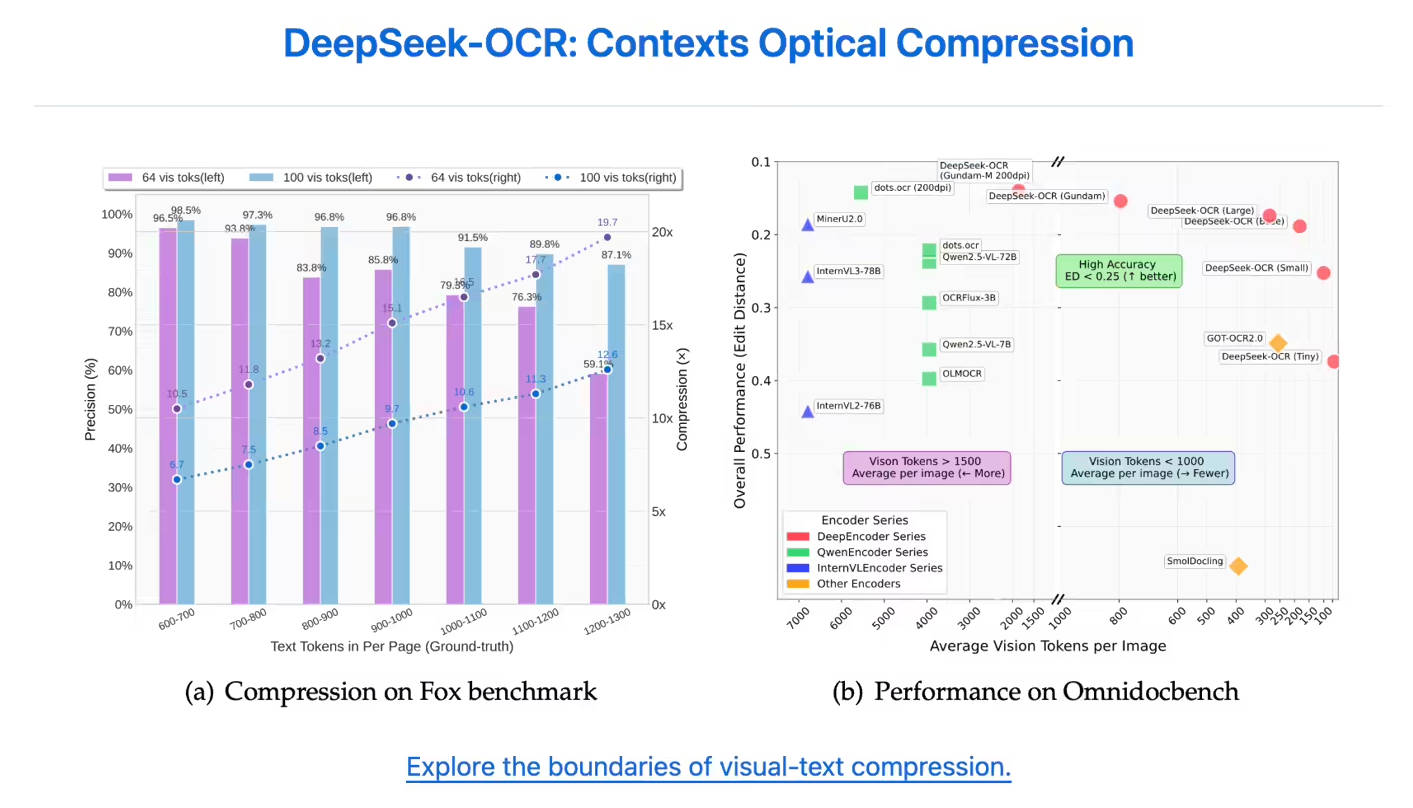
El modelo demuestra una retención de precisión excepcional incluso bajo una compresión agresiva. Cuando el contenido textual se comprime hasta 10 veces (una relación de compresión de 10×), la precisión del OCR se mantiene alta, alcanzando hasta un 97%. Incluso al llevar los límites a una relación de compresión de 20×, se obtiene una precisión de aproximadamente el 60%, lo que muestra su importante potencial para la compresión de documentos históricos y la investigación de mecanismos de memoria de LLMs.
🧠 Comprensión Local y Global Combinada
El DeepEncoder combina de forma innovadora las capacidades de percepción local de SAM-base con la comprensión estructural global de CLIP-large. Este enfoque dual permite que el modelo actúe como un revisor experto, capaz de identificar con precisión las características detalladas de los caracteres (atención local) al mismo tiempo que capta el diseño y la estructura general del documento (atención global), asegurando una captura integral de datos independientemente de la complejidad.
Casos de Uso
DeepSeek-OCR ofrece beneficios tangibles en diversas industrias que exigen un procesamiento de documentos de alto rendimiento y una extracción de datos precisa.
1. Aceleración de la Generación de Datos para LLM/VLM
Para los equipos de desarrollo de IA, DeepSeek-OCR proporciona un rendimiento de datos a escala industrial. En un entorno de producción, una única GPU A100-40G puede generar más de 200,000 páginas de datos de entrenamiento de alta calidad para LLM o VLM diariamente. Esta eficiencia acorta drásticamente los ciclos de desarrollo y reduce el costo de entrenar modelos fundacionales de próxima generación.
2. Digitalización Empresarial a Gran Escala
En finanzas y atención médica, donde son comunes documentos como informes financieros extensos, registros médicos históricos y escritos legales, DeepSeek-OCR convierte instantáneamente archivos de documentos masivos y no estructurados en datos estructurados. Por ejemplo, puede procesar artículos académicos complejos utilizando solo alrededor de 400 tokens visuales, conservando con precisión elementos especializados como fórmulas matemáticas y ecuaciones químicas.
3. Manejo de Documentos Complejos y Multilingües
El modelo exhibe una notable adaptabilidad, manejando con facilidad formatos altamente complejos. Identifica y procesa con precisión contenido especializado y mixto, incluidos documentos multilingües que contienen escrituras como el árabe y el bengalí, o diapositivas de presentación simples que requieren solo 64 tokens visuales para una restauración precisa del contenido.
Ventajas Únicas
DeepSeek-OCR ofrece ventajas distintivas y verificables sobre las soluciones de procesamiento de documentos y OCR existentes, específicamente en eficiencia de tokens y rendimiento de producción.
| Ventaja | Beneficio y Fundamentación |
|---|---|
| Eficiencia de Tokens Inigualable | DeepSeek-OCR requiere muchos menos tokens para representar con precisión el contenido de una página. En la prueba OmniDocBench, superó a GOT-OCR2.0 utilizando solo 100 tokens visuales (en comparación con los 256 tokens por página de GOT-OCR2.0) y superó a MinerU2.0 utilizando menos de 800 tokens (MinerU2.0 requiere más de 6,000 tokens por página). |
| Alto Rendimiento Rentable | La arquitectura MoE permite que el modelo de 3 mil millones de parámetros opere con un costo computacional de solo 570 millones de parámetros activos. Esta asignación dinámica de recursos posibilita una producción a gran escala (200 mil páginas procesadas diariamente en una sola GPU A100), equivalente a la producción de aproximadamente 100 empleados profesionales de entrada de datos. |
| Manejo de Contexto a Prueba de Futuro | La característica de "memoria visual" demostrada por la técnica de compresión óptica ofrece un enfoque fundamentalmente nuevo para superar los límites tradicionales de la longitud de la ventana de contexto inherentes a las arquitecturas de LLM actuales. |
Conclusión
DeepSeek-OCR representa un avance significativo en el campo del procesamiento de lenguaje visual, yendo más allá del OCR básico para ofrecer una solución potente y eficiente para la compresión de contexto largo. Al aprovechar la modalidad visual, se obtiene la capacidad de procesar conjuntos de datos masivos de forma más rápida, precisa y con un costo computacional menor de lo que era posible anteriormente. Explore cómo DeepSeek-OCR puede revolucionar el enfoque de su organización hacia la digitalización de documentos a gran escala y las canalizaciones de entrenamiento de IA.
More information on DeepSeek-OCR
DeepSeek-OCR was manually vetted by our editorial team and was first featured on 2025-10-20.
DeepSeek-OCR Alternativas
Más Alternativas-

DeepSeek-VL2, un modelo de visión-lenguaje de DeepSeek-AI, procesa imágenes de alta resolución, ofrece respuestas rápidas con MLA y sobresale en diversas tareas visuales como VQA y OCR. Ideal para investigadores, desarrolladores y analistas de BI.
-

DeepSeek-V2: modelo MoE de 236 mil millones. Rendimiento líder. Muy asequible. Experiencia inigualable. Chat y API actualizados al modelo más reciente.
-

-

DeepSearcher: Gestión del conocimiento con IA para los datos privados de su empresa. Acceda a respuestas e información clave de forma segura y precisa, directamente de sus documentos internos, gracias a LLMs flexibles.
-
