
What is DeepSeek-OCR?
DeepSeek-OCR 是一個新穎的視覺語言模型 (VLM),旨在顯著提升大型語言模型 (LLM) 處理長上下文文件時的效率。透過開創性的「上下文光學壓縮」技術,這個擁有 30 億參數的模型解決了將海量文檔檔案數位化並分析的龐大計算挑戰,讓研究人員和企業能夠以前所未有的速度和準確性處理大量數據。您現在可以有效地將視覺文件表示轉換為高度壓縮、高保真度的數據,適用於下一代 AI 訓練和應用。
關鍵特色
DeepSeek-OCR 採用創新的統一端到端 VLM 架構,專注於將視覺模態作為高效的文本壓縮介質。
🖼️ 光學上下文壓縮
DeepSeek-OCR 利用光學 2D 映射技術,將複雜的文本內容直接壓縮成視覺像素,並由最少量的視覺標記(tokens)表示。這項技術意味著文件圖像能夠以遠少於其原始文本等效量的標記,傳達豐富的資訊,實現顯著更高的壓縮率。這大幅降低了 LLM 需要處理的上下文長度。
⚡ 高效雙架構
該模型由兩個核心組件組成:分別是 DeepEncoder 和 DeepSeek3B-MoE-A570M 解碼器。DeepEncoder 專門設計用於在高解析度輸入下仍能保持較低的計算活化成本,同時實現高壓縮比。儘管其 Mixture-of-Experts (MoE) 解碼器擁有 30 億個參數,但它會動態地僅啟用必要的專家,因此在運行時的運營成本僅為 5.7 億個活動參數。
🎯 高壓縮下仍具卓越精準度
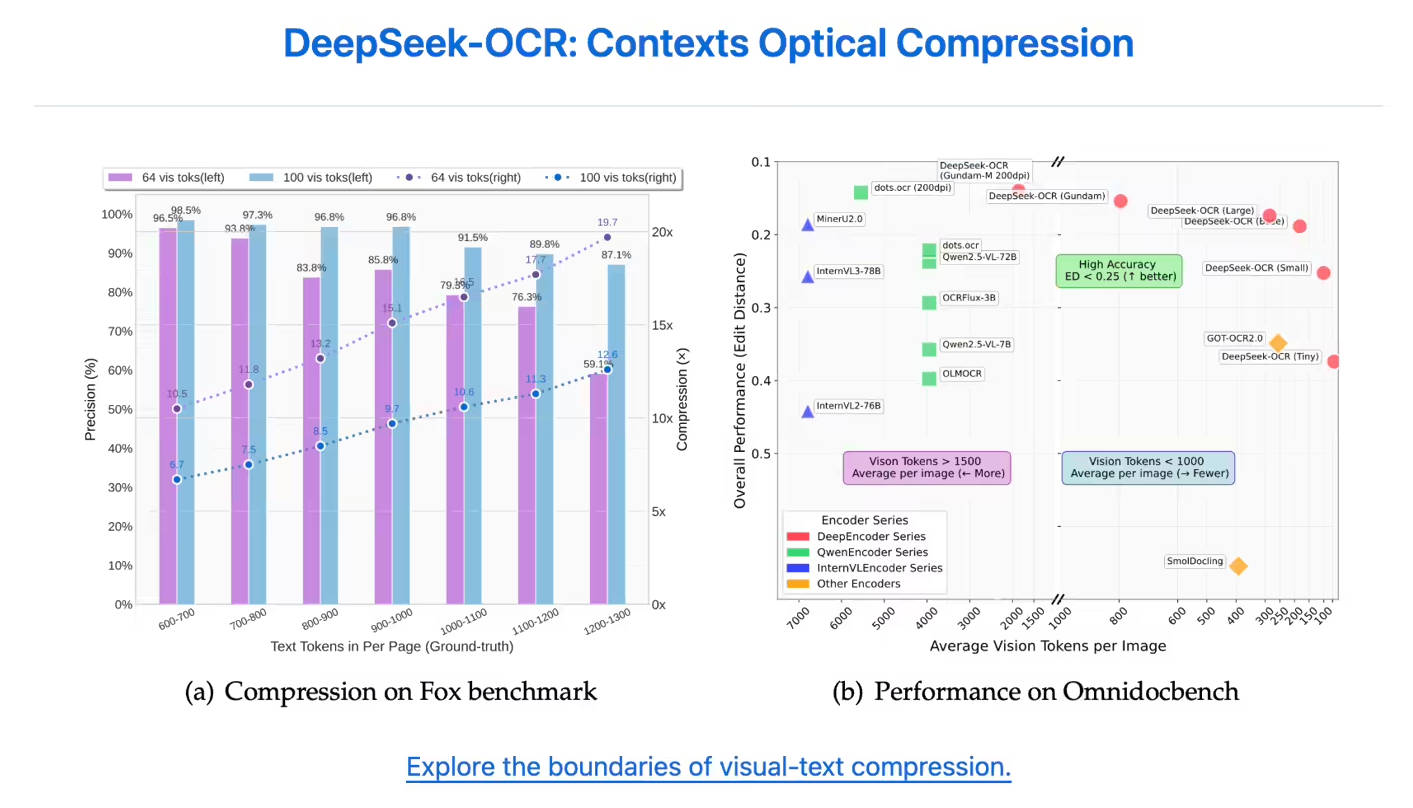
即使在積極的壓縮下,該模型也能展現卓越的準確性保持能力。當文本內容被壓縮高達 10 倍 (10 倍壓縮比)時,其 OCR 精準度依然保持高水準,準確度可達 97%。即使將壓縮比推至 20 倍,仍能達到約 60% 的準確度,這顯示其在歷史文檔壓縮和 LLM 記憶機制研究方面具有巨大潛力。
🧠 結合局部與全局理解
DeepEncoder 創新地結合了 SAM-base 的局部感知能力與 CLIP-large 的全局結構理解能力。這種雙重方法讓模型能夠像一位專家審閱者,精確識別詳細的字元特徵(局部關注),同時掌握整體文件版面和結構(全局關注),無論複雜度如何,都能確保全面性的數據擷取。
應用情境
DeepSeek-OCR 為各行各業帶來實質效益,這些行業對高吞吐量文件處理和精確數據擷取有著極高要求。
1. 加速 LLM/VLM 數據生成
對於 AI 開發團隊而言,DeepSeek-OCR 提供了工業級別的數據吞吐量。在生產環境中,單張 A100-40G GPU 每天可生成超過 20 萬頁 的高品質 LLM 或 VLM 訓練數據。這種效率顯著縮短了開發週期,並降低了訓練下一代基礎模型的成本。
2. 大規模企業數位化
在金融和醫療保健領域,長篇財務報告、歷史醫療記錄和法律摘要等文件屢見不鮮,DeepSeek-OCR 能夠即時將海量非結構化文檔檔案轉換為結構化數據。例如,它只需約 400 個視覺標記即可處理複雜的學術論文,同時精確保留數學公式和化學方程式等專業元素。
3. 處理複雜和多語言文件
該模型展現出卓越的適應性,可輕鬆處理高度複雜的格式。它能精確識別和處理專業及混合內容,包括含有阿拉伯語和孟加拉語等文字的多語言文件,或僅需 64 個視覺標記即可精確恢復內容的簡單演示文稿幻燈片。
獨特優勢
DeepSeek-OCR 相較於現有的文件處理和 OCR 解決方案,提供了獨特且可驗證的優勢,特別是在標記效率和生產吞吐量方面。
| 優勢 | 效益與佐證 |
|---|---|
| 無與倫比的標記效率 | DeepSeek-OCR 僅需極少的標記即可精確表示頁面內容。在 OmniDocBench 測試中,它僅使用 100 個視覺標記(相較於 GOT-OCR2.0 每頁需 256 個標記)便超越了 GOT-OCR2.0,並以不到 800 個標記(MinerU2.0 每頁需要超過 6,000 個標記)的表現擊敗了 MinerU2.0。 |
| 高性價比高效能 | MoE 架構使 30 億參數模型能夠以僅 5.7 億個活動參數的計算成本運行。這種動態資源分配實現了大規模生產——單一 A100 GPU 每天處理 20 萬頁,相當於約 100 名專業數據輸入員的工作量。 |
| 面向未來的上下文處理能力 | 光學壓縮技術所展現的「視覺記憶」特性,為突破當前 LLM 架構中固有的傳統上下文視窗長度限制,提供了一種全新的根本性方法。 |
結論
DeepSeek-OCR 代表了視覺語言處理領域的重大進展,超越了基本的 OCR 技術,為長上下文壓縮提供了強大而高效的解決方案。透過利用視覺模態,您將獲得比以往更快、更準確、計算成本更低地處理海量數據集的能力。探索 DeepSeek-OCR 如何徹底改變您的組織在大規模文件數位化和 AI 訓練流程方面的方法。
More information on DeepSeek-OCR
DeepSeek-OCR was manually vetted by our editorial team and was first featured on 2025-10-20.
DeepSeek-OCR 替代方案
更多 替代方案-

DeepSeek-VL2 是由 DeepSeek-AI 開發的視覺語言模型,它能夠處理高解析度的圖像,並透過 MLA 提供快速的回應。DeepSeek-VL2 在各種視覺任務中表現出色,例如 VQA 和 OCR。對於研究人員、開發者和 BI 分析師來說,DeepSeek-VL2 是一個理想的選擇。
-

-

-

-
