
What is DeepSeek-OCR?
DeepSeek-OCR est un nouveau Modèle de Langage Visuel (VLM) conçu pour améliorer considérablement l'efficacité du traitement des documents à contexte long pour les grands modèles de langage (LLM). En innovant avec une technique appelée Contexts Optical Compression, ce modèle à 3 milliards de paramètres relève le défi computationnel massif de la numérisation et de l'analyse d'archives documentaires étendues, permettant aux chercheurs et aux entreprises de gérer de vastes quantités de données avec une rapidité et une précision sans précédent. Vous pouvez désormais transformer efficacement les représentations visuelles de documents en données hautement compressées et de haute fidélité, adaptées à la formation et à l'application d'IA de nouvelle génération.
Fonctionnalités Clés
DeepSeek-OCR est bâti sur une architecture VLM innovante, unifiée et de bout en bout, qui met l'accent sur l'utilisation de la modalité visuelle comme un moyen de compression de texte à haute efficacité.
🖼️ Compression Optique de Contexte
DeepSeek-OCR utilise la cartographie optique 2D pour compresser le contenu textuel complexe directement en pixels visuels, représentés par un nombre minimal de jetons visuels. Cette approche signifie qu'une image de document peut véhiculer des informations riches en utilisant significativement moins de jetons que son équivalent en texte brut, atteignant ainsi des taux de compression bien plus élevés. Cela réduit drastiquement la longueur du contexte que les LLM doivent traiter.
⚡ Architecture Duale Hautement Efficace
Le modèle est composé de deux composants centraux : le DeepEncoder et le décodeur DeepSeek3B-MoE-A570M. Le DeepEncoder est spécifiquement conçu pour maintenir une faible activation computationnelle, même avec des entrées haute résolution, tout en atteignant des taux de compression élevés. Le décodeur Mixture-of-Experts (MoE), bien que possédant 3 milliards de paramètres, n'active dynamiquement que les experts nécessaires, ce qui se traduit par un faible coût opérationnel de seulement 570 millions de paramètres actifs en temps réel.
🎯 Précision Supérieure avec une Compression Élevée
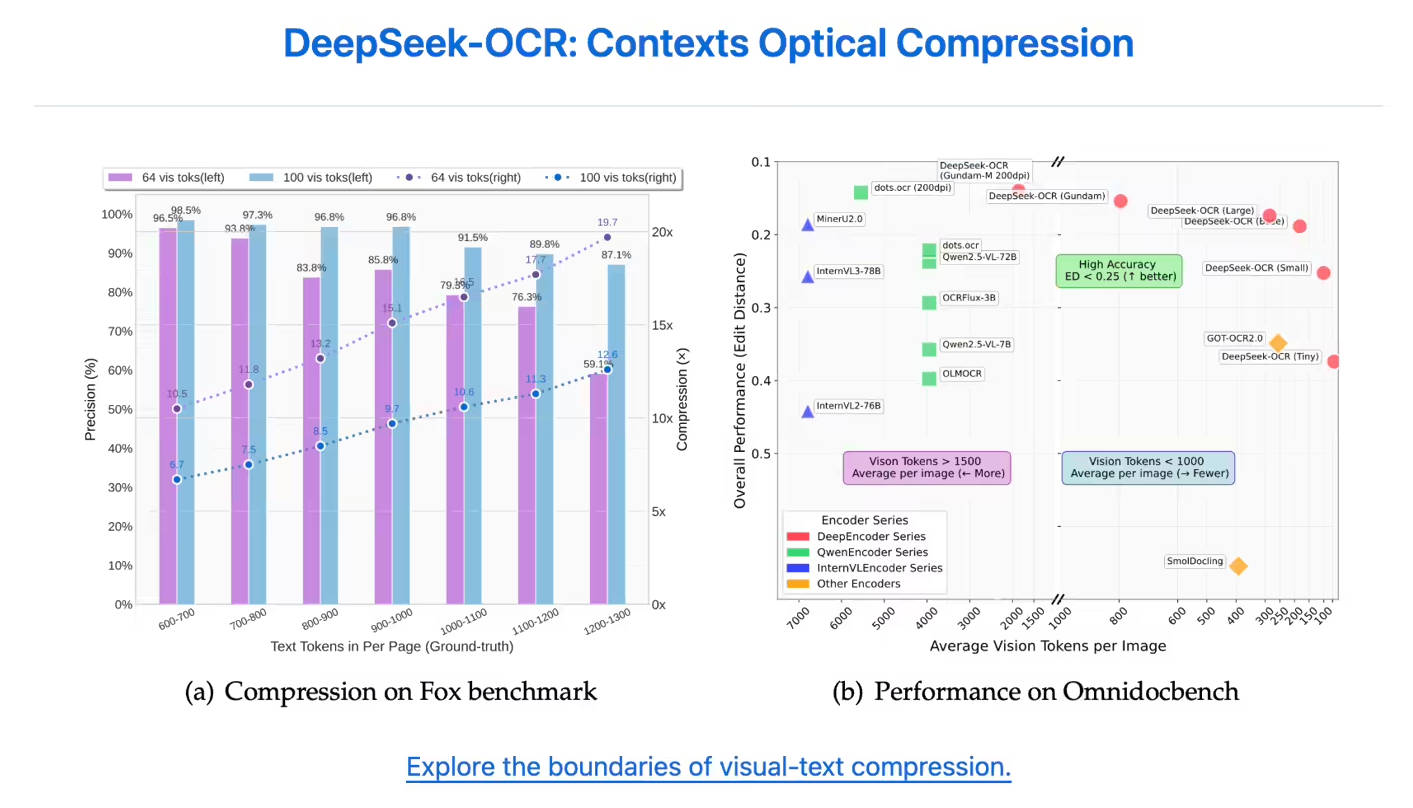
Le modèle démontre une rétention de précision exceptionnelle, même sous une compression agressive. Lorsque le contenu textuel est compressé jusqu'à 10 fois (taux de compression de 10×), la précision de l'OCR reste élevée, atteignant jusqu'à 97 %. Même en repoussant les limites à un taux de compression de 20×, la précision s'élève encore à environ 60 %, démontrant son potentiel significatif pour la compression de documents historiques et la recherche sur les mécanismes de mémoire des LLM.
🧠 Compréhension Locale et Globale Combinée
Le DeepEncoder combine de manière innovante les capacités de perception locale de SAM-base avec la compréhension structurelle globale de CLIP-large. Cette approche duale permet au modèle d'agir comme un examinateur expert, capable d'identifier précisément les caractéristiques détaillées des caractères (attention locale) tout en saisissant simultanément la disposition et la structure globales du document (attention globale), assurant une capture de données exhaustive quelle que soit la complexité.
Cas d'Usage
DeepSeek-OCR offre des avantages concrets dans diverses industries exigeant un traitement de documents à haut débit et une extraction de données précise.
1. Accélération de la Génération de Données LLM/VLM
Pour les équipes de développement d'IA, DeepSeek-OCR fournit un débit de données à l'échelle industrielle. Dans un environnement de production, un seul GPU A100-40G peut générer plus de 200 000 pages de données d'entraînement LLM ou VLM de haute qualité par jour. Cette efficacité raccourcit considérablement les cycles de développement et réduit le coût de la formation des modèles fondamentaux de nouvelle génération.
2. Numérisation d'Entreprise à Grande Échelle
Dans les secteurs de la finance et de la santé, où les documents tels que les rapports financiers volumineux, les dossiers médicaux historiques et les mémoires juridiques sont courants, DeepSeek-OCR convertit instantanément des archives documentaires massives et non structurées en données structurées. Par exemple, il peut traiter des articles universitaires complexes en utilisant seulement environ 400 jetons visuels tout en préservant avec précision des éléments spécialisés comme les formules mathématiques et les équations chimiques.
3. Gestion de Documents Complexes et Multilingues
Le modèle fait preuve d'une adaptabilité remarquable, gérant facilement des formats très complexes. Il identifie et traite avec précision le contenu spécialisé et mixte, y compris les documents multilingues contenant des écritures comme l'arabe et le bengali, ou de simples diapositives de présentation qui ne nécessitent que 64 jetons visuels pour une restauration précise du contenu.
Avantages Uniques
DeepSeek-OCR offre des avantages distincts et vérifiables par rapport aux solutions existantes de traitement de documents et d'OCR, notamment en termes d'efficacité des jetons et de débit de production.
| Avantage | Bénéfice & Justification |
|---|---|
| Efficacité Inégalée des Jetons | DeepSeek-OCR nécessite beaucoup moins de jetons pour représenter fidèlement le contenu d'une page. Lors du test OmniDocBench, il a surpassé GOT-OCR2.0 en n'utilisant que 100 jetons visuels (contre 256 jetons par page pour GOT-OCR2.0) et a surperformé MinerU2.0 en utilisant moins de 800 jetons (MinerU2.0 en exige plus de 6 000 par page). |
| Performance Élevée et Économique | L'architecture MoE permet au modèle à 3 milliards de paramètres de fonctionner avec un coût de calcul équivalent à seulement 570 millions de paramètres actifs. Cette allocation dynamique des ressources permet une production à grande échelle — 200 000 pages traitées quotidiennement sur un seul GPU A100 — équivalant au travail d'environ 100 opérateurs de saisie de données professionnels. |
| Gestion du Contexte Pérenne | La caractéristique de "mémoire visuelle" démontrée par la technique de compression optique offre une approche fondamentalement nouvelle pour briser les limites traditionnelles de longueur de fenêtre contextuelle inhérentes aux architectures LLM actuelles. |
Conclusion
DeepSeek-OCR représente une avancée significative dans le domaine du traitement du langage visuel, allant au-delà de l'OCR de base pour offrir une solution puissante et efficace de compression à contexte long. En tirant parti de la modalité visuelle, vous obtenez la capacité de traiter des ensembles de données massifs plus rapidement, plus précisément et à un coût de calcul inférieur à ce qui était auparavant possible. Découvrez comment DeepSeek-OCR peut révolutionner l'approche de votre organisation en matière de numérisation de documents à grande échelle et de pipelines d'entraînement d'IA.
More information on DeepSeek-OCR
DeepSeek-OCR was manually vetted by our editorial team and was first featured on 2025-10-20.
DeepSeek-OCR Alternatives
Plus Alternatives-

DeepSeek-VL2, un modèle vision-langage développé par DeepSeek-AI, traite des images haute résolution, offre des réponses rapides grâce à MLA et excelle dans diverses tâches visuelles telles que le VQA et l'OCR. Il est idéal pour les chercheurs, les développeurs et les analystes BI.
-

DeepSeek-V2 : modèle MoE de 236 milliards. Performances de pointe. Ultra abordable. Expérience inégalée. Chat et API mis à jour avec le dernier modèle.
-

-

DeepSearcher : Gestion des connaissances par IA pour les données d'entreprise privées. Obtenez des réponses et des éclairages fiables et précis à partir de vos documents internes, grâce à des LLM flexibles.
-
