
What is DeepSeek-OCR?
DeepSeek-OCR は、大規模言語モデル(LLM)向けの長文コンテキスト文書の処理効率を劇的に向上させるために開発された、革新的なVisual Language Model(VLM)です。Contexts Optical Compression と呼ばれる独自技術を開発することで、この30億パラメータモデルは、広範な文書アーカイブのデジタル化と分析における膨大な計算上の課題を解決し、研究者や企業がかつてない速度と精度で膨大な量のデータを扱えるようにします。これにより、視覚的な文書表現を、次世代AIのトレーニングと応用に適した高圧縮かつ高忠実度のデータに効率的に変換することが可能になります。
主要機能
DeepSeek-OCR は、革新的で統一されたエンドツーエンドのVLMアーキテクチャに基づいて構築されており、視覚モダリティを高効率のテキスト圧縮媒体として活用することに焦点を当てています。
🖼️ オプティカルコンテキスト圧縮
DeepSeek-OCR は、光学2Dマッピングを活用し、複雑なテキストコンテンツを最小限の視覚トークンで表現される視覚ピクセルに直接圧縮します。この洞察により、文書画像は、同等の生テキストよりも大幅に少ないトークンで豊富な情報を伝達でき、はるかに高い圧縮率を実現します。これにより、LLMが処理すべきコンテキスト長が劇的に短縮されます。
⚡ 高効率なデュアルアーキテクチャ
本モデルは、**DeepEncoder** と **DeepSeek3B-MoE-A570M** デコーダという2つの主要コンポーネントで構成されています。DeepEncoder は、高解像度入力に対しても低い計算活性化を維持しながら、高い圧縮率を達成するように特別に設計されています。Mixture-of-Experts(MoE)デコーダは、30億のパラメータを持つにもかかわらず、必要なエキスパートのみを動的に活性化させ、実行時にはわずか5億7千万のアクティブパラメータという低い運用コストで済みます。
🎯 高圧縮下でも優れた精度
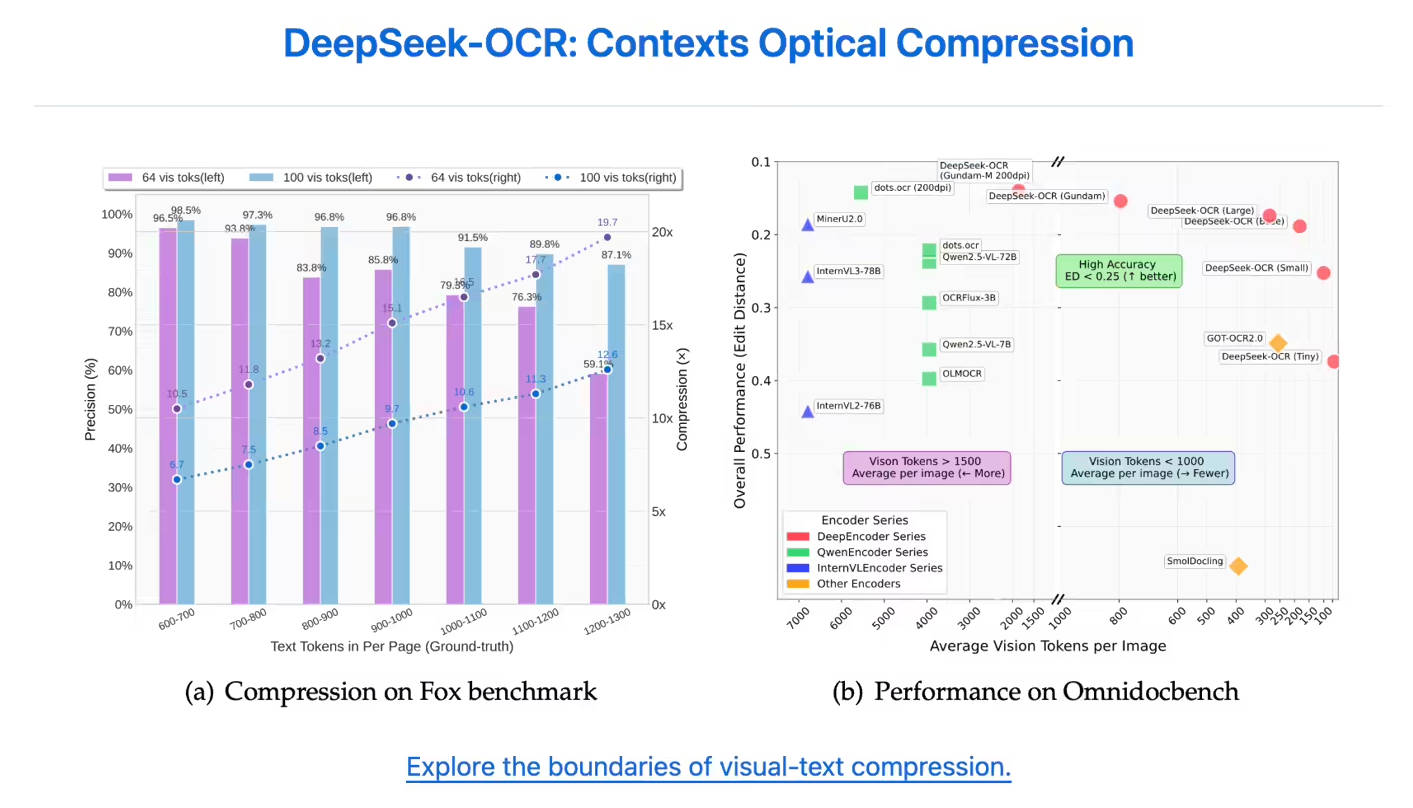
本モデルは、積極的な圧縮下でも卓越した精度保持能力を発揮します。テキストコンテンツを**10倍**(10倍の圧縮率)まで圧縮した場合でも、OCR精度は高く維持され、最大97%の精度を達成します。20倍の圧縮率まで限界を押し広げても、約60%の精度が得られ、歴史的文書の圧縮やLLMのメモリメカニズム研究において、その大きな可能性を示しています。
🧠 局所的理解と大域的理解の融合
DeepEncoder は、SAM-baseの局所的な知覚能力とCLIP-largeの全体的な構造理解を革新的に組み合わせます。この二重アプローチにより、モデルは専門家レビュアーのように機能し、詳細な文字特徴(局所的アテンション)を正確に識別すると同時に、文書全体のレイアウトと構造(大域的アテンション)を把握することで、複雑さに関わらず包括的なデータ取得を保証します。
ユースケース
DeepSeek-OCR は、高スループットの文書処理と正確なデータ抽出が求められる様々な業界に具体的な利益をもたらします。
1. LLM/VLMデータ生成の加速
AI開発チームにとって、DeepSeek-OCR は産業規模のデータスループットを提供します。本番環境において、1つのA100-40G GPUで毎日**20万ページ**以上の高品質なLLMまたはVLMトレーニングデータを生成できます。この効率性により、開発サイクルが劇的に短縮され、次世代基盤モデルのトレーニングコストが削減されます。
2. 大規模な企業デジタル化
長大な財務報告書、過去の医療記録、法的書類などが一般的な金融やヘルスケア分野では、DeepSeek-OCR は、大量の非構造化文書アーカイブを瞬時に構造化データに変換します。例えば、複雑な学術論文をわずか約400の視覚トークンで処理しながら、数式や化学式のような専門的な要素も正確に保持できます。
3. 複雑な多言語文書の処理
本モデルは驚くべき適応性を示し、非常に複雑な形式も容易に処理します。アラビア語やベンガル語のようなスクリプトを含む多言語文書、あるいは正確なコンテンツ復元にわずか64の視覚トークンしか必要としないシンプルなプレゼンテーションスライドなど、特殊で複合的なコンテンツを正確に識別・処理します。
独自の利点
DeepSeek-OCR は、既存の文書処理およびOCRソリューションに対する明確で検証可能な利点を提供します。特にトークン効率と生産スループットにおいて優位性を発揮します。
| 利点 | 利点と根拠 |
|---|---|
| 比類のないトークン効率 | DeepSeek-OCR は、ページのコンテンツを正確に表現するために、はるかに少ないトークンしか必要としません。OmniDocBench テストにおいて、わずか100の視覚トークンを使用し(GOT-OCR2.0は1ページあたり256トークン)、GOT-OCR2.0を凌駕しました。また、800未満のトークンでMinerU2.0(MinerU2.0は1ページあたり6,000トークン以上が必要)を上回りました。 |
| 費用対効果の高い高性能 | MoEアーキテクチャにより、30億パラメータモデルがわずか5億7千万のアクティブパラメータの計算コストで動作することを可能にします。この動的なリソース割り当てにより、単一のA100 GPUで毎日20万ページを処理するという大規模な本番運用が可能となり、これは約100人分のプロのデータ入力作業員に相当する出力です。 |
| 将来性のあるコンテキスト処理 | 光学圧縮技術によって実証された「視覚メモリ」特性は、現在のLLMアーキテクチャに内在する従来のコンテキストウィンドウ長の制限を打ち破る、根本的に新しいアプローチを提供します。 |
結論
DeepSeek-OCR は、視覚言語処理の分野における重要な進歩を象徴しており、基本的なOCRを超え、長文コンテキスト圧縮のための強力で効率的なソリューションを提供します。視覚モダリティを活用することで、以前は不可能だった方法で、膨大なデータセットをより高速に、より正確に、そしてより低い計算コストで処理する能力を獲得できます。DeepSeek-OCR が貴社の大規模な文書デジタル化とAIトレーニングパイプラインへのアプローチをどのように革新できるか、ぜひご検討ください。
More information on DeepSeek-OCR
DeepSeek-OCR was manually vetted by our editorial team and was first featured on 2025-10-20.
DeepSeek-OCR 代替ソフト
もっと見る 代替ソフト-

DeepSeek-AIが開発したビジョン・言語モデル、DeepSeek-VL2は、高解像度画像を処理し、MLAによる高速応答を提供、VQAやOCRなど多様な視覚タスクで優れた性能を発揮します。研究者、開発者、そしてBIアナリストにとって理想的なツールです。
-

DeepSeek-V2: 2360億MoEモデル。業界をリードするパフォーマンス。非常に低価格。他に類を見ない体験。チャットとAPIは最新モデルにアップグレードされています。
-

-

DeepSearcher: 企業内データ向けAIナレッジマネジメント。柔軟なLLMを活用し、企業内の文書からセキュアで正確な回答とインサイトを導き出します。
-
