
What is DeepSeek-OCR?
DeepSeek-OCR 是一款新型视觉语言模型 (VLM),旨在显著提升大型语言模型 (LLM) 对长文本文档的处理效率。通过开创性的“上下文光学压缩”技术,这个拥有30亿参数的模型解决了海量文档档案数字化和分析所面临的巨大计算挑战,使研究人员和企业能够以前所未有的速度和准确性处理海量数据。现在,您可以高效地将视觉文档表示形式转换为高度压缩、高保真的数据,适用于下一代人工智能的训练和应用。
主要特性
DeepSeek-OCR 基于创新、统一的端到端 VLM 架构构建,致力于将视觉模态作为高效文本压缩介质加以利用。
🖼️ 光学上下文压缩
DeepSeek-OCR 利用光学二维映射技术,将复杂的文本内容直接压缩为视觉像素,以最少数量的视觉标记(visual tokens)表示。这一创新意味着,文档图像能够以远少于其原始文本所用的标记数量来传达丰富的信息,从而实现更高的压缩率。这大幅缩短了 LLM 需要处理的上下文长度。
⚡ 高效双重架构
该模型由两个核心组件构成:DeepEncoder 和 DeepSeek3B-MoE-A570M 解码器。DeepEncoder 专门设计用于在高分辨率输入下保持低计算激活,同时实现高压缩比。尽管混合专家 (MoE) 解码器拥有30亿参数,但它能动态激活仅需的专家模块,从而在运行时仅产生5.7亿活跃参数的低运营成本。
🎯 高压缩下的卓越准确性
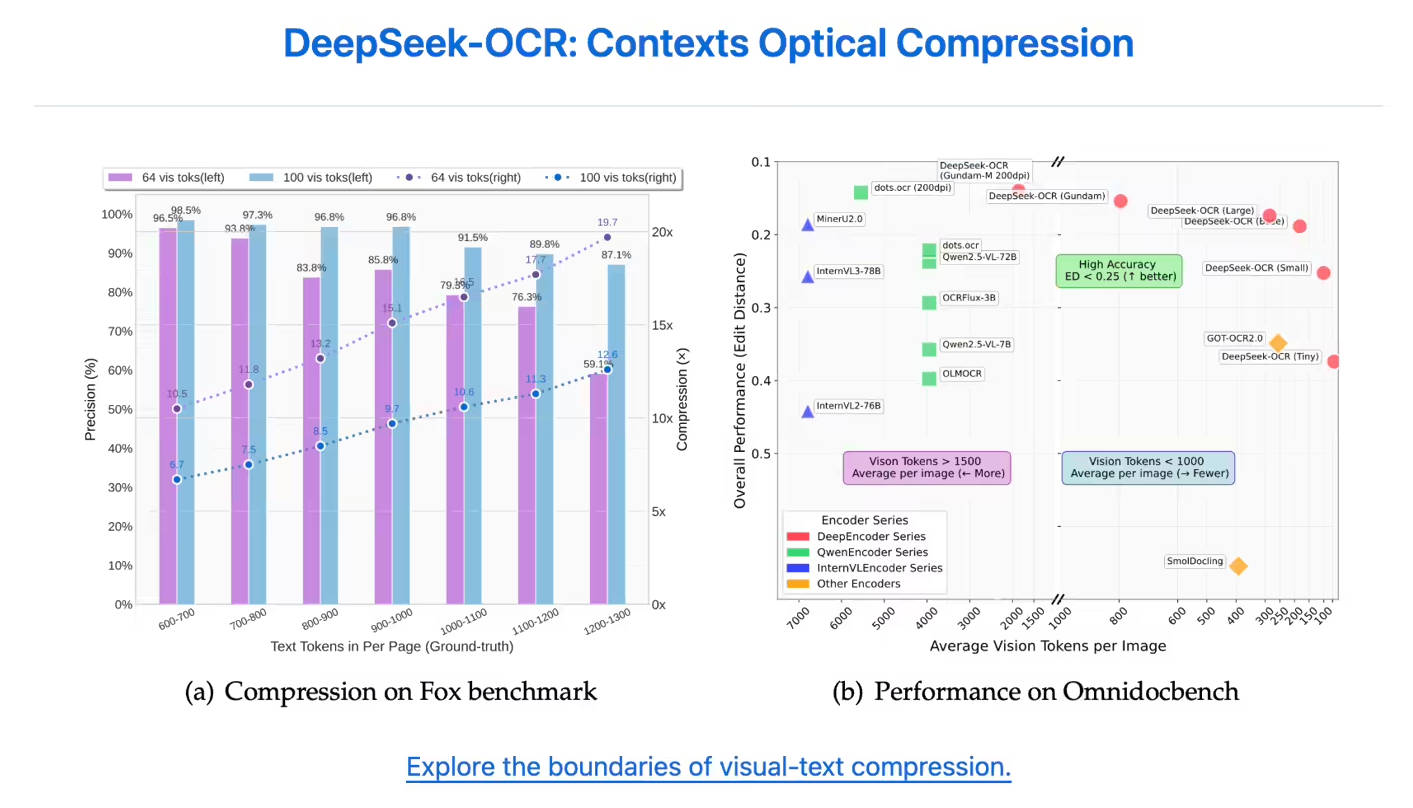
在高强度压缩下,模型仍能保持卓越的准确性。当文本内容被压缩至10倍(10倍压缩比)时,OCR精度依然很高,可达97%。即使将极限推至20倍压缩比,仍能保持约60%的准确率,这充分展示了其在历史文档压缩和 LLM 记忆机制研究方面的巨大潜力。
🧠 融合局部与全局理解能力
DeepEncoder 创新性地融合了 SAM-base 的局部感知能力和 CLIP-large 的全局结构理解能力。这种双重方法使模型能够像一位专家审阅者,能够精确识别详细的字符特征(局部关注),同时掌握文档的整体布局和结构(全局关注),从而确保无论文档多复杂,都能实现全面数据捕获。
应用场景
DeepSeek-OCR 为需要高吞吐量文档处理和精确数据提取的各行各业带来了实实在在的益处。
1. 加速 LLM/VLM 数据生成
对于人工智能开发团队而言,DeepSeek-OCR 提供了工业级的数据吞吐量。在生产环境中,单个 A100-40G GPU 每天可生成超过20万页高质量的 LLM 或 VLM 训练数据。这种高效率显著缩短了开发周期,并降低了训练下一代基础模型的成本。
2. 大规模企业数字化
在金融和医疗保健等行业,冗长的财务报告、历史医疗记录和法律摘要等文档屡见不鲜,DeepSeek-OCR 能够即时将海量的非结构化文档档案转化为结构化数据。例如,它仅需约400个视觉标记即可处理复杂的学术论文,同时精确保留数学公式和化学方程式等专业元素。
3. 处理复杂和多语言文档
该模型展现出卓越的适应性,可轻松处理高度复杂的格式。它能精确识别和处理专业及混合内容,包括包含阿拉伯语和孟加拉语等脚本的多语言文档,或仅需64个视觉标记即可准确恢复内容的简洁演示文稿。
独特优势
与现有文档处理和 OCR 解决方案相比,DeepSeek-OCR 提供了独特且可验证的优势,特别是在标记效率和生产吞吐量方面。
| 优势 | 益处与实证 |
|---|---|
| 无与伦比的标记效率 | DeepSeek-OCR 只需极少的标记即可精确表示页面内容。在 OmniDocBench 测试中,它仅用100个视觉标记就超越了 GOT-OCR2.0(后者每页需256个标记),并以不到800个标记的优势击败了 MinerU2.0(后者每页需6000多个标记)。 |
| 高性价比与卓越性能 | MoE 架构使得这个30亿参数的模型仅以5.7亿活跃参数的计算成本运行。这种动态资源分配实现了大规模生产——单个 A100 GPU 每天可处理20万页,相当于约100名专业数据录入员的工作量。 |
| 面向未来的上下文处理能力 | 光学压缩技术所展现的“视觉记忆”特性,为打破当前 LLM 架构中固有的传统上下文窗口长度限制提供了一种全新的根本性方法。 |
结论
DeepSeek-OCR 代表着视觉语言处理领域的重大进步,它超越了基础的 OCR 技术,为长上下文压缩提供了强大而高效的解决方案。借助视觉模态,您将能够以前所未有的速度、更高的准确性和更低的计算成本处理海量数据集。探索 DeepSeek-OCR 如何彻底改变您的组织在大规模文档数字化和人工智能训练流程中的方法。
More information on DeepSeek-OCR
DeepSeek-OCR was manually vetted by our editorial team and was first featured on 2025-10-20.
DeepSeek-OCR 替代方案
更多 替代方案-

DeepSeek-VL2,是由 DeepSeek-AI 开发的视觉-语言模型,能够处理高分辨率图像,并借助 MLA 技术提供快速响应,在视觉问答 (VQA) 和光学字符识别 (OCR) 等多种视觉任务中表现出色。它是研究人员、开发者和商业智能 (BI) 分析师的理想之选。
-

-

-

-
