
What is DeepSeek-OCR?
DeepSeek-OCR — это новаторская визуальная языковая модель (VLM), разработанная для значительного повышения эффективности обработки документов с длинным контекстом для больших языковых моделей (LLM). Внедряя новаторскую технику, называемую Contexts Optical Compression, эта модель с 3 миллиардами параметров решает масштабную вычислительную проблему оцифровки и анализа обширных архивов документов, позволяя исследователям и предприятиям обрабатывать огромные объемы данных с беспрецедентной скоростью и точностью. Теперь вы можете эффективно преобразовывать визуальные представления документов в сильно сжатые, высокоточные данные, подходящие для обучения и применения ИИ следующего поколения.
Ключевые особенности
DeepSeek-OCR построен на инновационной, унифицированной сквозной архитектуре VLM, сосредоточенной на использовании визуальной модальности в качестве высокоэффективного средства сжатия текста.
🖼️ Оптическое сжатие контекста
DeepSeek-OCR использует оптическое 2D-отображение для сжатия сложного текстового контента непосредственно в визуальные пиксели, представленные минимальным количеством визуальных токенов. Благодаря этому документ-изображение может передавать обширную информацию, используя значительно меньше токенов, чем эквивалентный необработанный текст, достигая значительно более высоких коэффициентов сжатия. Это значительно сокращает длину контекста, которую должны обрабатывать LLM.
⚡ Высокоэффективная двойная архитектура
Модель состоит из двух основных компонентов: DeepEncoder и декодера DeepSeek3B-MoE-A570M. DeepEncoder специально разработан для поддержания низкой вычислительной активации даже при вводе высокого разрешения, при этом обеспечивая высокие коэффициенты сжатия. Декодер Mixture-of-Experts (MoE), хотя и обладает 3 миллиардами параметров, динамически активирует только необходимые эксперты, что приводит к низкой операционной стоимости всего 570 миллионов активных параметров во время выполнения.
🎯 Превосходная точность при высоком сжатии
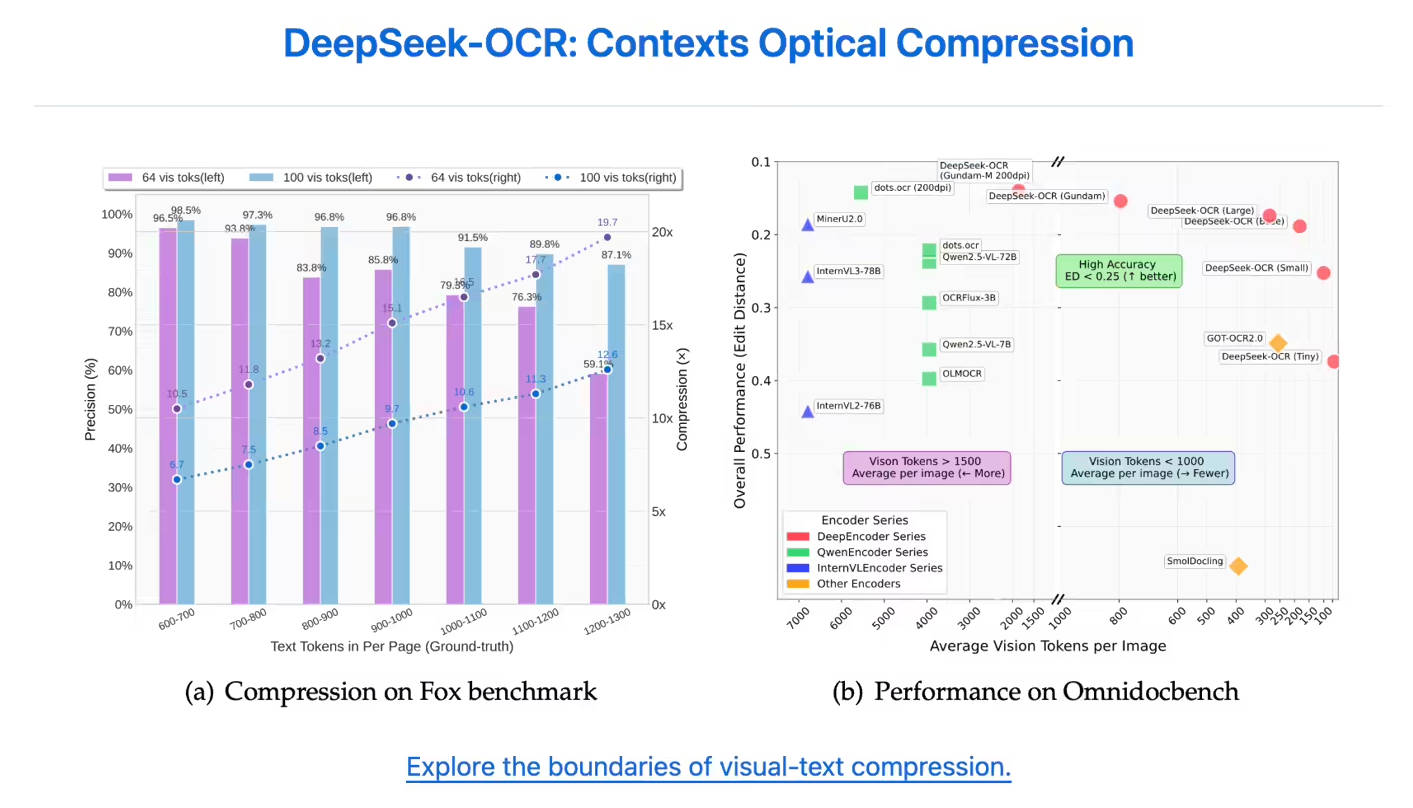
Модель демонстрирует исключительное сохранение точности даже при агрессивном сжатии. Когда текстовый контент сжимается до 10 раз (коэффициент сжатия 10×), точность OCR остается высокой, достигая до 97%. Даже при достижении коэффициента сжатия 20× точность все еще составляет примерно 60%, что демонстрирует его значительный потенциал для сжатия исторических документов и исследований механизмов памяти LLM.
🧠 Сочетание локального и глобального понимания
DeepEncoder инновационно сочетает возможности локального восприятия SAM-base с глобальным структурным пониманием CLIP-large. Этот двойной подход позволяет модели действовать как экспертный рецензент, способный точно идентифицировать детальные особенности символов (локальное внимание), одновременно охватывая общий макет и структуру документа (глобальное внимание), обеспечивая всесторонний сбор данных независимо от их сложности.
Применение
DeepSeek-OCR обеспечивает ощутимые преимущества в различных отраслях, требующих высокопроизводительной обработки документов и точного извлечения данных.
1. Ускорение генерации данных для LLM/VLM
Для команд разработчиков ИИ DeepSeek-OCR обеспечивает пропускную способность данных в промышленных масштабах. В производственной среде один GPU A100-40G может генерировать более 200 000 страниц высококачественных обучающих данных для LLM или VLM ежедневно. Эта эффективность значительно сокращает циклы разработки и снижает стоимость обучения фундаментальных моделей следующего поколения.
2. Крупномасштабная оцифровка для предприятий
В финансовой сфере и здравоохранении, где распространены такие документы, как объемные финансовые отчеты, исторические медицинские записи и юридические справки, DeepSeek-OCR мгновенно преобразует массивные, неструктурированные архивы документов в структурированные данные. Например, он может обрабатывать сложные научные работы, используя всего около 400 визуальных токенов, точно сохраняя при этом специализированные элементы, такие как математические формулы и химические уравнения.
3. Обработка сложных и многоязычных документов
Модель демонстрирует замечательную адаптивность, легко справляясь с очень сложными форматами. Она точно идентифицирует и обрабатывает специализированный и смешанный контент, включая многоязычные документы, содержащие такие письменности, как арабская и бенгальская, или простые слайды презентаций, для точного восстановления контента которых требуется всего 64 визуальных токена.
Уникальные преимущества
DeepSeek-OCR предлагает отчетливые, подтверждаемые преимущества по сравнению с существующими решениями для обработки документов и OCR, особенно в эффективности использования токенов и пропускной способности производства.
| Преимущество | Выгода и обоснование |
|---|---|
| Непревзойденная эффективность токенов | DeepSeek-OCR требует значительно меньше токенов для точного представления содержимого страницы. В тесте OmniDocBench он превзошел GOT-OCR2.0, используя всего 100 визуальных токенов (по сравнению с 256 токенами на страницу у GOT-OCR2.0), и превзошел MinerU2.0, используя менее 800 токенов (MinerU2.0 требует более 6000 токенов на страницу). |
| Экономичная высокая производительность | Архитектура MoE позволяет модели с 3 миллиардами параметров работать с вычислительной стоимостью всего 570 миллионов активных параметров. Такое динамическое распределение ресурсов обеспечивает производство в массовом масштабе — 200 тысяч страниц обрабатывается ежедневно на одном GPU A100, что эквивалентно производительности примерно 100 профессиональных операторов ввода данных. |
| Перспективная обработка контекста | Характеристика "визуальной памяти", продемонстрированная техникой оптического сжатия, предлагает принципиально новый подход к преодолению традиционных ограничений на длину окна контекста, присущих современным архитектурам LLM. |
Заключение
DeepSeek-OCR представляет собой значительный прорыв в области обработки визуального языка, выходя за рамки базового OCR, чтобы предложить мощное и эффективное решение для сжатия длинного контекста. Используя визуальную модальность, вы получаете возможность обрабатывать огромные наборы данных быстрее, точнее и с меньшими вычислительными затратами, чем это было возможно ранее. Узнайте, как DeepSeek-OCR может революционизировать подход вашей организации к крупномасштабной оцифровке документов и конвейерам обучения ИИ.
More information on DeepSeek-OCR
DeepSeek-OCR was manually vetted by our editorial team and was first featured on 2025-10-20.
DeepSeek-OCR Альтернативи
Больше Альтернативи-

DeepSeek-VL2, модель визуального и языкового взаимодействия от DeepSeek-AI, обрабатывает изображения высокого разрешения, обеспечивает быстрые ответы с помощью MLA и показывает превосходные результаты в различных визуальных задачах, таких как VQA и OCR. Идеальна для исследователей, разработчиков и аналитиков бизнес-интеллекта.
-

DeepSeek-V2: 236-миллиардная модель MoE. Передовые характеристики. Ультрадоступно. Несравненный опыт. Чат и API обновлены до последней модели.
-

-

DeepSearcher: Управление знаниями на базе ИИ для внутренних корпоративных данных. Получайте надежные и точные ответы, а также ценные инсайты из ваших внутренних документов с помощью гибких LLM.
-
