
What is DeepSeek-OCR?
DeepSeek-OCR은 거대 언어 모델(LLM)의 장문 맥락 문서 처리 효율성을 획기적으로 향상시키기 위해 개발된 혁신적인 시각 언어 모델(VLM)입니다. Contexts Optical Compression이라는 선구적인 기술을 통해 이 30억(3B) 매개변수 모델은 방대한 문서 아카이브를 디지털화하고 분석하는 데 따르는 엄청난 계산 문제를 해결하여, 연구자와 기업이 전례 없는 속도와 정확성으로 막대한 양의 데이터를 처리할 수 있도록 합니다. 이제 시각적 문서 표현을 차세대 AI 학습 및 응용에 적합한 고도로 압축된 고충실도 데이터로 효율적으로 변환할 수 있습니다.
주요 기능
DeepSeek-OCR은 시각적 모달리티를 고효율 텍스트 압축 매체로 활용하는 데 중점을 둔 혁신적이고 통합된 종단 간 VLM 아키텍처를 기반으로 구축되었습니다.
🖼️ 광학적 컨텍스트 압축
DeepSeek-OCR은 광학 2D 매핑을 활용하여 복잡한 텍스트 콘텐츠를 최소한의 시각 토큰으로 표현되는 시각적 픽셀로 직접 압축합니다. 이러한 통찰은 문서 이미지가 동일한 원본 텍스트보다 훨씬 적은 토큰으로 풍부한 정보를 전달할 수 있음을 의미하며, 훨씬 높은 압축률을 달성합니다. 이는 LLM이 처리해야 하는 컨텍스트 길이를 획기적으로 줄여줍니다.
⚡ 고효율 듀얼 아키텍처
이 모델은 두 가지 핵심 구성 요소인 DeepEncoder와 DeepSeek3B-MoE-A570M 디코더로 이루어져 있습니다. DeepEncoder는 고해상도 입력에서도 낮은 계산 활성화를 유지하면서 높은 압축률을 달성하도록 특별히 설계되었습니다. MoE(Mixture-of-Experts) 디코더는 30억 개의 매개변수를 가지고 있음에도 불구하고 필요한 전문가만 동적으로 활성화하여 런타임 중에는 5억 7천만(570M) 개의 활성 매개변수만으로 낮은 운영 비용을 실현합니다.
🎯 고압축률에서도 뛰어난 정확성
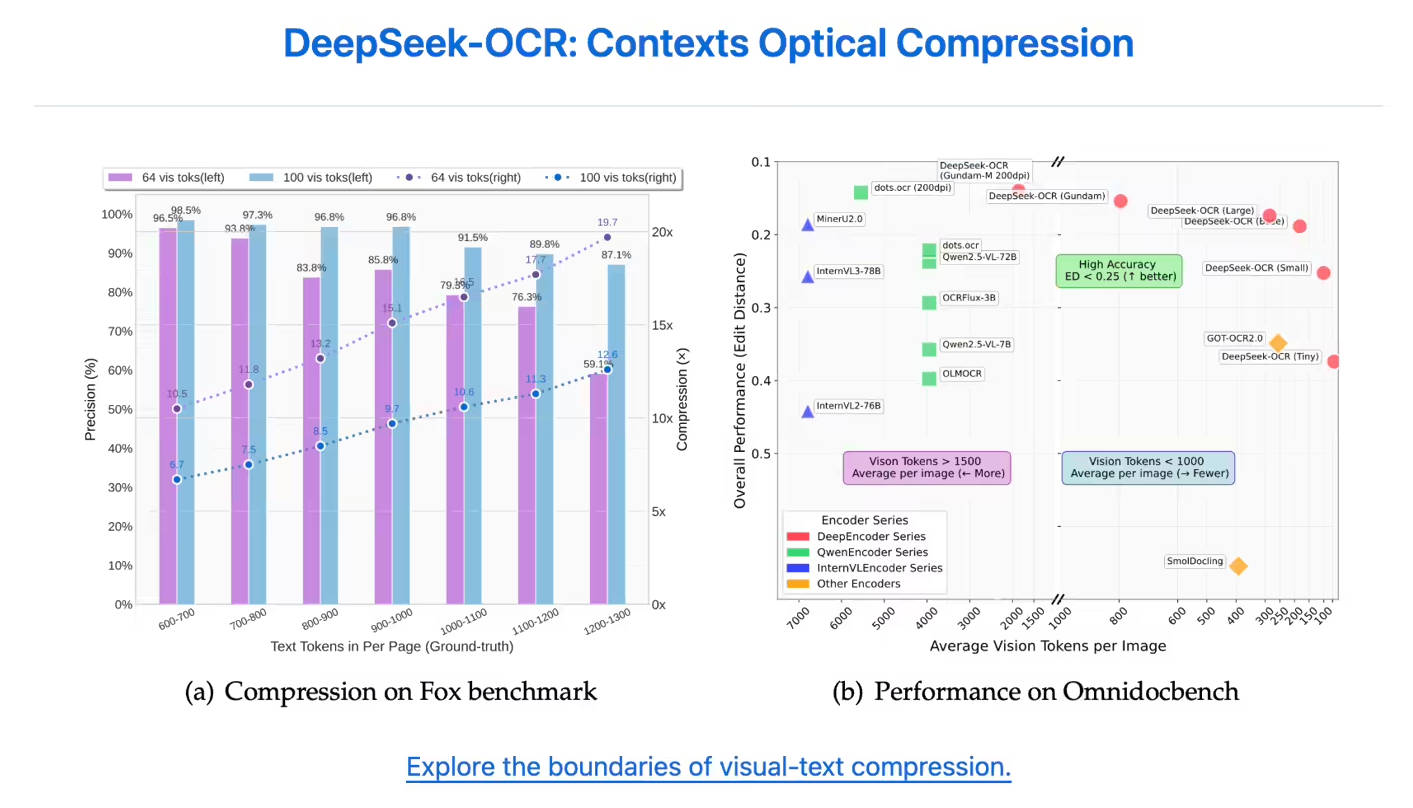
이 모델은 공격적인 압축 조건에서도 뛰어난 정확성 유지율을 보여줍니다. 텍스트 콘텐츠가 최대 10배(10배 압축률)까지 압축될 때, OCR 정밀도는 97%까지 높은 정확도를 유지합니다. 심지어 20배 압축률로 한계를 확장하더라도 여전히 약 60%의 정확도를 제공하며, 이는 역사 문서 압축 및 LLM 메모리 메커니즘 연구에 대한 상당한 잠재력을 보여줍니다.
🧠 로컬 및 전역 이해 결합
DeepEncoder는 SAM-base의 로컬 인식 능력과 CLIP-large의 전역 구조 이해를 혁신적으로 결합합니다. 이러한 이중 접근 방식은 모델이 전문 검토자처럼 작동하게 하여 세부적인 문자 특징(로컬 어텐션)을 정확하게 식별하는 동시에 전체 문서 레이아웃과 구조(전역 어텐션)를 파악할 수 있도록 하며, 복잡성에 관계없이 포괄적인 데이터 캡처를 보장합니다.
활용 사례
DeepSeek-OCR은 높은 처리량의 문서 처리 및 정확한 데이터 추출을 요구하는 다양한 산업 분야에 걸쳐 실질적인 이점을 제공합니다.
1. LLM/VLM 데이터 생성 가속화
AI 개발팀에게 DeepSeek-OCR은 산업 규모의 데이터 처리량을 제공합니다. 프로덕션 환경에서 단일 A100-40G GPU로 하루에 20만 페이지 이상의 고품질 LLM 또는 VLM 학습 데이터를 생성할 수 있습니다. 이러한 효율성은 개발 주기를 획기적으로 단축하고 차세대 기반 모델 학습 비용을 절감합니다.
2. 대규모 기업 디지털화
장문의 재무 보고서, 과거 의료 기록, 법률 문서 등이 흔한 금융 및 헬스케어 분야에서 DeepSeek-OCR은 방대한 비정형 문서 아카이브를 즉시 구조화된 데이터로 변환합니다. 예를 들어, 약 400개의 시각 토큰만 사용하여 복잡한 학술 논문을 처리하면서 수학 공식이나 화학 방정식과 같은 특수 요소를 정확하게 보존할 수 있습니다.
3. 복잡하고 다국어 문서 처리
이 모델은 뛰어난 적응성을 보여주며 매우 복잡한 형식도 쉽게 처리합니다. 아랍어 및 벵골어와 같은 스크립트를 포함하는 다국어 문서, 또는 정확한 콘텐츠 복원에 64개의 시각 토큰만 필요한 간단한 프레젠테이션 슬라이드를 포함하여 특수하고 혼합된 콘텐츠를 정확하게 식별하고 처리합니다.
독보적인 장점
DeepSeek-OCR은 기존 문서 처리 및 OCR 솔루션 대비 독보적이고 검증 가능한 이점을 제공하며, 특히 토큰 효율성과 생산 처리량 측면에서 탁월합니다.
| 장점 | 이점 및 근거 |
|---|---|
| 탁월한 토큰 효율성 | DeepSeek-OCR은 페이지 콘텐츠를 정확하게 표현하는 데 훨씬 적은 토큰이 필요합니다. OmniDocBench 테스트에서 GOT-OCR2.0이 페이지당 256개의 토큰을 사용하는 것에 비해 100개의 시각 토큰만 사용하여 GOT-OCR2.0을 능가했습니다. 또한 MinerU2.0이 페이지당 6,000개 이상의 토큰을 필요로 하는 반면, 800개 미만의 토큰으로 MinerU2.0보다 뛰어난 성능을 보였습니다. |
| 비용 효율적인 고성능 | MoE 아키텍처는 30억(3B) 매개변수 모델이 5억 7천만(570M) 활성 매개변수만의 계산 비용으로 작동할 수 있도록 합니다. 이러한 동적 리소스 할당은 대규모 생산을 가능하게 합니다. 단일 A100 GPU에서 매일 20만 페이지를 처리하며, 이는 약 100명의 전문 데이터 입력 직원의 생산량에 해당합니다. |
| 미래 지향적인 컨텍스트 처리 | 광학 압축 기술로 입증된 "시각적 메모리" 특성은 기존 LLM 아키텍처에 내재된 전통적인 컨텍스트 창 길이의 한계를 깨뜨릴 근본적으로 새로운 접근 방식을 제공합니다. |
결론
DeepSeek-OCR은 시각 언어 처리 분야에서 중요한 진전을 나타내며, 기본적인 OCR을 넘어 장문 컨텍스트 압축을 위한 강력하고 효율적인 솔루션을 제공합니다. 시각적 모달리티를 활용하여 이전보다 훨씬 빠르고 정확하며 낮은 계산 비용으로 방대한 데이터 세트를 처리할 수 있는 능력을 얻게 됩니다. DeepSeek-OCR이 귀사의 대규모 문서 디지털화 및 AI 학습 파이프라인 접근 방식을 어떻게 혁신할 수 있는지 확인해 보세요.
More information on DeepSeek-OCR
DeepSeek-OCR was manually vetted by our editorial team and was first featured on 2025-10-20.
DeepSeek-OCR 대체품
더보기 대체품-

DeepSeek-AI에서 개발한 시각-언어 모델인 DeepSeek-VL2는 고해상도 이미지를 처리하고, MLA를 통해 빠른 응답을 제공하며, VQA 및 OCR과 같은 다양한 시각적 작업에서 뛰어난 성능을 자랑합니다. 연구원, 개발자 및 BI 분석가에게 이상적입니다.
-

DeepSeek-V2: 2360억 MoE 모델. 뛰어난 성능. 매우 저렴한 가격. 타의 추종을 불허하는 경험. 최신 모델로 업그레이드된 채팅 및 API.
-

-

DeepSearcher: 사내 기업 데이터 AI 지식 관리. 유연한 LLM을 활용하여 내부 문서에서 안전하고 정확한 답변과 통찰을 얻으세요.
-
