
2025年最好的 TOON 替代方案
-

优化 AI 成本,掌控全局。Tokenomy 提供精准工具,分析、管理并深入了解主流 LLM 模型的 token 使用情况。计算开销。
-
JsonGPT API 确保任何大型语言模型 (LLM) 生成的 JSON 结构完美、验证无误。杜绝解析错误,大幅节省成本,助您构建稳定可靠的 AI 应用。
-

交付结构化Markdown,可将token使用量削减高达70%,保持语义结构完整,并能无缝融入您的RAG或代理工作流。无需安装,零摩擦——只需上传,即可即刻获得AI优化的输出。
-
ccusage (claude-code-usage) 是一款功能强大的命令行工具,它通过分析您从本地 JSONL 文件中使用的 Claude Code 数据,帮助您深入了解您的令牌消耗模式和预估成本。
-
使用 Tonic Textual,全球首个面向大型语言模型 (LLM) 的安全数据湖,提取、治理、丰富和部署您的非结构化数据,以进行生成式 AI 开发。
-

OpenTools:LLM 工具的统一 API。轻松集成搜索、地图和网页抓取功能。与 LLM 无关,定价透明。立即获取您的 API 密钥!
-

-

ONNX Runtime:随时随地,更快运行机器学习模型。加速跨平台推理与训练。支持 PyTorch、TensorFlow 等框架!
-

Refuel is a platform to clean, structure and transform your data at scale and superhuman quality by leveraging state-of-the-art large language models (LLMs).Refuel Overview
-

Tensorlake Cloud 是一个文档导入和数据编排的平台。它具备类人般的版面理解能力,可以解析现实世界中的各种文档,并支持构建可大规模扩展、随时可投入生产的基于 Python 的工作流。
-

Supertonic: Blazing-fast, on-device text-to-speech for developers. Delivers private, real-time audio synthesis with zero latency & no cloud APIs.
-

-

-

Monkt 将PDF、Word文件、Excel表格、PowerPoint演示文稿和网页转换为结构化的Markdown或JSON格式,同时保留语义结构。通过REST API或网页界面,您可以应用自定义模式、批量处理以及使用预定义模板。
-
TokenDagger:高性能的 TikToken 无缝替代方案。助您在大规模自然语言处理 (NLP) 及代码分词任务中,解锁双倍吞吐量和四倍速度。全面提升您的工作效率。
-
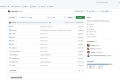
-
-

LoRAX (LoRA eXchange) 是一款创新框架,它使用户能够在单一GPU上运行成千上万个微调模型,从而显著降低了模型部署成本,同时丝毫不影响吞吐量和延迟表现。
-

-
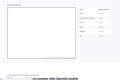
在线工具,用于计算 OpenAI 模型和提示中的标记。确保您的提示符合您正在使用的模型的标记限制。
-

-
AXAR AI 是一个轻量级框架,专为使用 TypeScript 构建生产就绪的智能体应用而设计。它的目标是让您能够沿用熟悉的编程实践,轻松创建健壮、达到生产级水准的 LLM 驱动应用,同时避免不必要的抽象,并大幅降低学习门槛。
-
Tiktokenizer 简化 AI 开发流程,提供实时 token 追踪、应用内可视化工具、无缝 API 集成等功能,助您优化成本和性能。
-

-
-

KTransformers 是由清华大学 KVCache.AI 团队和 QuJing Tech 共同开发的开源项目,旨在优化大型语言模型的推理过程。它能够降低硬件门槛,在 24GB 显存的单 GPU 上运行 6710 亿参数的模型,并提升推理速度(预处理速度高达 286 tokens/s,生成速度高达 14 tokens/s),适用于个人、企业和学术用途。
-

OpenCoder 是一款高性能的开源代码大型语言模型 (LLM)。支持英语和中文,提供完全可复现的流程。非常适合开发者、教育工作者和研究人员。
-

Model2Vec 是一种将任何句子转换器转化为极小静态模型的技术,可将模型大小缩减 15 倍,并将模型速度提升高达 500 倍,性能仅略有下降。
-

OneFileLLM:一款命令行工具,旨在统一大型语言模型(LLM)所需的数据。支持 GitHub、ArXiv、网页抓取等多种数据来源,可输出 XML 格式并进行 Token 计数。告别繁琐的数据整理工作!
-

Token Counter 是一款人工智能工具,旨在计算给定文本中的标记数量。标记是语言模型处理的单个语义单元,例如单词或标点符号。