What is vLLora ?
vLLora是一款核心的、轻量级的调试与可观测性平台,专为复杂的AI智能体工作流设计。它即刻解决了洞察多步LLM调用、工具交互和智能体逻辑的关键挑战。通过OpenAI兼容的端点与主流框架无缝集成,vLLora赋能开发者即时追踪、分析和优化智能体性能,从而确保其可靠性和效率。
主要功能
vLLora提供深度实时的洞察,助您自信地将AI智能体从开发推向生产。
🔍 实时追踪
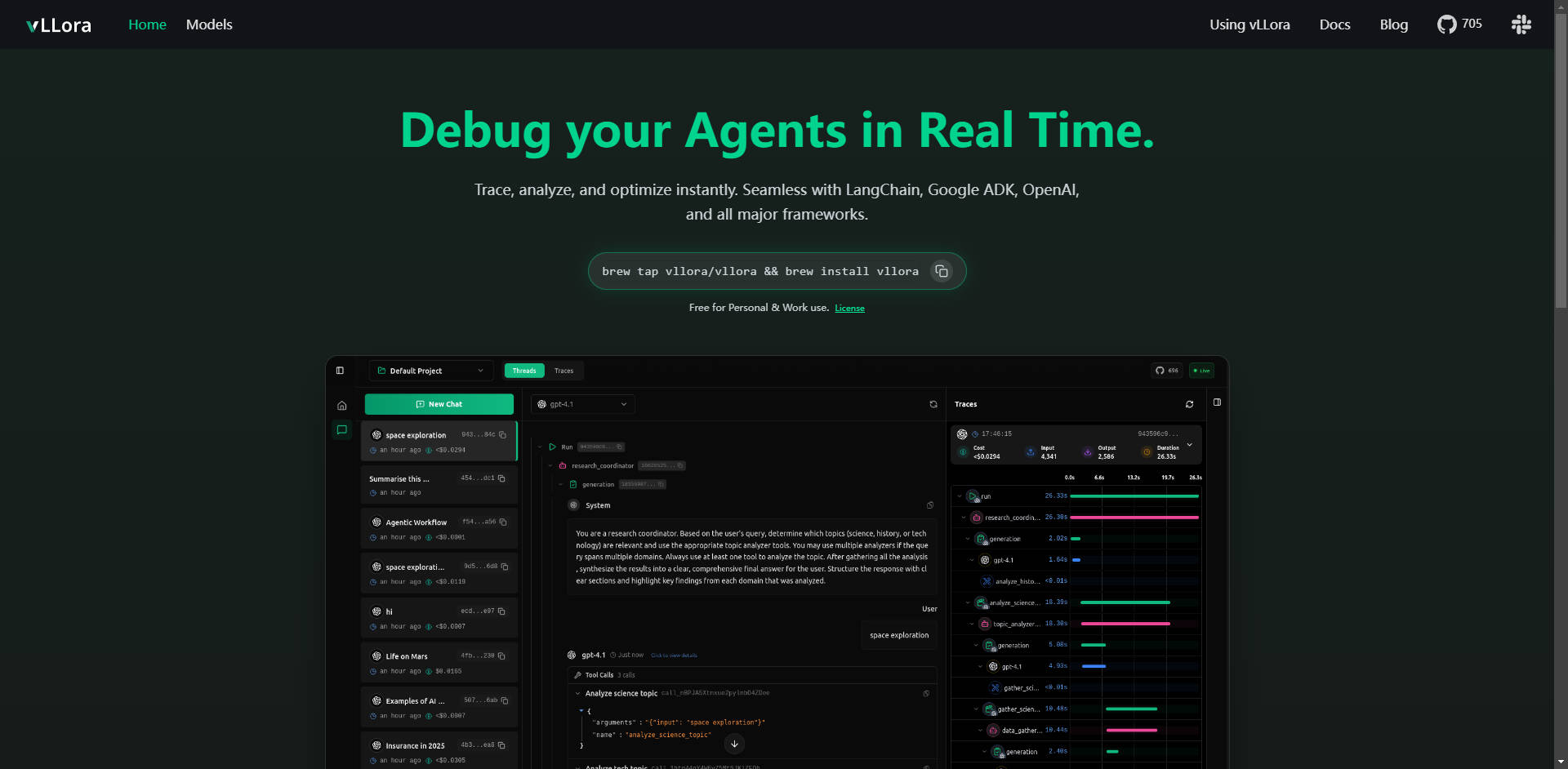
实时监控AI智能体的交互执行过程,为整个工作流提供即时可观测性。您能清晰地看到智能体每时每刻的运行情况——包括每一次模型调用、工具交互和决策——让您在错误或意外行为发生的第一时间就能精准定位。
☁️ 广泛框架兼容性
vLLora与您现有的设置开箱即用,可与LangChain, Google ADK, 和OpenAI Agents SDK等行业领先框架无缝集成。这种广泛的兼容性确保您无需对现有代码库进行大量重构,即可实现深度调试。
📈 深度可观测指标
超越简单的日志记录。vLLora自动收集关键性能洞察,为智能体执行的每一步捕获关于延迟、运营成本和原始模型输出的详细指标。这些数据对于识别瓶颈和优化资源分配至关重要。
⚙️ OpenAI兼容端点,零摩擦设置
vLLora通过OpenAI兼容的聊天完成API运行。通过将智能体的调用路由到vLLora的本地服务器(http://localhost:9090),追踪和调试信息将自动收集,使集成变得像配置新端点URL一样简单便捷。
🌐 广泛模型支持与基准测试
使用您自己的API密钥,即刻访问超过300种不同的模型。vLLora使您能够在单个智能体工作流中混合、匹配并基准测试各种模型,从而快速测试配置,为特定任务选择性能最佳、成本效益最高的LLM。
使用场景
vLLora旨在提升各种复杂智能体类型的开发速度和操作可靠性:
1. 优化编码和自动化智能体
在开发复杂的编码智能体(如Kilocode)时,模型调用、文件操作和外部工具使用的序列可能会变得不透明。借助vLLora,您可以追踪精确的思维链和执行步骤,确保智能体正确理解指令并高效使用其工具,从而显著减少复杂逻辑错误的调试时间。
2. 调试实时语音和对话智能体
对于构建在LiveKit等实时平台上的智能体,延迟至关重要。vLLora允许您查看每次模型推理和工具查找所引入的实时延迟。这使您能够隔离高延迟步骤,并微调模型选择或工具配置,以提供更流畅、近乎即时的用户体验。
3. 成本和性能审计
在生产环境中,智能体成本会迅速攀升。通过集成vLLora,您可以获得每一次交互的Token消耗和相关成本的可见性。这使得团队能够实施预算限制,识别对低风险任务而言不必要的昂贵模型,并优化长期运营效率。
为何选择vLLora?
在评估智能体开发工具时,vLLora在易用性、成本和全面支持方面提供了独特的优势:
- 通过API标准实现原生集成:与需要专有SDK的解决方案不同,vLLora采用广泛使用的OpenAI API标准。这意味着您可以将深度可观测性集成到成熟项目中,而无需改变核心智能体逻辑或进行痛苦的迁移工作。
- 全面的模型灵活性:能够使用您自己的密钥并立即基准测试300多个模型,这促进了真正的创新和成本优化,确保您不会被锁定在单一供应商的生态系统中。
- 易于获取的许可:vLLora个人和工作用途均可**免费**使用,消除了任何规模团队采用一流调试和追踪能力的财务障碍。
结论
vLLora提供了构建可靠、经济高效、高性能AI智能体所需的至关重要的可观测性层。通过简单、标准化的接口提供实时追踪和深度指标,它将智能体开发过程从不透明的故障排除转变为清晰、即时的优化。
立即探索vLLora如何简化您的开发工作流,为您的智能体项目带来清晰明了。
More information on vLLora
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
vLLora was manually vetted by our editorial team and was first featured on 2025-11-13.