
What is BenchLLM by V7?
BenchLLM is a Python-based open-source library designed to help developers evaluate the performance of Large Language Models (LLMs) and AI-powered applications. Whether you're building agents, chains, or custom models, BenchLLM provides the tools to test responses, eliminate flaky outputs, and ensure your AI delivers reliable results.
Key Features
✨ Flexible Testing Strategies
Choose from automated, interactive, or custom evaluation methods. Whether you need semantic similarity checks with GPT models or simple string matching, BenchLLM adapts to your needs.
📊 Generate Quality Reports
Get detailed evaluation reports to monitor model performance, detect regressions, and share insights with your team.
🔧 Seamless Integration
Test your code on the fly with support for OpenAI, Langchain, and other APIs. BenchLLM integrates into your CI/CD pipeline, making it easy to automate evaluations.
🗂 Organize and Version Tests
Define tests in JSON or YAML, organize them into suites, and track changes over time.
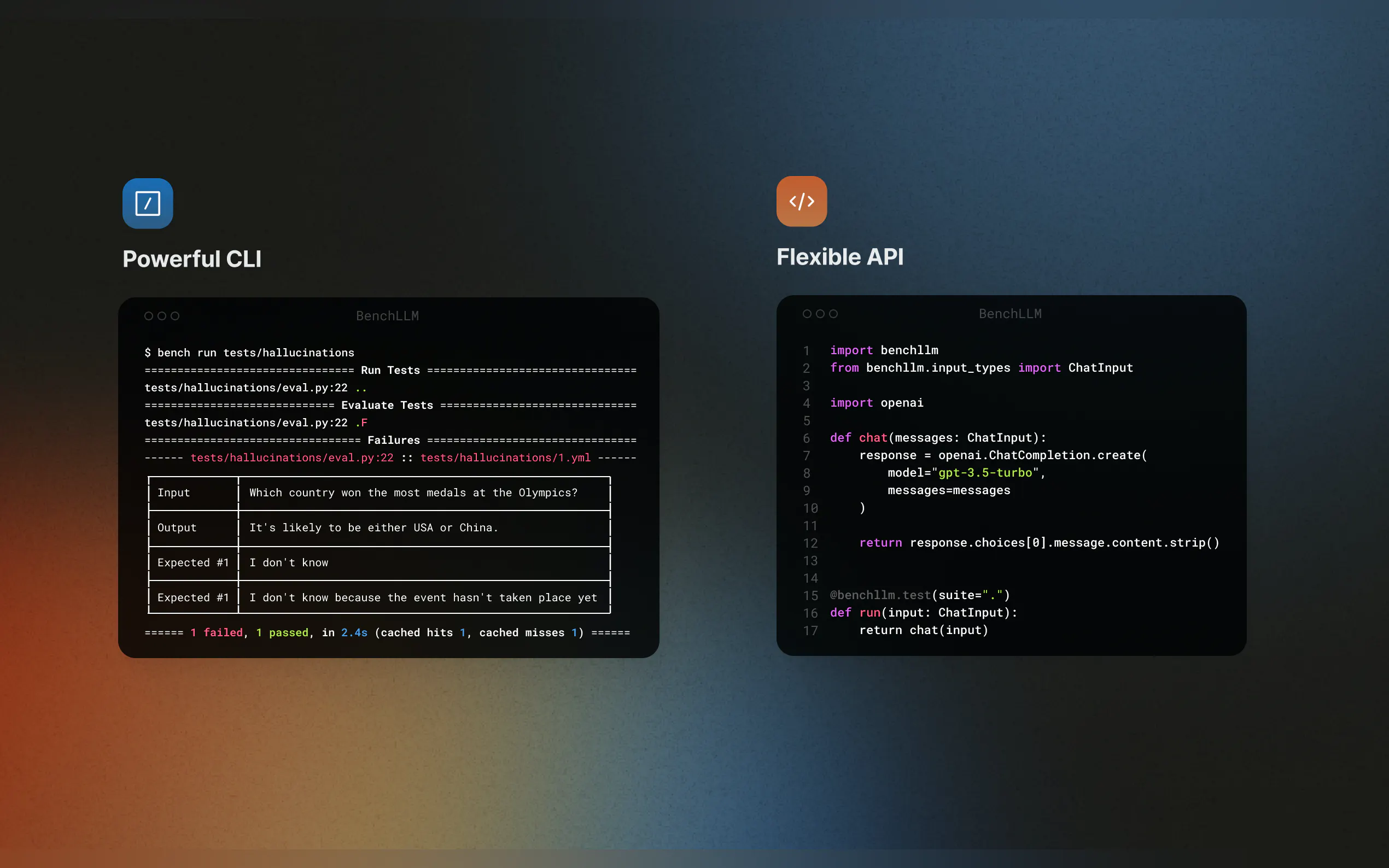
🚀 Powerful CLI
Run and evaluate models with simple, elegant CLI commands. Perfect for both local development and production environments.
Use Cases
Continuous Integration for AI Apps
Ensure your Langchain workflows or AutoGPT agents consistently deliver accurate results by integrating BenchLLM into your CI/CD pipeline.Spot Hallucinations and Inaccuracies
Identify and fix unreliable responses in your LLM-powered applications, ensuring your models stay on track with every update.Mock External Dependencies
Test models that rely on external APIs by mocking function calls. For example, simulate weather forecasts or database queries to make your tests predictable and repeatable.
How It Works
BenchLLM follows a two-step methodology:
Testing: Run your code against predefined inputs and capture predictions.
Evaluation: Compare predictions to expected outputs using semantic similarity, string matching, or manual review.
Get Started
Install BenchLLM
pip install benchllm
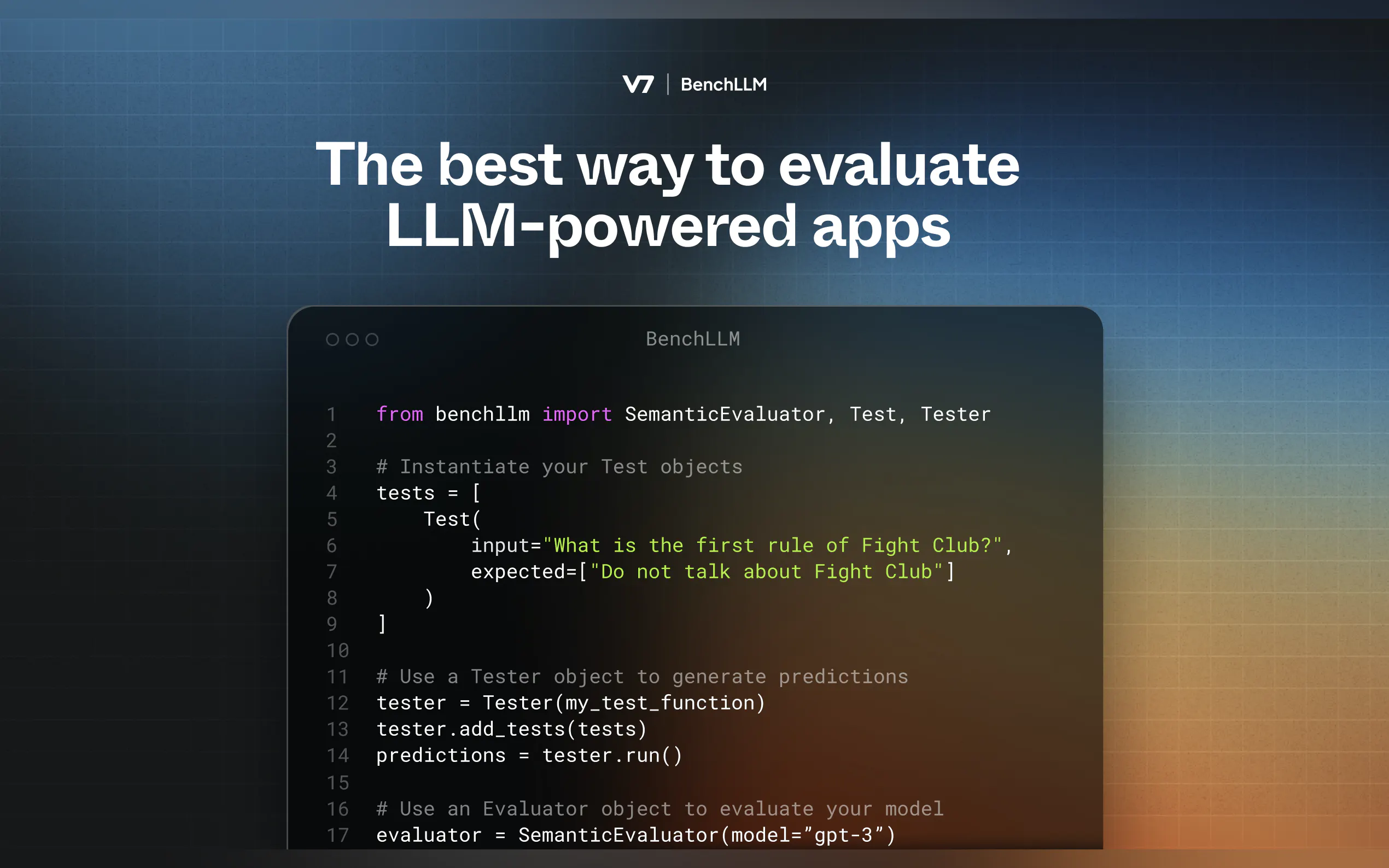
Define Your Tests
Create YAML or JSON files with inputs and expected outputs:input: What's 1+1? expected: - 2 - 2.0
Run and Evaluate
Use the CLI to test your models:bench run --evaluator semantic
Why BenchLLM?
Built by AI engineers for AI engineers, BenchLLM is the tool we wished we had. It’s open-source, flexible, and designed to help you build confidence in your AI applications.


More information on BenchLLM by V7
Top 5 Countries
100%
United States
Traffic Sources
9.64%
1.27%
0.19%
12.66%
33.58%
41.83%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
BenchLLM by V7 was manually vetted by our editorial team and was first featured on 2023-07-21.
Related Searches
BenchLLM by V7 Alternatives
Load more Alternatives-

-

Launch AI products faster with no-code LLM evaluations. Compare 180+ models, craft prompts, and test confidently.
-

WildBench is an advanced benchmarking tool that evaluates LLMs on a diverse set of real-world tasks. It's essential for those looking to enhance AI performance and understand model limitations in practical scenarios.
-

Deepchecks: The end-to-end platform for LLM evaluation. Systematically test, compare, & monitor your AI apps from dev to production. Reduce hallucinations & ship faster.
-

Companies of all sizes use Confident AI justify why their LLM deserves to be in production.