
What is BenchLLM by V7?
BenchLLM是一个基于Python的开源库,旨在帮助开发者评估大型语言模型(LLM)和AI应用的性能。无论您是构建代理、链式模型还是自定义模型,BenchLLM都能提供测试响应、消除不稳定输出并确保您的AI提供可靠结果的工具。
关键特性
✨ 灵活的测试策略
您可以选择自动化、交互式或自定义评估方法。无论您需要使用GPT模型进行语义相似性检查,还是简单的字符串匹配,BenchLLM都能适应您的需求。
? 生成高质量报告
获取详细的评估报告,以监控模型性能,检测回归并与您的团队共享见解。
? 无缝集成
支持OpenAI、Langchain和其他API,您可以随时测试您的代码。BenchLLM可以集成到您的CI/CD流水线中,从而轻松实现自动化评估。
? 组织和版本控制测试
您可以使用JSON或YAML定义测试,将其组织成套件,并跟踪随时间推移的变化。
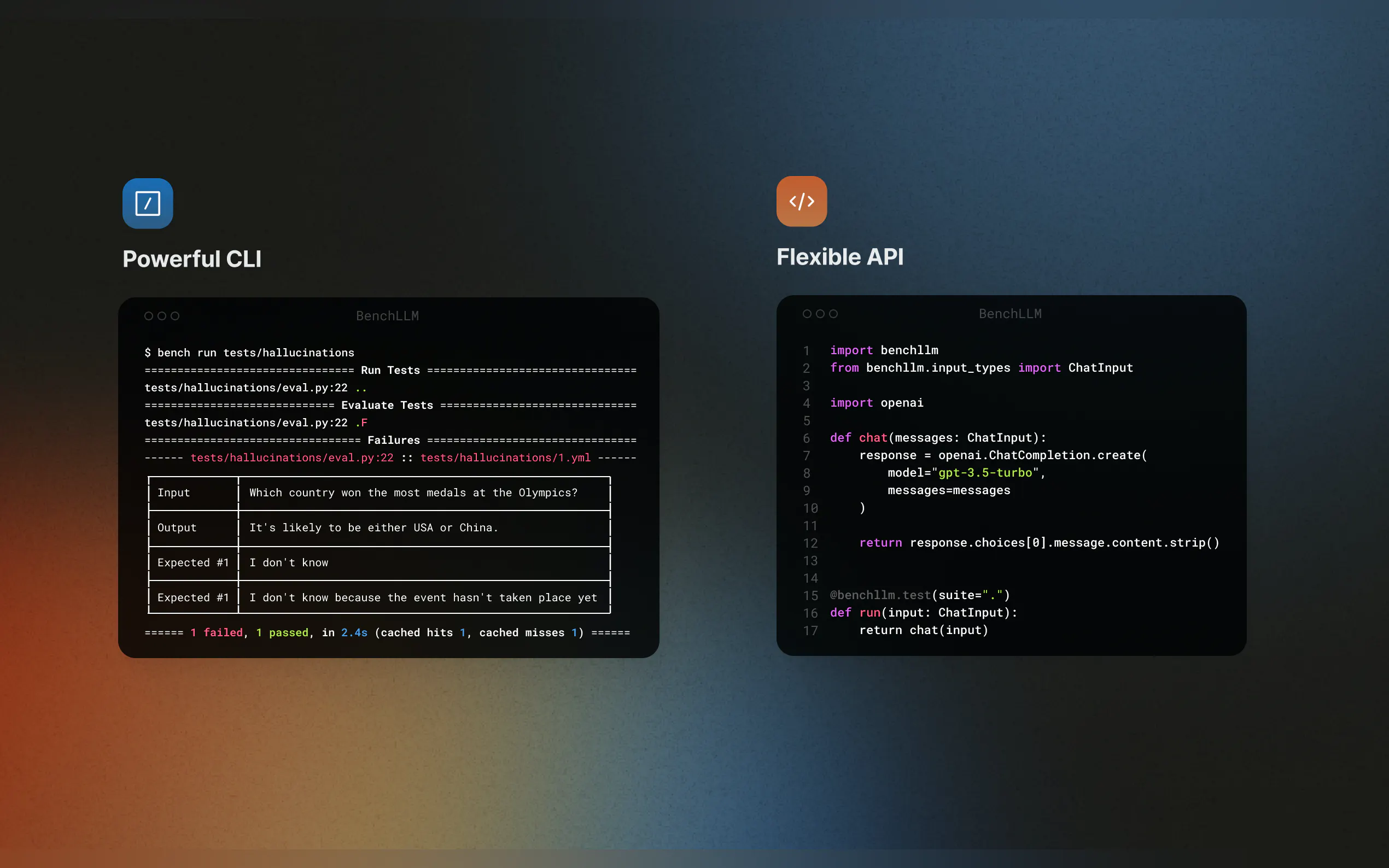
? 强大的CLI
使用简单优雅的CLI命令运行和评估模型。非常适合本地开发和生产环境。
使用案例
AI应用的持续集成
通过将BenchLLM集成到您的CI/CD流水线中,确保您的Langchain工作流程或AutoGPT代理始终提供准确的结果。发现幻觉和不准确之处
识别并修复LLM驱动应用程序中不可靠的响应,确保您的模型在每次更新中都能保持一致。模拟外部依赖项
通过模拟函数调用来测试依赖于外部API的模型。例如,模拟天气预报或数据库查询,使您的测试可预测且可重复。
工作原理
BenchLLM采用两步法:
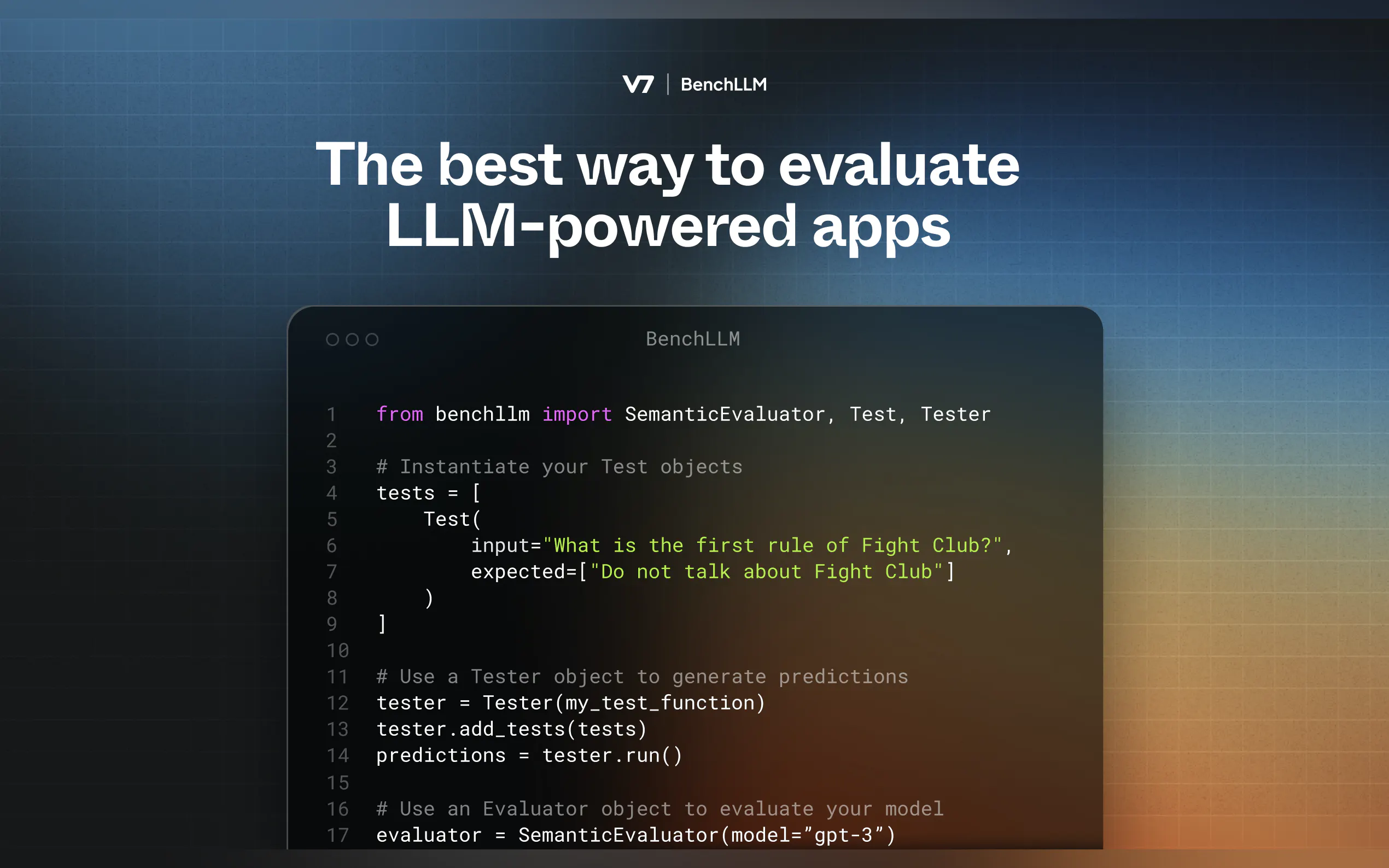
测试:针对预定义的输入运行您的代码并捕获预测结果。
评估:使用语义相似性、字符串匹配或人工审核将预测结果与预期输出进行比较。
快速上手
安装BenchLLM
pip install benchllm
定义您的测试
创建包含输入和预期输出的YAML或JSON文件:input: What's 1+1? expected: - 2 - 2.0
运行和评估
使用CLI测试您的模型:bench run --evaluator semantic
为什么选择BenchLLM?
BenchLLM由AI工程师为AI工程师打造,是我们一直希望拥有的工具。它是开源的、灵活的,旨在帮助您对AI应用充满信心。


More information on BenchLLM by V7
Top 5 Countries
100%
United States
Traffic Sources
9.64%
1.27%
0.19%
12.66%
33.58%
41.83%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
BenchLLM by V7 was manually vetted by our editorial team and was first featured on 2023-07-21.
Related Searches
BenchLLM by V7 替代方案
更多 替代方案-

-

-

WildBench 是一款先进的基准测试工具,用于评估大型语言模型 (LLM) 在各种现实世界任务中的表现。对于那些希望提高 AI 性能并了解模型在实际场景中的局限性的用户来说,它至关重要。
-

-
