
What is BenchLLM by V7?
BenchLLM 是一個基於 Python 的開源函式庫,旨在幫助開發者評估大型語言模型 (LLM) 和 AI 應用程式的效能。無論您是構建代理程式、鏈式模型還是自訂模型,BenchLLM 都能提供必要的工具來測試回應、消除不穩定輸出並確保您的 AI 提供可靠的結果。
主要功能
✨ 彈性測試策略
從自動化、互動式或自訂評估方法中選擇。無論您需要使用 GPT 模型進行語義相似性檢查,還是簡單的字串比對,BenchLLM 都能適應您的需求。
? 產生高品質報告
獲得詳細的評估報告,以監控模型效能、偵測迴歸並與您的團隊分享見解。
? 無縫整合
透過支援 OpenAI、Langchain 和其他 API,隨時測試您的程式碼。BenchLLM 整合到您的 CI/CD 管線中,讓自動化評估變得輕而易舉。
? 組織和版本控制測試
以 JSON 或 YAML 定義測試,將它們組織成套件,並追蹤時間推移的變化。
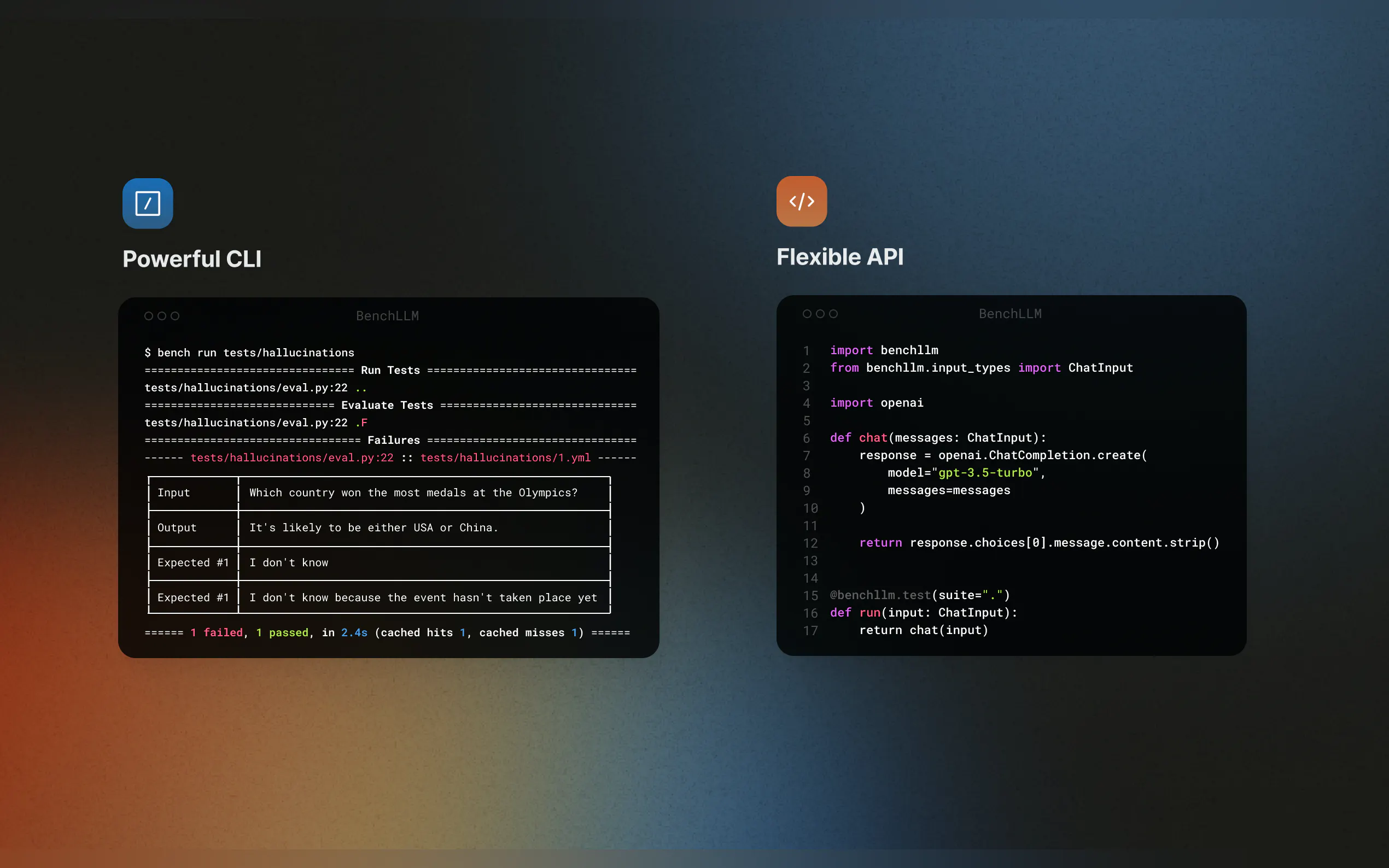
? 強大的 CLI
使用簡潔優雅的 CLI 命令運行和評估模型。非常適合本地開發和生產環境。
使用案例
AI 應用程式的持續整合
透過將 BenchLLM 整合到您的 CI/CD 管線中,確保您的 Langchain 工作流程或 AutoGPT 代理程式始終提供準確的結果。發現幻覺和不準確性
識別並修正您基於 LLM 的應用程式中不可靠的回應,確保您的模型在每次更新中都能保持一致。模擬外部相依性
透過模擬函式呼叫來測試依賴外部 API 的模型。例如,模擬天氣預報或資料庫查詢,使您的測試可預測且可重複。
工作原理
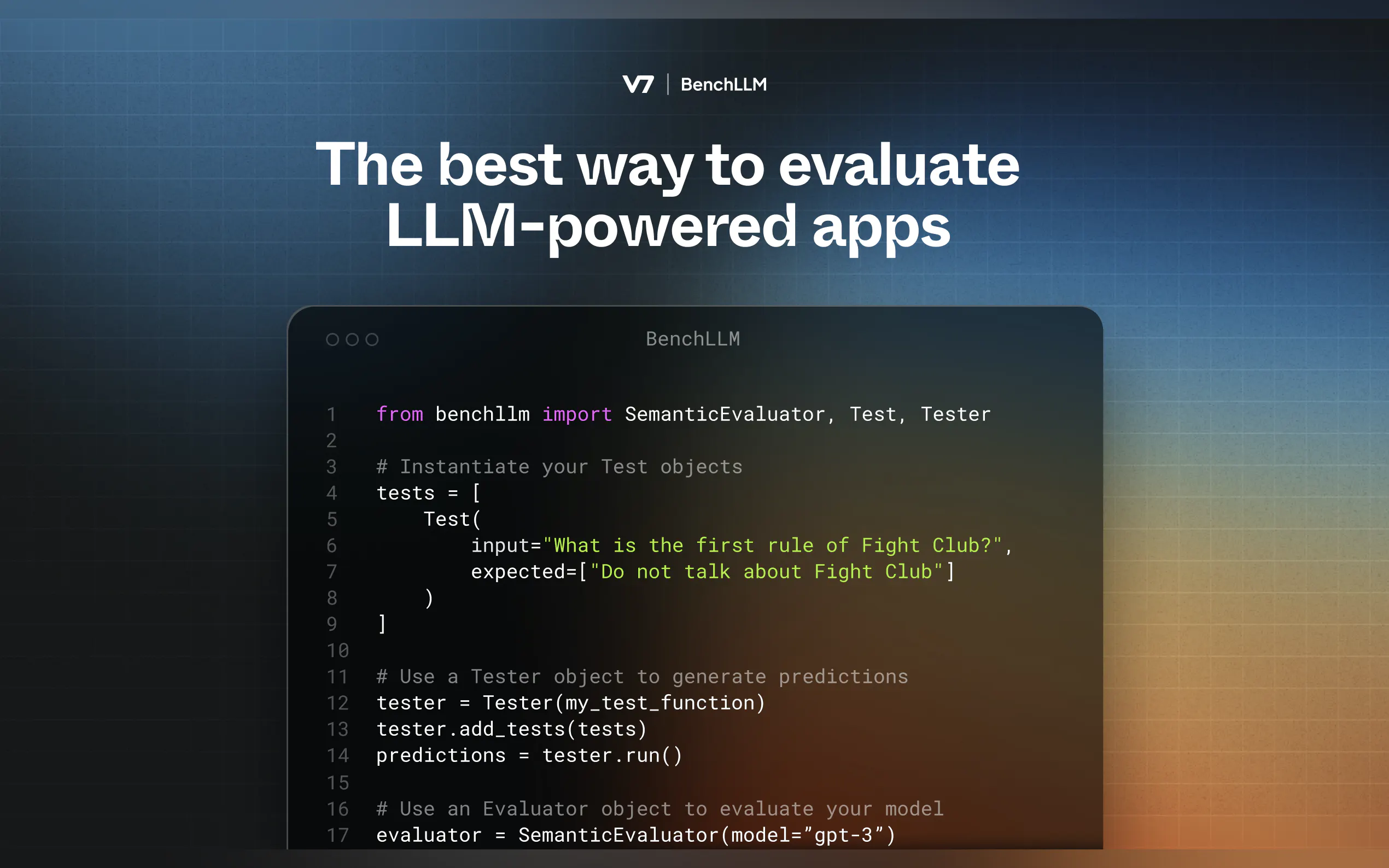
BenchLLM 遵循兩步驟方法:
測試:針對預定義輸入運行您的程式碼並擷取預測。
評估:使用語義相似性、字串比對或人工審查將預測與預期輸出進行比較。
開始使用
安裝 BenchLLM
pip install benchllm
定義您的測試
建立包含輸入和預期輸出的 YAML 或 JSON 檔案:input: What's 1+1? expected: - 2 - 2.0
運行和評估
使用 CLI 測試您的模型:bench run --evaluator semantic
為什麼選擇 BenchLLM?
BenchLLM 由 AI 工程師為 AI 工程師打造,它是我們一直以來都希望擁有的工具。它是開源的、彈性的,旨在幫助您對 AI 應用程式建立信心。


More information on BenchLLM by V7
Top 5 Countries
100%
United States
Traffic Sources
9.64%
1.27%
0.19%
12.66%
33.58%
41.83%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
BenchLLM by V7 was manually vetted by our editorial team and was first featured on 2023-07-21.
Related Searches
BenchLLM by V7 替代方案
更多 替代方案-

-

-

WildBench 是一個先進的基準測試工具,用於評估 LLM 在各種真實世界任務中的表現。對於那些希望提升 AI 效能並了解模型在實際情境中的局限性的人來說,它是必不可少的工具。
-

Deepchecks:大型語言模型(LLM)的端對端評估平台。 從開發到上線,有系統地測試、比較並監控您的AI應用程式。 有效降低幻覺,並加速產品上市。
-
