
What is BenchLLM by V7?
BenchLLM es una biblioteca de código abierto basada en Python diseñada para ayudar a los desarrolladores a evaluar el rendimiento de los Modelos de Lenguaje Extensos (LLM) y las aplicaciones impulsadas por IA. Tanto si está creando agentes, cadenas o modelos personalizados, BenchLLM proporciona las herramientas para probar las respuestas, eliminar las salidas erráticas y garantizar que su IA ofrezca resultados fiables.
Características Clave
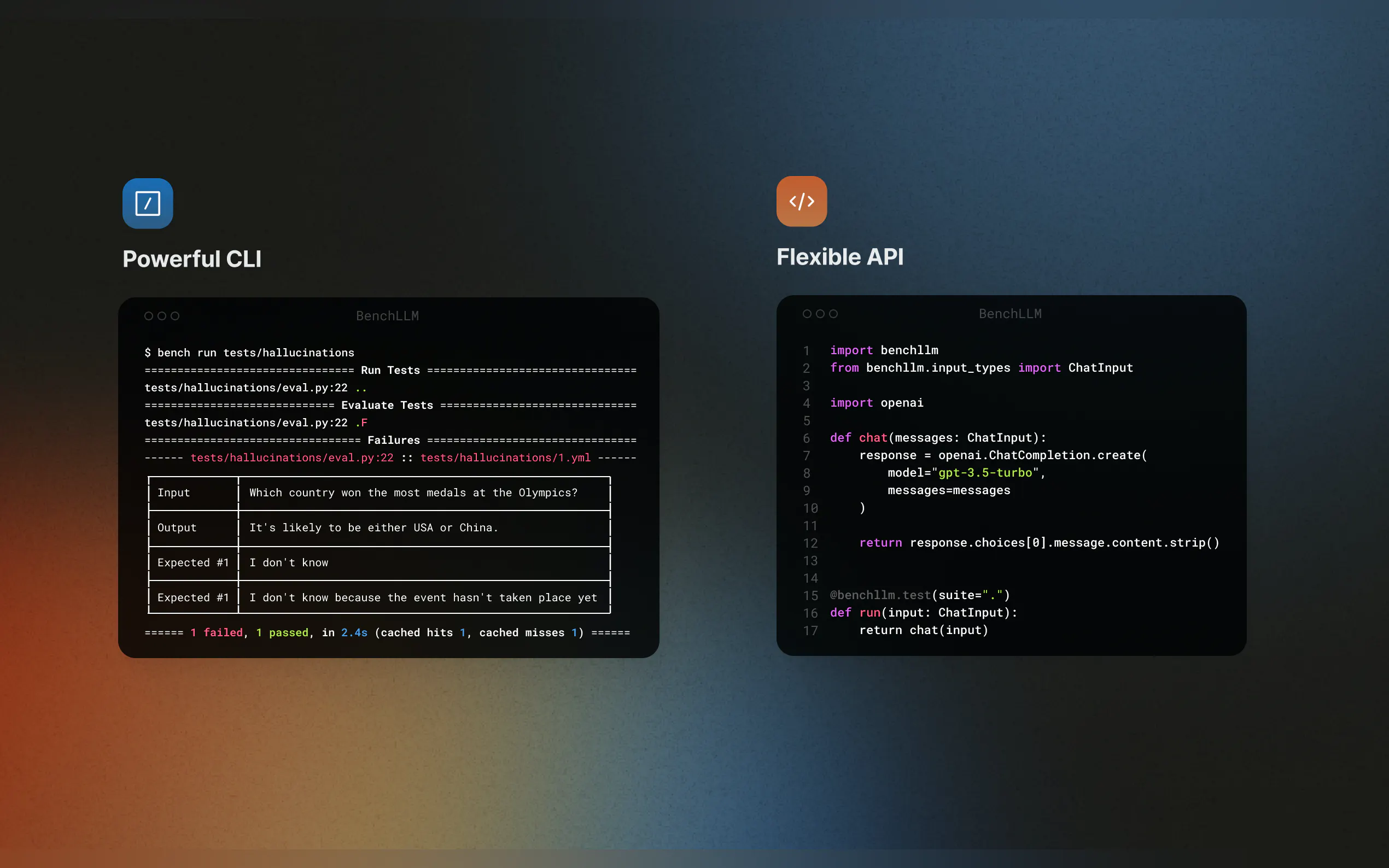
✨ Estrategias de Prueba Flexibles
Elija entre métodos de evaluación automatizados, interactivos o personalizados. Tanto si necesita comprobaciones de similitud semántica con modelos GPT como una simple comparación de cadenas, BenchLLM se adapta a sus necesidades.
? Genere Informes de Calidad
Obtenga informes de evaluación detallados para controlar el rendimiento del modelo, detectar regresiones y compartir información con su equipo.
? Integración Fluida
Pruebe su código sobre la marcha con soporte para OpenAI, Langchain y otras APIs. BenchLLM se integra en su pipeline CI/CD, facilitando la automatización de las evaluaciones.
? Organice y Versiones las Pruebas
Defina las pruebas en JSON o YAML, organícelas en conjuntos y realice un seguimiento de los cambios a lo largo del tiempo.
? Potente CLI
Ejecute y evalúe modelos con comandos CLI sencillos y elegantes. Perfecto tanto para entornos de desarrollo local como de producción.
Casos de Uso
Integración Continua para Aplicaciones de IA
Asegure que sus flujos de trabajo de Langchain o agentes AutoGPT proporcionen resultados precisos de forma consistente integrando BenchLLM en su pipeline CI/CD.Detectar Alucinaciones e Imprecisiones
Identifique y corrija las respuestas poco fiables en sus aplicaciones impulsadas por LLM, asegurando que sus modelos se mantengan en el buen camino con cada actualización.Simular Dependencias Externas
Pruebe modelos que dependen de APIs externas simulando llamadas a funciones. Por ejemplo, simule previsiones meteorológicas o consultas a bases de datos para hacer sus pruebas predecibles y repetibles.
Cómo Funciona
BenchLLM sigue una metodología de dos pasos:
Prueba: Ejecute su código con entradas predefinidas y capture las predicciones.
Evaluación: Compare las predicciones con las salidas esperadas utilizando similitud semántica, comparación de cadenas o revisión manual.
Comience
Instale BenchLLM
pip install benchllm
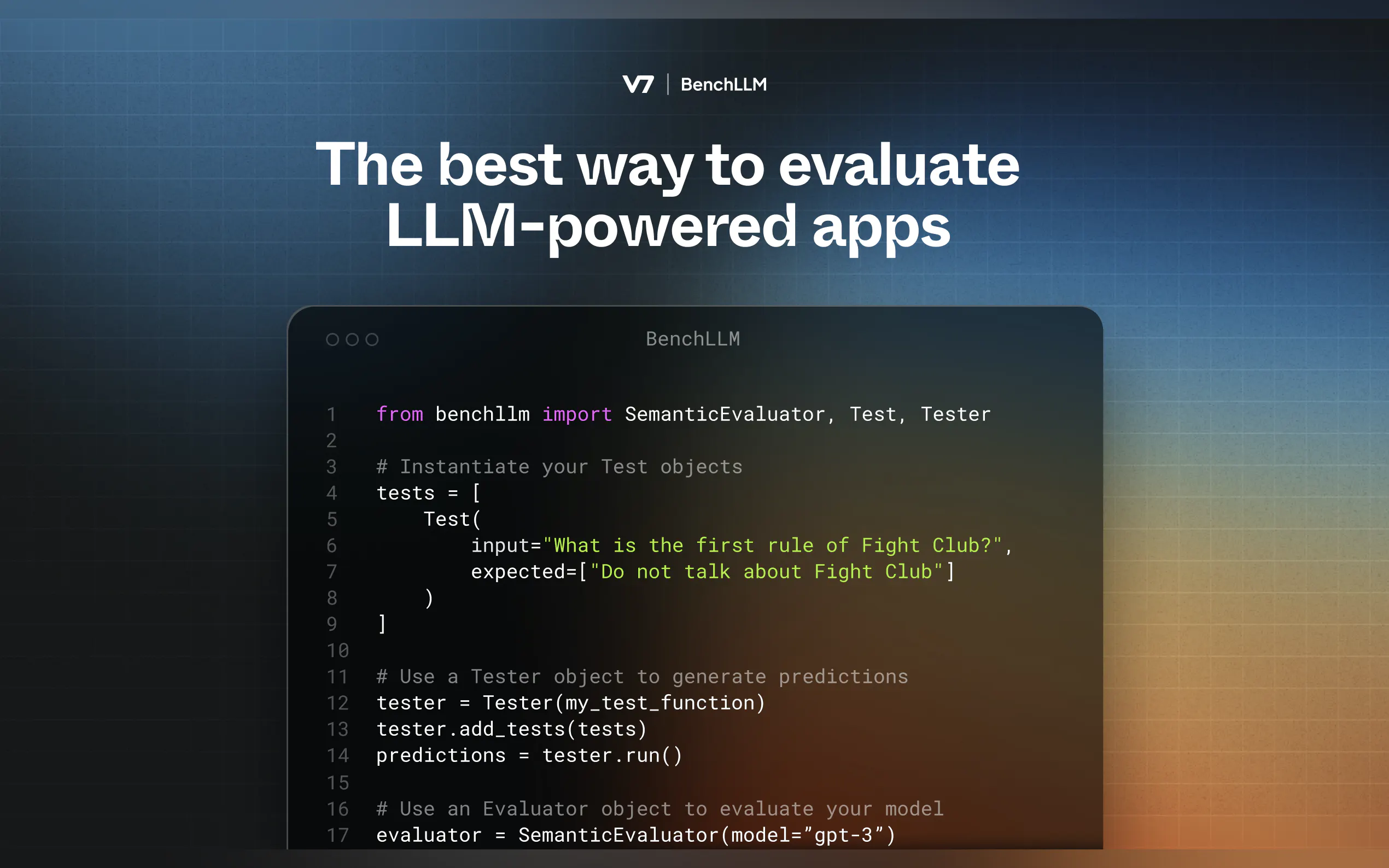
Defina Sus Pruebas
Cree archivos YAML o JSON con entradas y salidas esperadas:input: ¿Qué es 1+1? expected: - 2 - 2.0
Ejecute y Evalúe
Utilice la CLI para probar sus modelos:bench run --evaluator semantic
¿Por qué BenchLLM?
Creada por ingenieros de IA para ingenieros de IA, BenchLLM es la herramienta que deseábamos tener. Es de código abierto, flexible y está diseñada para ayudarle a generar confianza en sus aplicaciones de IA.


More information on BenchLLM by V7
Top 5 Countries
100%
United States
Traffic Sources
9.64%
1.27%
0.19%
12.66%
33.58%
41.83%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
BenchLLM by V7 was manually vetted by our editorial team and was first featured on 2023-07-21.
Related Searches
BenchLLM by V7 Alternativas
Más Alternativas-

-

Lanza productos de IA más rápido con evaluaciones LLM sin código. Compara más de 180 modelos, crea prompts y prueba con confianza.
-

WildBench es una herramienta de evaluación avanzada que evalúa los LLM en un conjunto diverso de tareas del mundo real. Es esencial para aquellos que buscan mejorar el rendimiento de la IA y comprender las limitaciones del modelo en escenarios prácticos.
-

Deepchecks: La plataforma integral para la evaluación de LLM. Ponga a prueba, compare y monitorice sistemáticamente sus aplicaciones de IA del desarrollo a la producción. Reduzca las alucinaciones y despliegue más rápido.
-

Las empresas de todos los tamaños utilizan Confident AI para justificar por qué su LLM merece estar en producción.