
What is BenchLLM by V7?
BenchLLM est une bibliothèque open-source basée sur Python, conçue pour aider les développeurs à évaluer les performances des grands modèles de langage (LLM) et des applications d'IA. Que vous construisiez des agents, des chaînes ou des modèles personnalisés, BenchLLM fournit les outils nécessaires pour tester les réponses, éliminer les sorties imprévisibles et garantir que votre IA fournit des résultats fiables.
Fonctionnalités clés
✨ Stratégies de test flexibles
Choisissez parmi des méthodes d'évaluation automatisées, interactives ou personnalisées. Que vous ayez besoin de vérifications de similarité sémantique avec les modèles GPT ou d'une simple comparaison de chaînes de caractères, BenchLLM s'adapte à vos besoins.
? Génération de rapports de qualité
Obtenez des rapports d'évaluation détaillés pour suivre les performances du modèle, détecter les régressions et partager les informations avec votre équipe.
? Intégration transparente
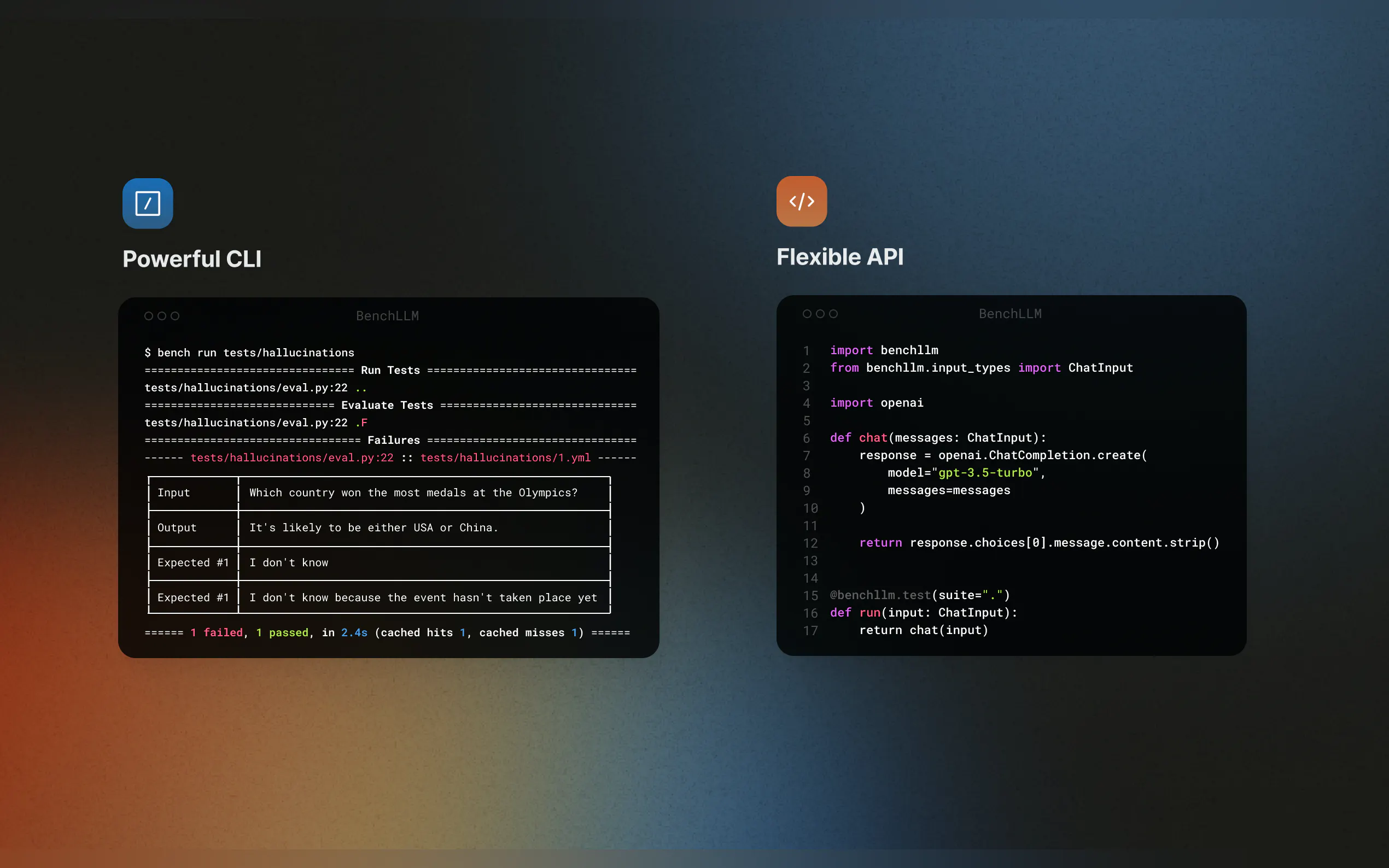
Testez votre code à la volée grâce à la prise en charge d'OpenAI, Langchain et d'autres API. BenchLLM s'intègre à votre pipeline CI/CD, ce qui facilite l'automatisation des évaluations.
? Organisation et gestion de versions des tests
Définissez les tests en JSON ou YAML, organisez-les en suites et suivez les modifications au fil du temps.
? Interface en ligne de commande puissante
Exécutez et évaluez les modèles avec des commandes CLI simples et élégantes. Parfait pour le développement local et les environnements de production.
Cas d'utilisation
Intégration continue pour les applications IA
Assurez-vous que vos workflows Langchain ou vos agents AutoGPT fournissent des résultats précis de manière cohérente en intégrant BenchLLM à votre pipeline CI/CD.Détection des hallucinations et des inexactitudes
Identifiez et corrigez les réponses non fiables dans vos applications basées sur les LLM, en garantissant que vos modèles restent sur la bonne voie à chaque mise à jour.Simulation des dépendances externes
Testez les modèles qui s'appuient sur des API externes en simulant les appels de fonctions. Par exemple, simulez les prévisions météorologiques ou les requêtes de base de données pour rendre vos tests prévisibles et reproductibles.
Fonctionnement
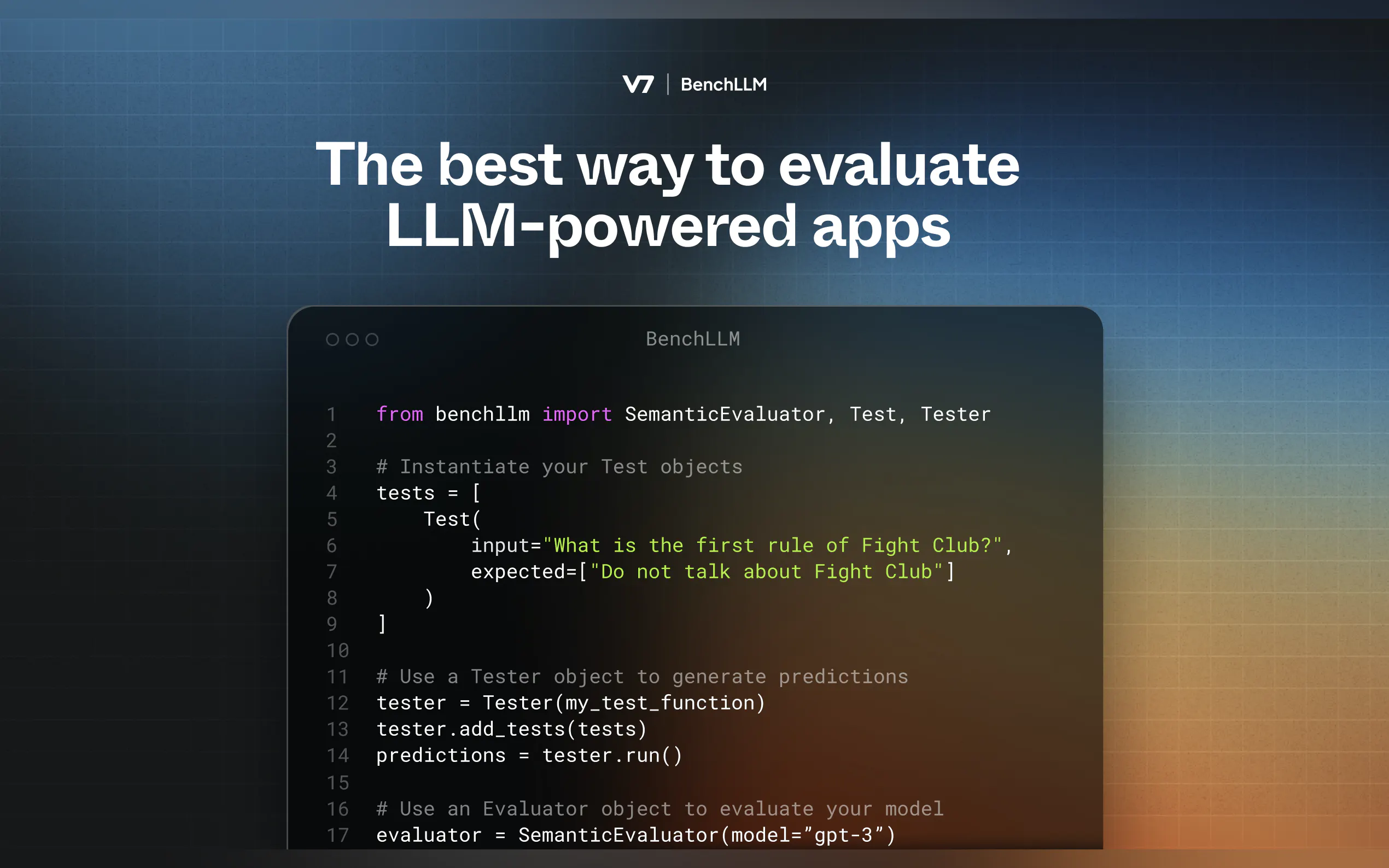
BenchLLM suit une méthodologie en deux étapes :
Test : Exécutez votre code avec des entrées prédéfinies et capturez les prédictions.
Évaluation : Comparez les prédictions aux sorties attendues en utilisant la similarité sémantique, la comparaison de chaînes de caractères ou une revue manuelle.
Pour commencer
Installation de BenchLLM
pip install benchllm
Définition de vos tests
Créez des fichiers YAML ou JSON avec les entrées et les sorties attendues :input: What's 1+1? expected: - 2 - 2.0
Exécution et évaluation
Utilisez l'interface en ligne de commande pour tester vos modèles :bench run --evaluator semantic
Pourquoi BenchLLM ?
Conçu par des ingénieurs IA pour les ingénieurs IA, BenchLLM est l'outil dont nous rêvions. Il est open-source, flexible et conçu pour vous aider à avoir confiance dans vos applications IA.


More information on BenchLLM by V7
Top 5 Countries
100%
United States
Traffic Sources
9.64%
1.27%
0.19%
12.66%
33.58%
41.83%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
BenchLLM by V7 was manually vetted by our editorial team and was first featured on 2023-07-21.
Related Searches
BenchLLM by V7 Alternatives
Plus Alternatives-

-

Lancez plus rapidement vos produits d'IA grâce aux évaluations LLM sans code. Comparez plus de 180 modèles, concevez des invites et testez en toute confiance.
-

WildBench est un outil de benchmark avancé qui évalue les LLM sur un ensemble diversifié de tâches du monde réel. Il est essentiel pour ceux qui cherchent à améliorer les performances de l'IA et à comprendre les limites des modèles dans des scénarios pratiques.
-

Deepchecks : La plateforme de bout en bout pour l'évaluation des LLM. Testez, comparez et supervisez systématiquement vos applications IA, du développement à la production. Réduisez les hallucinations et accélérez vos déploiements.
-

Les entreprises de toutes tailles utilisent Confident AI pour justifier la mise en production de leur LLM.