
What is BenchLLM by V7?
BenchLLMは、Pythonベースのオープンソースライブラリであり、開発者が大規模言語モデル(LLM)やAI搭載アプリケーションのパフォーマンスを評価するのに役立つように設計されています。エージェント、チェーン、カスタムモデルのいずれを構築する場合でも、BenchLLMはレスポンスのテスト、不安定な出力の排除、AIによる信頼性の高い結果の提供を保証するためのツールを提供します。
主な機能
✨ 柔軟なテスト戦略
自動化されたテスト、インタラクティブなテスト、カスタム評価方法から選択できます。GPTモデルを使用した意味的類似性のチェックが必要な場合でも、単純な文字列マッチングが必要な場合でも、BenchLLMはニーズに合わせて適応します。
? 高品質なレポートの生成
モデルのパフォーマンスを監視し、回帰を検出し、チームとインサイトを共有するための詳細な評価レポートを取得します。
? シームレスな統合
OpenAI、Langchain、その他のAPIをサポートすることで、コードをすぐにテストできます。BenchLLMはCI/CDパイプラインに統合され、評価の自動化を容易にします。
? テストの整理とバージョン管理
JSONまたはYAMLでテストを定義し、スイートに整理し、時間の経過に伴う変更を追跡します。
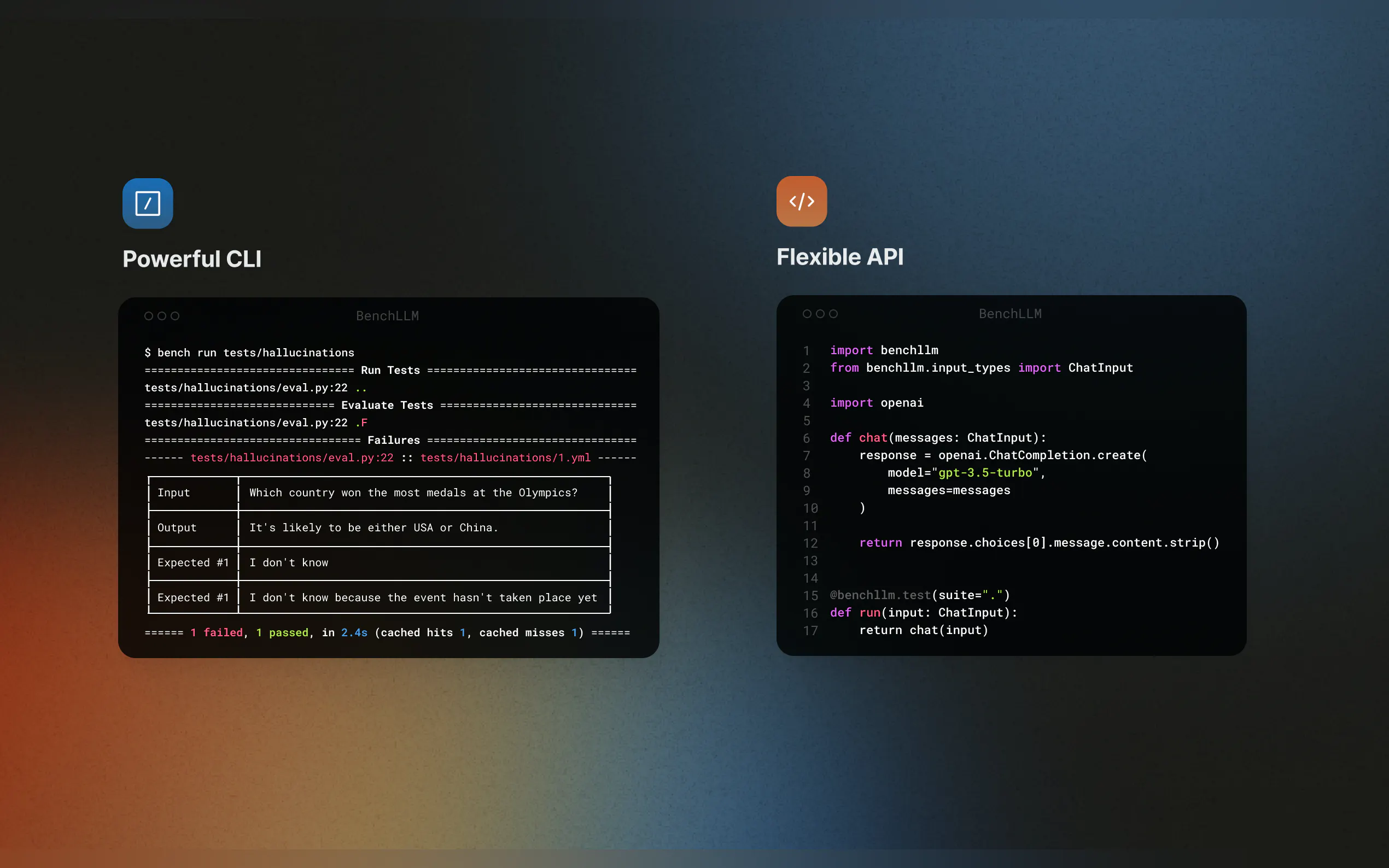
? 強力なCLI
シンプルで洗練されたCLIコマンドを使用して、モデルを実行および評価します。ローカル開発環境と本番環境の両方で最適です。
ユースケース
AIアプリケーションの継続的インテグレーション
CI/CDパイプラインにBenchLLMを統合することで、LangchainワークフローやAutoGPTエージェントが常に正確な結果を提供することを保証します。幻覚と不正確さの特定
LLM搭載アプリケーションにおける信頼性の低い応答を特定し修正することで、モデルがすべてのアップデートで適切に機能することを保証します。外部依存関係のモック
関数呼び出しをモックすることで、外部APIに依存するモデルをテストします。たとえば、天気予報やデータベースクエリをシミュレートして、テストを予測可能かつ繰り返し実行できるようにします。
動作方法
BenchLLMは2段階の手法に従います。
テスト:事前に定義された入力に対してコードを実行し、予測をキャプチャします。
評価:意味的類似性、文字列マッチング、または手動レビューを使用して、予測を期待される出力と比較します。
開始方法
BenchLLMのインストール
pip install benchllm
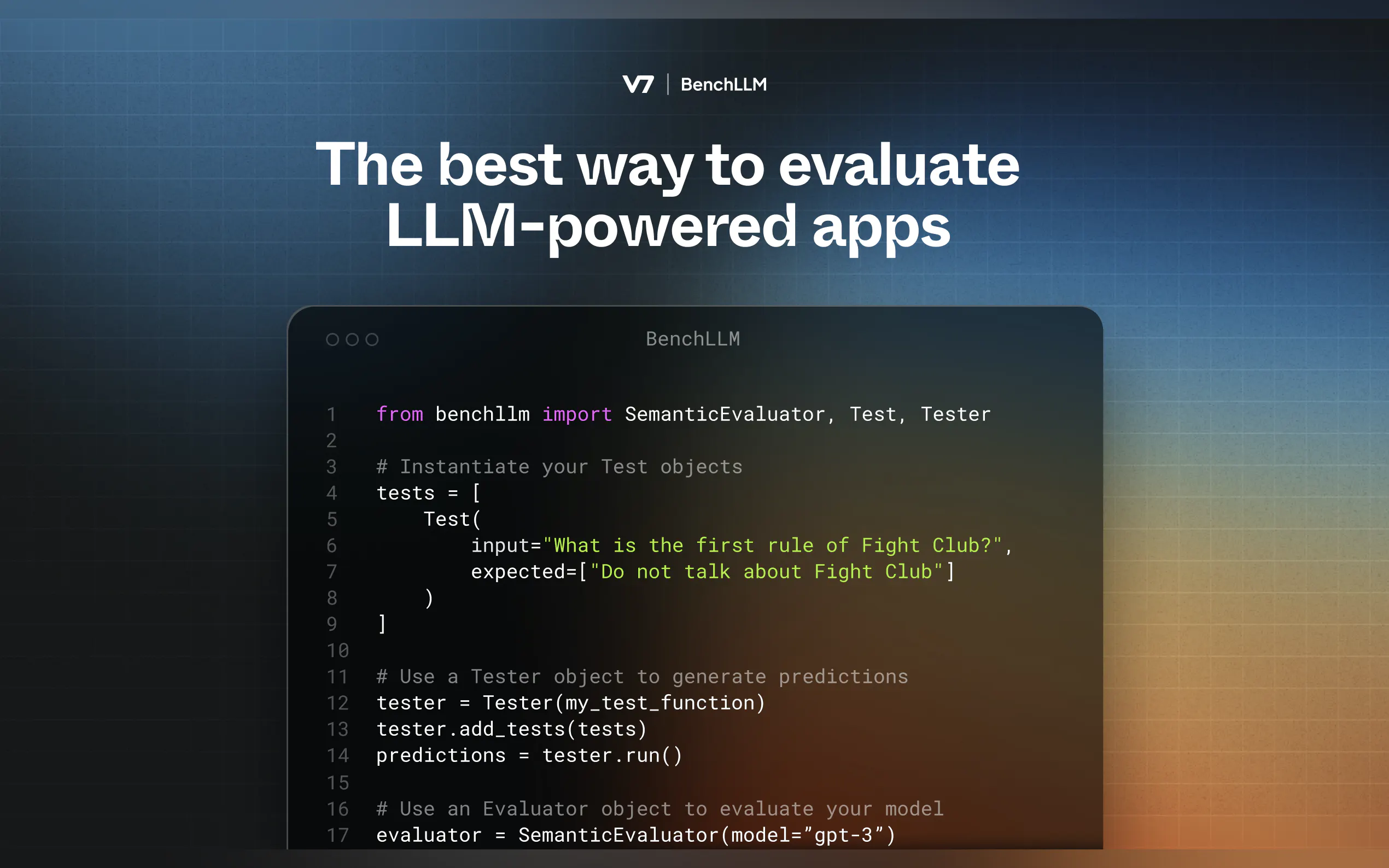
テストの定義
入力と期待される出力を含むYAMLまたはJSONファイルを作成します。input: What's 1+1? expected: - 2 - 2.0
実行と評価
CLIを使用してモデルをテストします。bench run --evaluator semantic
なぜBenchLLMなのか?
AIエンジニアによってAIエンジニアのために構築されたBenchLLMは、私たちが欲しかったツールです。オープンソースで柔軟性があり、AIアプリケーションへの信頼構築に役立つように設計されています。


More information on BenchLLM by V7
Top 5 Countries
100%
United States
Traffic Sources
9.64%
1.27%
0.19%
12.66%
33.58%
41.83%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
BenchLLM by V7 was manually vetted by our editorial team and was first featured on 2023-07-21.
Related Searches
BenchLLM by V7 代替ソフト
もっと見る 代替ソフト-

-

ノーコードのLLM評価で、AI製品をより迅速にローンチしましょう。180種類以上のモデルを比較し、プロンプトを作成し、自信を持ってテストできます。
-

WildBenchは、現実世界のさまざまなタスクでLLMを評価する、高度なベンチマークツールです。AIのパフォーマンスを向上させ、実際のシナリオにおけるモデルの限界を理解したいと考えている人にとって不可欠です。
-

Deepchecks: LLM評価を網羅するプラットフォーム。 AIアプリを開発から本番まで、体系的にテスト、比較、監視します。ハルシネーションを抑制し、迅速な提供を実現。
-
