
What is BenchLLM by V7?
BenchLLM — это библиотека с открытым исходным кодом на Python, предназначенная для помощи разработчикам в оценке производительности больших языковых моделей (LLM) и приложений на основе ИИ. Независимо от того, создаёте ли вы агентов, цепочки или собственные модели, BenchLLM предоставляет инструменты для проверки ответов, устранения нестабильных результатов и обеспечения надёжности вашего ИИ.
Ключевые возможности
✨ Гибкие стратегии тестирования
Выбирайте между автоматизированными, интерактивными или пользовательскими методами оценки. Независимо от того, нужны ли вам проверки семантического сходства с моделями GPT или простое сопоставление строк, BenchLLM адаптируется к вашим потребностям.
? Генерация отчётов о качестве
Получайте подробные отчёты об оценке для мониторинга производительности модели, обнаружения регрессий и обмена информацией с вашей командой.
? Бесшовная интеграция
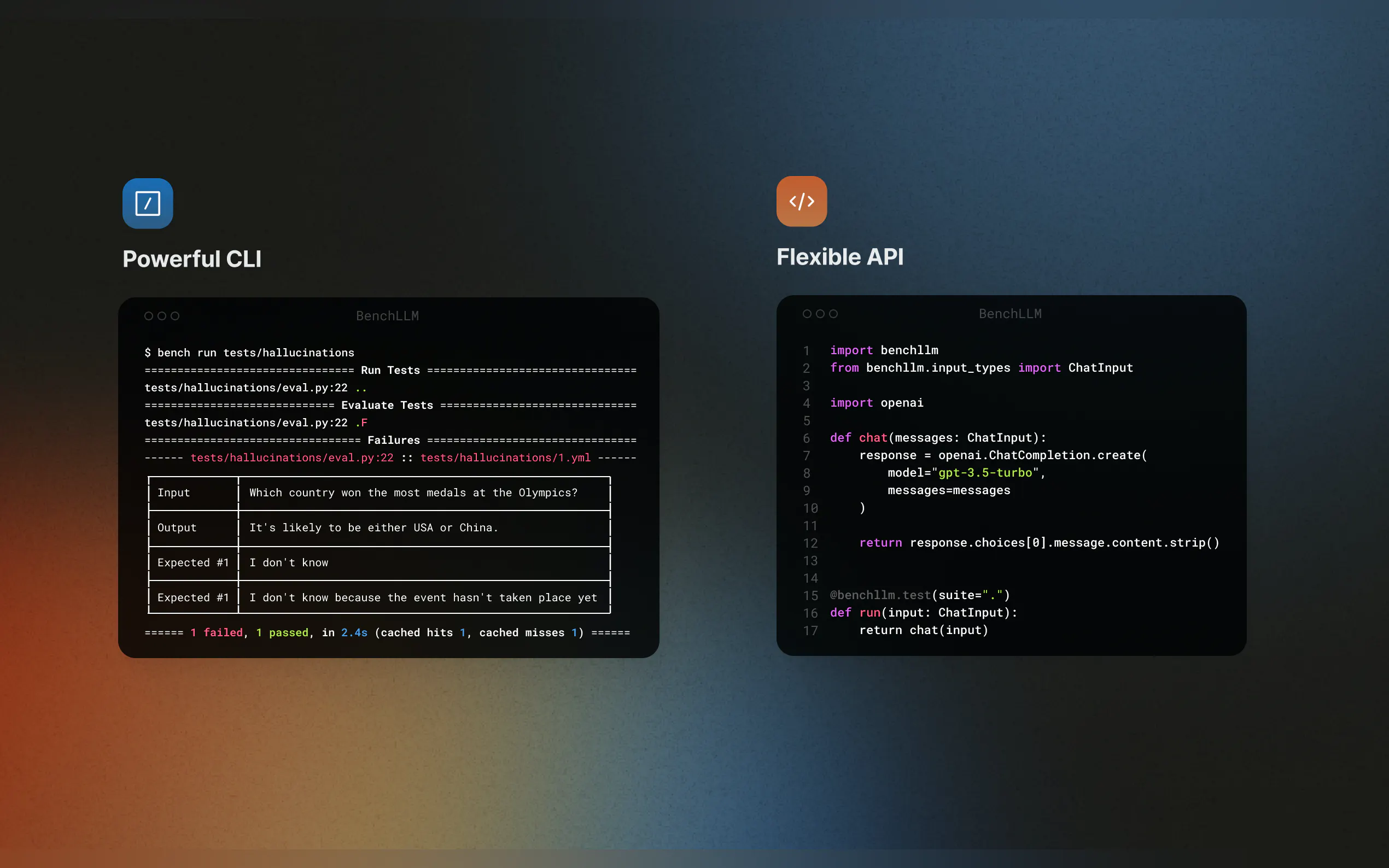
Тестируйте свой код на лету с поддержкой OpenAI, Langchain и других API. BenchLLM интегрируется в ваш конвейер CI/CD, что упрощает автоматизацию оценок.
? Организация и управление версиями тестов
Определяйте тесты в JSON или YAML, организуйте их в наборы и отслеживайте изменения с течением времени.
? Мощный интерфейс командной строки (CLI)
Запускайте и оценивайте модели с помощью простых и элегантных команд CLI. Идеально подходит как для локальной разработки, так и для production-окружений.
Варианты использования
Непрерывная интеграция для приложений ИИ
Обеспечьте стабильно точные результаты ваших рабочих процессов Langchain или агентов AutoGPT, интегрировав BenchLLM в ваш конвейер CI/CD.Обнаружение галлюцинаций и неточностей
Выявляйте и исправляйте ненадёжные ответы в ваших приложениях на основе LLM, гарантируя, что ваши модели остаются на верном пути при каждом обновлении.Имитация внешних зависимостей
Тестируйте модели, которые зависят от внешних API, имитируя вызовы функций. Например, моделируйте прогнозы погоды или запросы к базе данных, чтобы сделать ваши тесты предсказуемыми и воспроизводимыми.
Принцип работы
BenchLLM использует двухэтапную методологию:
Тестирование: Запуск вашего кода с предопределёнными входными данными и сбор прогнозов.
Оценка: Сравнение прогнозов с ожидаемыми результатами с использованием семантического сходства, сопоставления строк или ручного анализа.
Начало работы
Установка BenchLLM
pip install benchllm
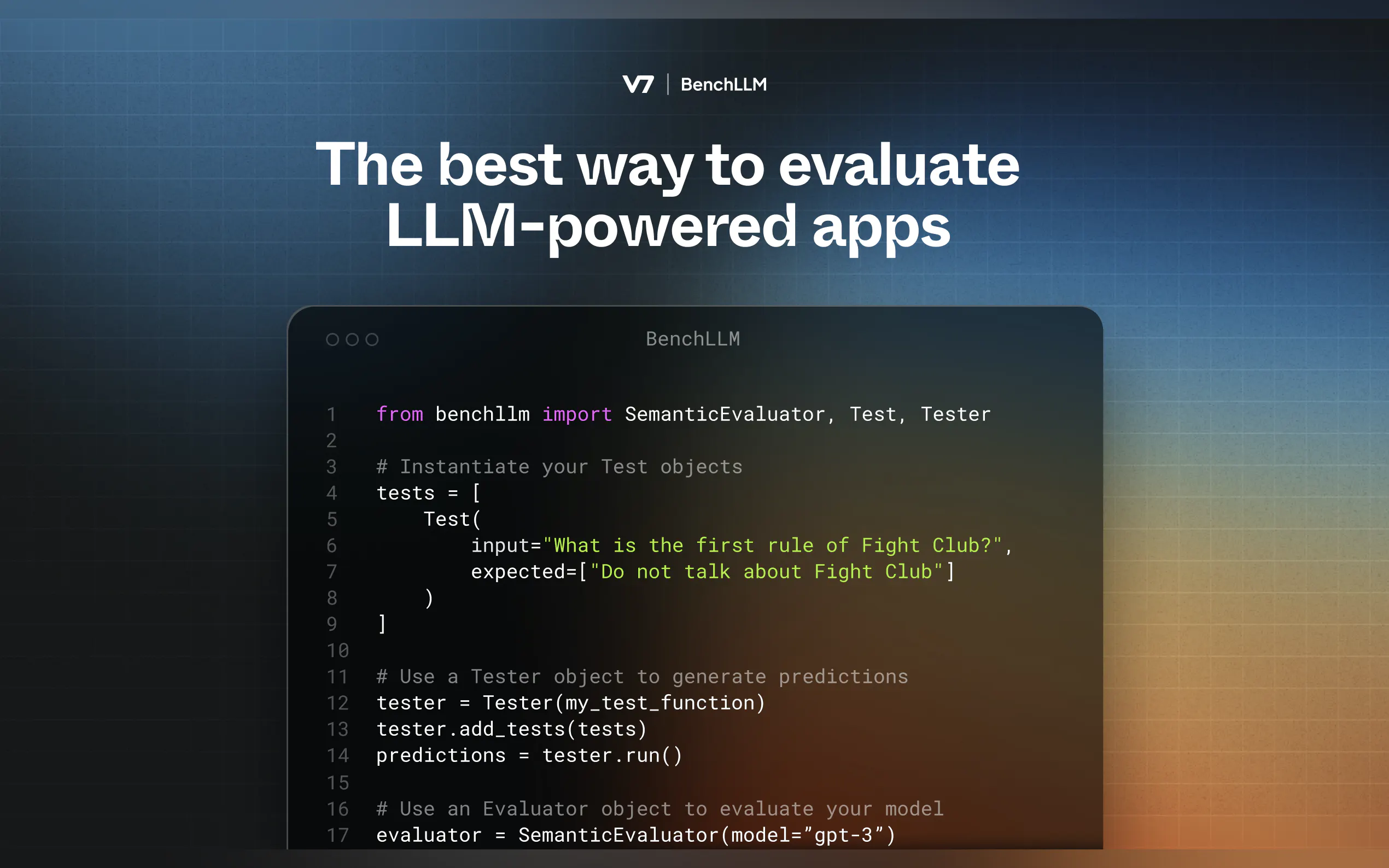
Определение ваших тестов
Создайте файлы YAML или JSON с входными данными и ожидаемыми результатами:input: What's 1+1? expected: - 2 - 2.0
Запуск и оценка
Используйте CLI для тестирования ваших моделей:bench run --evaluator semantic
Почему BenchLLM?
Созданный инженерами ИИ для инженеров ИИ, BenchLLM — это инструмент, который мы хотели бы иметь. Он с открытым исходным кодом, гибкий и разработан для того, чтобы помочь вам укрепить уверенность в ваших приложениях ИИ.


More information on BenchLLM by V7
Top 5 Countries
100%
United States
Traffic Sources
9.64%
1.27%
0.19%
12.66%
33.58%
41.83%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
BenchLLM by V7 was manually vetted by our editorial team and was first featured on 2023-07-21.
Related Searches
BenchLLM by V7 Альтернативи
Больше Альтернативи-

-

Запускайте продукты на основе ИИ быстрее с помощью бескликовой оценки больших языковых моделей. Сравнивайте более 180 моделей, создавайте запросы и тестируйте с уверенностью.
-

WildBench - это передовой инструмент для бенчмаркинга, который оценивает большие языковые модели (LLM) на разнообразном наборе реальных задач. Он незаменим для тех, кто стремится повысить производительность ИИ и понять ограничения модели в практических сценариях.
-

Deepchecks: Комплексная платформа для оценки LLM. Систематически тестируйте, сравнивайте и отслеживайте ваши ИИ-приложения от разработки до продакшена. Минимизируйте галлюцинации и ускорьте внедрение.
-

Компании всех размеров используют Confident AI, чтобы обосновать, почему их LLM заслуживают места в процессе производства.