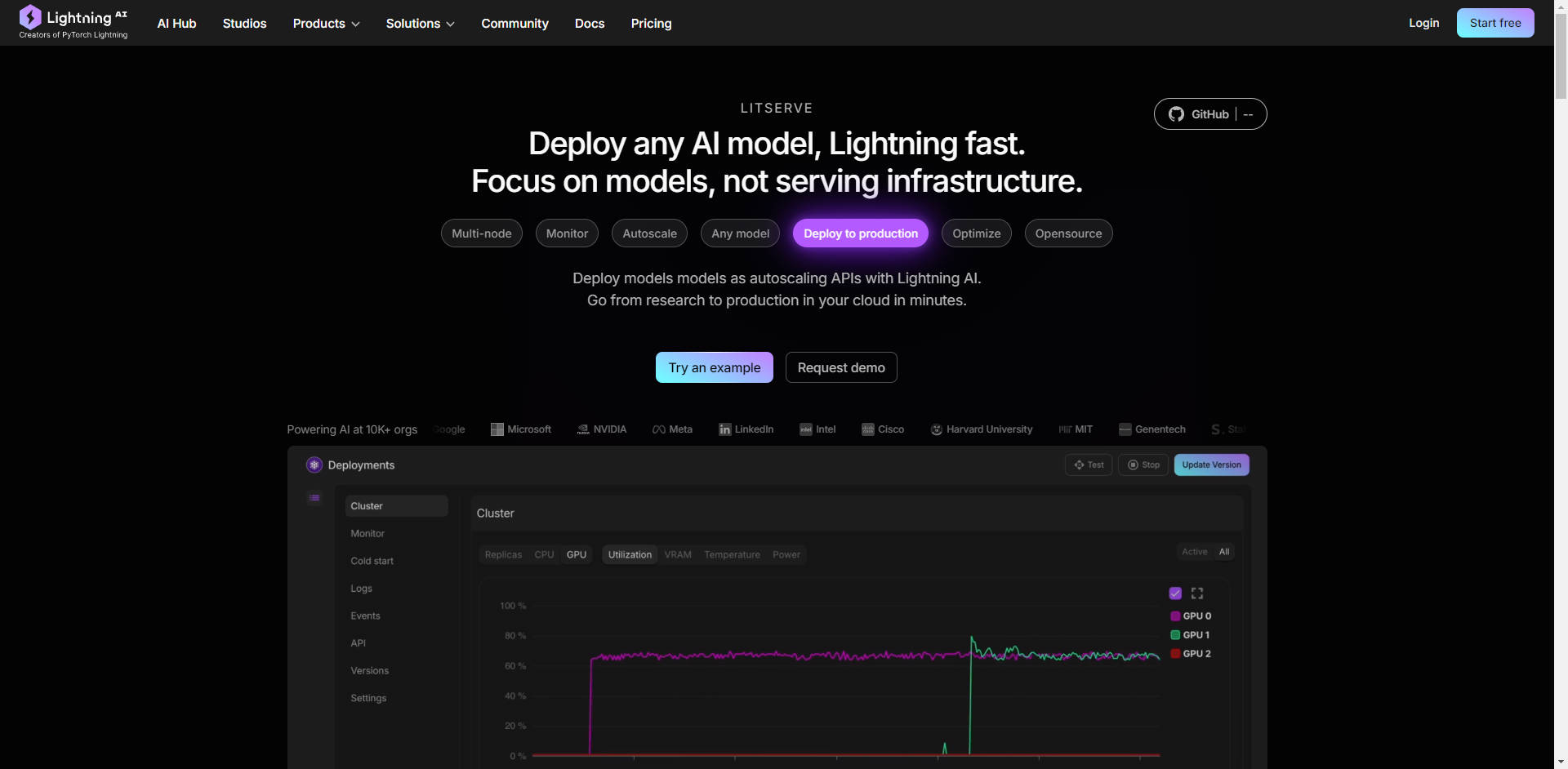
What is LitServe?
Êtes-vous un développeur ou un ingénieur en IA qui passe plus de temps à se battre avec l'infrastructure qu'à innover avec vos modèles ? LitServe est un moteur de service flexible et facile à utiliser, conçu pour simplifier le déploiement de tout modèle d'IA, quelle que soit sa taille ou son framework. Construit sur le framework populaire FastAPI, LitServe élimine les complexités de la mise à l'échelle, du traitement par lots et de la gestion des GPU, vous permettant de vous concentrer sur ce qui compte vraiment : les performances de votre IA.
Fonctionnalités clés :
⚡️ Accélérez les performances de service : Bénéficiez d'une augmentation de vitesse d'au moins 2x par rapport aux implémentations FastAPI standard, grâce à la gestion optimisée de LitServe multi-workers, spécialement conçue pour les charges de travail d'IA.
⚙️ Simplifiez le déploiement avec LitAPI et LitServer : Structurez votre code sans effort. LitAPI définit la manière dont votre modèle traite les requêtes, tandis que LitServer gère les complexités de la mise à l'échelle, du traitement par lots et du streaming, le tout sans nécessiter une expertise approfondie de l'infrastructure.
🤖 Déployez n'importe quel modèle, n'importe quel framework : Apportez votre propre modèle ! LitServe prend en charge un large éventail de frameworks, notamment PyTorch, JAX, TensorFlow, et bien d'autres. Il est conçu pour la polyvalence, gérant tout, des LLM aux modèles d'apprentissage automatique traditionnels.
🚀 Mettez à l'échelle sans effort grâce à la gestion automatique des GPU : LitServe met automatiquement à l'échelle votre modèle sur les GPU disponibles, maximisant ainsi l'utilisation des ressources. Il prend également en charge le traitement par lots et le streaming, améliorant encore les performances des applications d'IA générative.
☁️ Déployez n'importe où, avec un contrôle total : Choisissez votre environnement de déploiement. Exécutez LitServe sur votre propre infrastructure pour un contrôle complet, ou exploitez la plateforme gérée de Lightning AI pour une surveillance automatisée, une mise à l'échelle automatique et une tolérance aux pannes.
Cas d'utilisation :
Génération de texte à haut débit : Imaginez que vous avez développé un grand modèle de langage (LLM) personnalisé pour générer du contenu marketing. Avec LitServe, vous pouvez déployer ce modèle pour traiter des milliers de requêtes simultanées, assurant une génération rapide de contenu pour toute votre équipe marketing, sans vous soucier des goulots d'étranglement du serveur.
Traitement d'image en temps réel : Vous avez créé un modèle de vision par ordinateur pour analyser les images provenant des caméras de sécurité en temps réel. LitServe vous permet de déployer ce modèle sur des appareils périphériques ou dans le cloud, en traitant plusieurs flux vidéo simultanément et en fournissant des alertes instantanées pour les événements critiques. Tout cela est réalisé grâce à la prise en charge de plusieurs GPU et à un service optimisé.
Système d'IA composite pour le support client : Vous avez besoin d'un système qui transcrit d'abord les demandes vocales des clients (à l'aide d'un modèle de conversion parole-texte), puis analyse le sentiment et l'intention (à l'aide d'un modèle NLP), et enfin génère une réponse personnalisée (à l'aide d'un LLM). LitServe vous permet d'enchaîner ces modèles de manière transparente, créant ainsi une solution de support client puissante et efficace.
Conclusion :
LitServe vous permet de passer du développement de modèles au déploiement en production avec une vitesse et une efficacité sans précédent. Son architecture flexible, combinée à de puissantes capacités de mise à l'échelle et à la prise en charge de tout modèle d'IA, en fait la solution idéale pour les développeurs cherchant à apporter leurs innovations en matière d'IA au monde entier. Cessez de vous battre avec l'infrastructure et commencez à vous concentrer sur ce qui compte vraiment : votre IA.
FAQ :
Quelle est la différence entre LitServe et vLLM ?
LitServe opère à un niveau d'abstraction inférieur à celui des serveurs comme vLLM. Considérez LitServe comme un outil fondamental qui vous permet de construire votre propre solution de service spécialisée, comme un serveur vLLM personnalisé. vLLM est une solution pré-construite optimisée spécifiquement pour les LLM, tandis que LitServe offre une flexibilité plus large pour tout type de modèle d'IA.
Puis-je utiliser LitServe avec mes projets FastAPI existants ?
Oui, LitServe est construit sur FastAPI et est conçu pour être facilement intégré. Il augmente les fonctionnalités de FastAPI avec des fonctionnalités spécifiques à l'IA, améliorant ainsi ses performances et son évolutivité pour le service de modèles.
Quel niveau d'expertise technique est requis pour utiliser LitServe ?
LitServe est conçu pour les développeurs et les ingénieurs en IA qui sont à l'aise de travailler avec Python et qui connaissent un peu le déploiement de modèles d'apprentissage automatique. Les exemples de code et la documentation fournis facilitent la prise en main, même si vous n'êtes pas un expert en infrastructure d'apprentissage profond.
Quel type d'économies puis-je espérer avec LitServe ? LitServe possède des fonctionnalités, telles que la mise à l'échelle à zéro (sans serveur), les instances interruptibles, le traitement par lots et le streaming, qui peuvent réduire considérablement les coûts de service. Par exemple, avec 1 $, Llama 3.1 obtient 366 000 jetons, chatGPT 25 000 jetons. De plus, le modèle s'exécute sur votre cloud sécurisé, avec une capacité dédiée.
Quels sont les avantages de l'utilisation de LitServe sur la plateforme Lightning AI ?
Le déploiement sur Lightning AI offre des avantages supplémentaires, notamment une surveillance automatisée, une mise à l'échelle automatique (de zéro à des milliers de GPU), une tolérance aux pannes et une gestion simplifiée. Il simplifie le processus de déploiement et offre des fonctionnalités de niveau entreprise.
More information on LitServe
Launched
2017-12
Pricing Model
Free
Starting Price
Global Rank
89547
Follow
Month Visit
464.6K
Tech used
Google Tag Manager,Cloudflare CDN,Google Fonts,Gzip,JSON Schema,OpenGraph,Progressive Web App,HSTS
Top 5 Countries
19.19%
8.05%
6.32%
3.97%
3.62%
United States
India
Germany
Vietnam
Kazakhstan
Traffic Sources
2.26%
0.62%
0.09%
7.48%
48.35%
41.21%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 25, 2025)
LitServe was manually vetted by our editorial team and was first featured on 2025-03-10.
LitServe Alternatives
Plus Alternatives-

-
-

Literal AI : Observabilité et évaluation pour RAG et LLMs. Débuggez, surveillez et optimisez les performances, tout en garantissant que vos applications d'IA sont prêtes pour la production.
-

OpenLIT est un outil d'observabilité LLM et GPU open source basé sur OpenTelemetry. Il offre le traçage, les métriques et un terrain de jeu pour déboguer et améliorer les applications LLM. Il prend en charge plus de 20 intégrations, telles que OpenAI, LangChain, et exporte des données vers vos outils d'observabilité existants.
-