What is LitServe?
您是AI开发人员或工程师吗?是否花费了大量时间与基础设施搏斗,而不是专注于模型创新?LitServe 是一款灵活易用的 Serving 引擎,旨在简化任何 AI模型的部署,无论其大小或框架如何。LitServe 基于流行的 FastAPI 框架构建,消除了扩展、批处理和 GPU 管理的复杂性,让您专注于真正重要的事情:AI 的性能。
主要特点:
⚡️ 加速 Serving 性能: 借助 LitServe 针对 AI 工作负载优化的多工作进程处理,体验比标准 FastAPI 实现至少快 2 倍的速度提升。
⚙️ 使用 LitAPI 和 LitServer 简化部署: 轻松构建您的代码。LitAPI 定义了您的模型如何处理请求,而 LitServer 管理扩展、批处理和流式传输的复杂性,所有这些都不需要深入的基础设施专业知识。
🤖 部署任何模型,任何框架: 自带模型!LitServe 支持各种框架,包括 PyTorch、JAX、TensorFlow 等。它专为通用性而设计,可以处理从 LLM 到传统机器学习模型的各种任务。
🚀 通过自动 GPU 管理轻松扩展: LitServe 自动在可用 GPU 上扩展您的模型,从而最大限度地提高资源利用率。它还支持批处理和流式传输,进一步增强生成式 AI 应用程序的性能。
☁️ 随处部署,完全掌控: 选择您的部署环境。在您自己的基础设施上运行 LitServe 以实现完全控制,或者利用 Lightning AI 的托管平台进行自动监控、自动扩展和容错。
使用案例:
高吞吐量文本生成: 想象一下,您开发了一个自定义的大型语言模型 (LLM) 来生成营销文案。使用 LitServe,您可以部署此模型来处理数千个并发请求,确保为您的整个营销团队快速生成内容,而无需担心服务器瓶颈。
实时图像处理: 您构建了一个计算机视觉模型来实时分析来自安全摄像头的图像。LitServe 使您能够在边缘设备或云端部署此模型,同时处理多个视频流,并为关键事件提供即时警报。所有这些都是在多 GPU 支持和优化 Serving 的帮助下实现的。
用于客户支持的复合 AI 系统: 您需要一个系统,该系统首先转录客户语音查询(使用语音转文本模型),然后分析情绪和意图(使用 NLP 模型),最后生成个性化响应(使用 LLM)。LitServe 允许您无缝地将这些模型链接在一起,从而创建一个强大而高效的客户支持解决方案。
结论:
LitServe 使您能够以前所未有的速度和效率从模型开发过渡到生产部署。其灵活的架构,结合强大的扩展能力和对任何 AI 模型(包括 LLM)的支持,使其成为开发人员寻求将其 AI 创新带给世界的理想解决方案。停止与基础设施作斗争,开始专注于真正重要的事情——您的 AI。
FAQ:
LitServe 和 vLLM 有什么区别?
LitServe 在比 vLLM 等服务器更低的抽象级别上运行。可以将 LitServe 视为一种基础工具,可让您构建自己的专用 Serving 解决方案,例如自定义 vLLM 服务器。vLLM 是一种专门为 LLM 优化的预构建解决方案,而 LitServe 为任何类型的 AI 模型提供更广泛的灵活性。
我可以在现有的 FastAPI 项目中使用 LitServe 吗?
是的,LitServe 基于 FastAPI 构建,旨在易于集成。它使用 AI 特定的功能增强了 FastAPI,从而提高了其模型 Serving 的性能和可扩展性。
使用 LitServe 需要什么级别的技术专业知识?
LitServe 专为熟悉使用 Python 且对部署机器学习模型有一定了解的 AI 开发人员和工程师而设计。即使您不是深度学习基础设施专家,提供的代码示例和文档也能让您轻松入门。
使用 LitServe 可以期望节省多少成本? LitServe 具有诸如 scale-to-zero(无服务器)、可中断实例、批处理和流式传输等功能,可以大大降低 Serving 成本。例如,使用 1 美元,Llama 3.1 获得 366k 个 token,chatGPT 25K 个 token。此外,该模型在您安全的云上运行,具有专用容量。
在 Lightning AI 平台上使用 LitServe 有什么好处?
在 Lightning AI 上部署可提供更多好处,包括自动监控、自动扩展(从零到数千个 GPU)、容错和简化管理。它简化了部署过程并提供企业级功能。
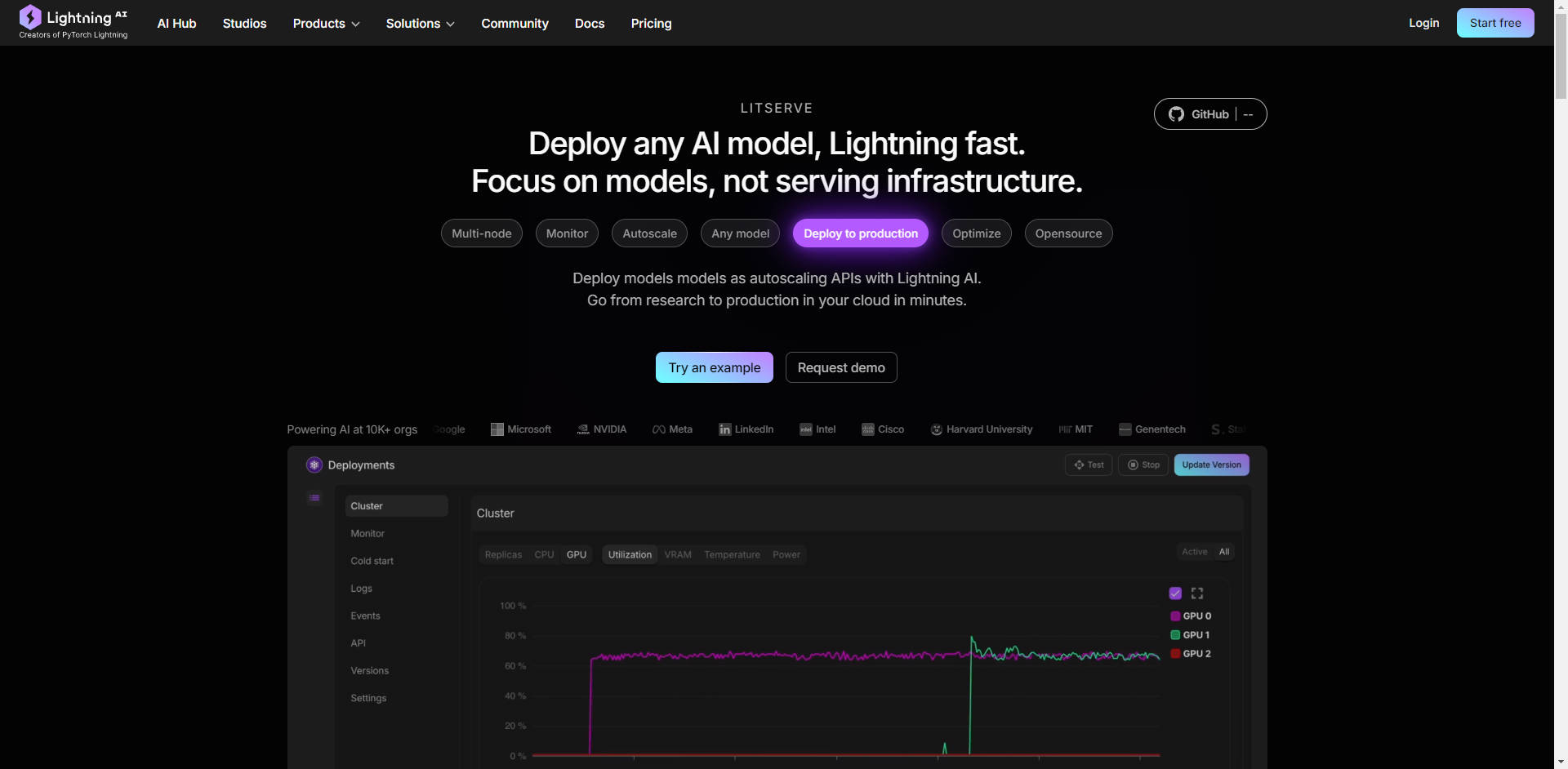
More information on LitServe
Launched
2017-12
Pricing Model
Free
Starting Price
Global Rank
89547
Follow
Month Visit
464.6K
Tech used
Google Tag Manager,Cloudflare CDN,Google Fonts,Gzip,JSON Schema,OpenGraph,Progressive Web App,HSTS
Top 5 Countries
19.19%
8.05%
6.32%
3.97%
3.62%
United States
India
Germany
Vietnam
Kazakhstan
Traffic Sources
2.26%
0.62%
0.09%
7.48%
48.35%
41.21%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 25, 2025)
LitServe was manually vetted by our editorial team and was first featured on 2025-03-10.