
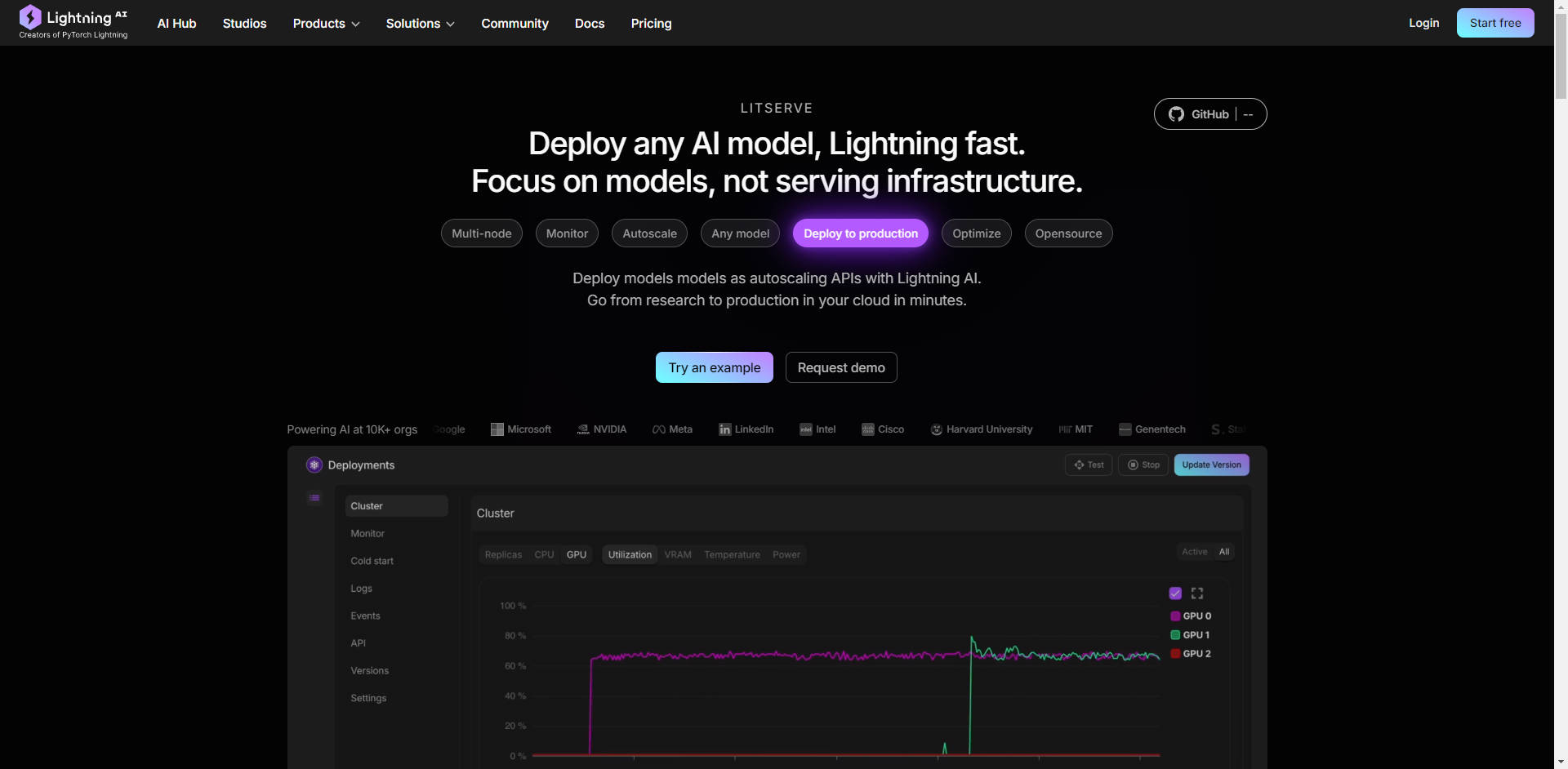
Click outside to close
What is LitServe?
Are you an AI developer or engineer spending more time wrestling with infrastructure than innovating with your models? LitServe is a flexible and easy-to-use serving engine designed to streamline the deployment of any AI model, regardless of size or framework. Built on the popular FastAPI framework, LitServe eliminates the complexities of scaling, batching, and GPU management, letting you focus on what truly matters: your AI's performance.
Key Features:
⚡️ Accelerate Serving Performance: Experience at least a 2x speed increase compared to standard FastAPI implementations, thanks to LitServe's optimized multi-worker handling, specifically designed for AI workloads.
⚙️ Simplify Deployment with LitAPI and LitServer: Structure your code effortlessly. LitAPI defines how your model handles requests, while LitServer manages the complexities of scaling, batching, and streaming, all without requiring deep infrastructure expertise.
🤖 Deploy Any Model, Any Framework: Bring your own model! LitServe supports a wide range of frameworks, including PyTorch, JAX, TensorFlow, and more. It's designed for versatility, handling everything from LLMs to traditional machine learning models.
🚀 Scale Effortlessly with Automatic GPU Management: LitServe automatically scales your model across available GPUs, maximizing resource utilization. It also supports batching and streaming, further enhancing performance for generative AI applications.
☁️ Deploy Anywhere, with Full Control: Choose your deployment environment. Run LitServe on your own infrastructure for complete control, or leverage Lightning AI's managed platform for automated monitoring, autoscaling, and fault tolerance.
Use Cases:
High-Throughput Text Generation: Imagine you've developed a custom large language model (LLM) for generating marketing copy. With LitServe, you can deploy this model to handle thousands of concurrent requests, ensuring rapid content generation for your entire marketing team, without worrying about server bottlenecks.
Real-Time Image Processing: You've built a computer vision model to analyze images from security cameras in real-time. LitServe enables you to deploy this model on edge devices or in the cloud, processing multiple video streams simultaneously and providing instant alerts for critical events. This is all achieved with the help of multi-GPU support and optimized serving.
Compound AI System for Customer Support: You need a system that first transcribes customer voice inquiries (using a speech-to-text model), then analyzes the sentiment and intent (using an NLP model), and finally generates a personalized response (using an LLM). LitServe allows you to chain these models together seamlessly, creating a powerful and efficient customer support solution.
Conclusion:
LitServe empowers you to move from model development to production deployment with unprecedented speed and efficiency. Its flexible architecture, combined with powerful scaling capabilities and support for any AI model, makes it the ideal solution for developers seeking to bring their AI innovations to the world. Stop battling infrastructure and start focusing on what truly matters – your AI.
FAQ:
What is the difference between LitServe and vLLM?
LitServe operates at a lower level of abstraction than servers like vLLM. Think of LitServe as a foundational tool that allows you to build your own specialized serving solution, like a custom vLLM server. vLLM is a pre-built solution optimized specifically for LLMs, while LitServe offers broader flexibility for any type of AI model.
Can I use LitServe with my existing FastAPI projects?
Yes, LitServe is built on FastAPI and is designed to be easily integrated. It augments FastAPI with AI-specific features, enhancing its performance and scalability for model serving.
What level of technical expertise is required to use LitServe?
LitServe is designed for AI developers and engineers who are comfortable working with Python and have some familiarity with deploying machine learning models. The provided code examples and documentation make it easy to get started, even if you're not a deep learning infrastructure expert.
What kind of cost savings can I expect with LitServe? LitServe has features, such as scale-to-zero (serverless), interruptible instances, batching, and streaming, that can reduce serving costs drastically. For an example, with $1, Llama 3.1 gets 366k tokens, chatGPT 25K tokens. Plus, the model runs on your secure cloud, with dedicated capacity.
What are the benefits of using LitServe on the Lightning AI platform?
Deploying on Lightning AI provides additional benefits, including automated monitoring, autoscaling (from zero to thousands of GPUs), fault tolerance, and simplified management. It streamlines the deployment process and offers enterprise-grade features.
More information on LitServe
Launched
2017-12
Pricing Model
Free
Starting Price
Global Rank
105197
Follow
Month Visit
363.5K
Tech used
Top 5 Countries
20.38%
11.61%
5.25%
4.9%
4.84%
United States (20.38%)
India (11.61%)
China (5.25%)
Vietnam (4.9%)
Germany (4.84%)
Traffic Sources
43.55%
45.95%
7.61%
mail (0.09%)
direct (43.55%)
search (45.95%)
social (2.06%)
referrals (7.61%)
paidReferrals (0.74%)
Source: Similarweb (Jan 4, 2026)
LitServe was manually vetted by our editorial team and was first featured on 2025-03-10.
LitServe Alternatives
LitServe Alternatives-

Call all LLM APIs using the OpenAI format. Use Bedrock, Azure, OpenAI, Cohere, Anthropic, Ollama, Sagemaker, HuggingFace, Replicate (100+ LLMs)
-
Build AI products lightning fast! All-in-one platform offers GPU access, zero setup, and tools for training & deployment. Prototype 8x faster. Trusted by top teams.
-

Literal AI: Observability & Evaluation for RAG & LLMs. Debug, monitor, optimize performance & ensure production-ready AI apps.
-

OpenLIT is an open-source LLM and GPU observability tool built on OpenTelemetry. It offers tracing, metrics, and a playground to debug and improve LLM apps. Supports 20+ integrations like OpenAI, LangChain, and exports data to your existing observability tools
-
Ship AI features faster with MegaLLM's unified gateway. Access Claude, GPT-5, Gemini, Llama, and 70+ models through a single API. Built-in analytics, smart fallbacks, and usage tracking included.