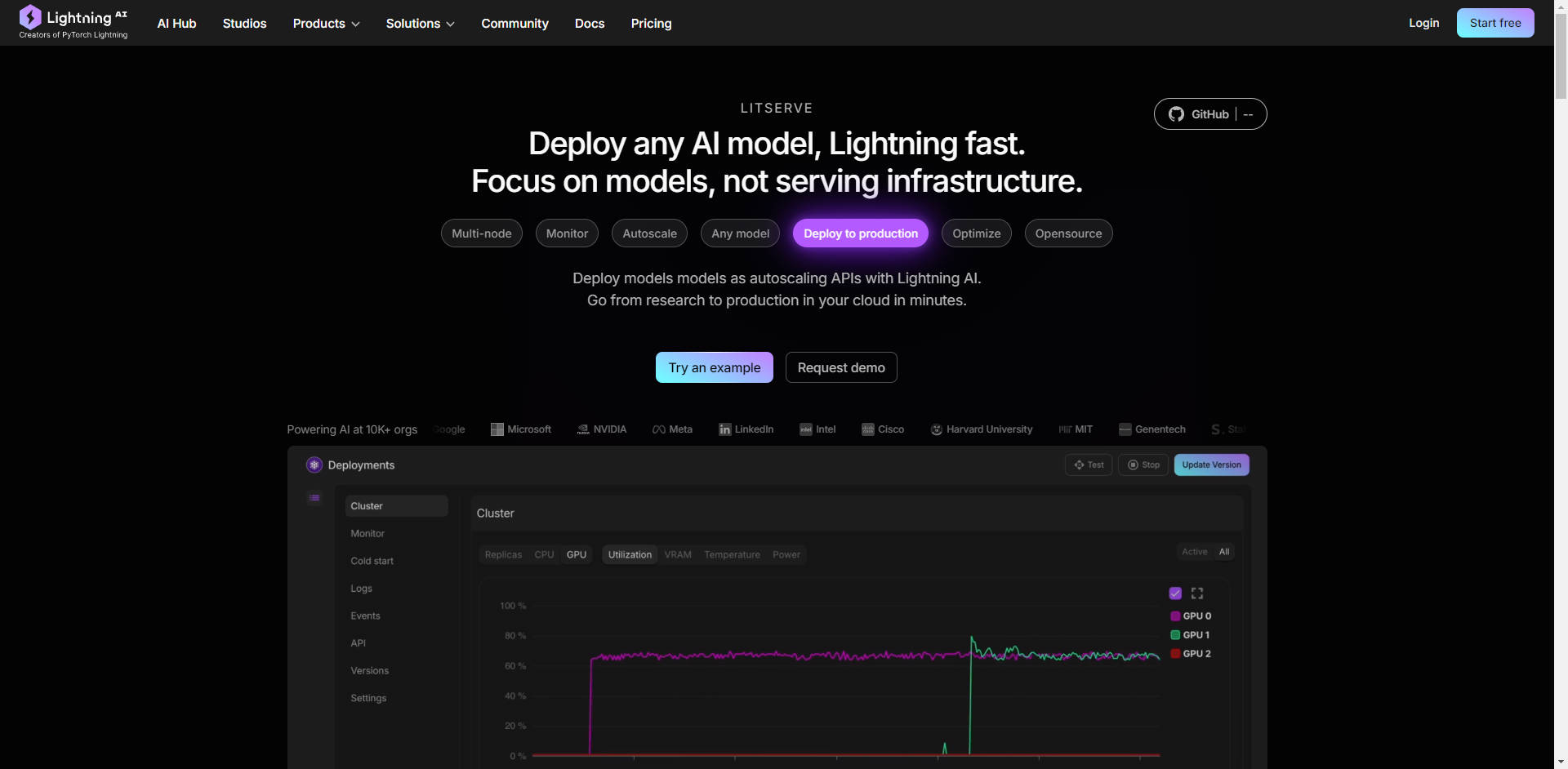
What is LitServe?
AI開発者やエンジニアの皆様、モデルの革新よりもインフラの扱いに時間を費やしていませんか? LitServe は、規模やフレームワークに関わらず、あらゆる AIモデルのデプロイを効率化するために設計された、柔軟で使いやすいサービングエンジンです。人気のFastAPIフレームワーク上に構築された LitServe は、スケーリング、バッチ処理、GPU管理の複雑さを解消し、AIのパフォーマンスという本質に集中することを可能にします。
主な機能:
⚡️ サービングパフォーマンスの加速: LitServe の最適化されたマルチワーカー処理(特にAIワークロード向けに設計)により、標準的なFastAPI実装と比較して少なくとも2倍の速度向上を体験できます。
⚙️ LitAPI と LitServer によるデプロイの簡素化: コードを簡単に構成できます。LitAPI はモデルがリクエストをどのように処理するかを定義し、LitServer はスケーリング、バッチ処理、ストリーミングの複雑さを管理します。これらすべてに、深いインフラストラクチャの専門知識は必要ありません。
🤖 あらゆるモデル、あらゆるフレームワークをデプロイ: 独自のモデルを持ち込みましょう! LitServe は、PyTorch、JAX、TensorFlowなど、幅広いフレームワークをサポートしています。LLMから従来の機械学習モデルまで、あらゆるものを処理できる汎用性を備えています。
🚀 自動GPU管理による容易なスケーリング: LitServe は、利用可能なGPU全体にモデルを自動的にスケーリングし、リソースの使用率を最大化します。また、バッチ処理とストリーミングもサポートしており、生成AIアプリケーションのパフォーマンスをさらに向上させます。
☁️ 完全な制御による、あらゆる場所へのデプロイ: デプロイ環境を選択してください。LitServe を独自のインフラストラクチャ上で実行して完全な制御を実現することも、Lightning AI のマネージドプラットフォームを活用して、自動監視、自動スケーリング、フォールトトレランスを実現することもできます。
ユースケース:
高スループットのテキスト生成: マーケティングコピーを生成するためのカスタム大規模言語モデル(LLM)を開発したとします。LitServe を使用すると、このモデルをデプロイして数千もの同時リクエストを処理し、サーバーのボトルネックを気にすることなく、マーケティングチーム全体の迅速なコンテンツ生成を保証できます。
リアルタイム画像処理: セキュリティカメラからの画像をリアルタイムで分析するためのコンピュータビジョンモデルを構築したとします。LitServe を使用すると、このモデルをエッジデバイスまたはクラウドにデプロイし、複数のビデオストリームを同時に処理して、重大なイベントに関する即時アラートを提供できます。これはすべて、マルチGPUサポートと最適化されたサービングによって実現されます。
顧客サポートのための複合AIシステム: まず、顧客の音声問い合わせを文字に起こし(音声テキスト変換モデルを使用)、次に感情と意図を分析し(NLPモデルを使用)、最後にパーソナライズされた応答を生成する(LLMを使用)システムが必要だとします。LitServe を使用すると、これらのモデルをシームレスに連結して、強力で効率的な顧客サポートソリューションを作成できます。
結論:
LitServe は、モデル開発から本番環境へのデプロイを、これまでにないスピードと効率で実現します。柔軟なアーキテクチャと、強力なスケーリング機能、あらゆるAIモデルのサポートを組み合わせることで、AIイノベーションを世界に届けたいと願う開発者にとって理想的なソリューションとなります。インフラとの戦いをやめて、本当に重要なこと、つまりAIに集中しましょう。
FAQ:
LitServe と vLLM の違いは何ですか?
LitServe は、vLLMなどのサーバーよりも低い抽象度で動作します。LitServe は、カスタムvLLMサーバーなど、独自の特殊なサービングソリューションを構築できる基盤ツールと考えてください。vLLM はLLMに特化して最適化された既製のソリューションですが、LitServe はあらゆるタイプのAIモデルに対してより幅広い柔軟性を提供します。
既存のFastAPIプロジェクトで LitServe を使用できますか?
はい、LitServe は FastAPI 上に構築されており、簡単に統合できるように設計されています。AIに特化した機能で FastAPI を拡張し、モデルサービングのパフォーマンスとスケーラビリティを向上させます。
LitServe の使用に必要な技術的な専門知識のレベルは?
LitServe は、Python の操作に慣れており、機械学習モデルのデプロイに多少の知識があるAI開発者およびエンジニア向けに設計されています。提供されているコード例とドキュメントを使用すれば、深層学習インフラストラクチャの専門家でなくても簡単に始めることができます。
LitServe で期待できるコスト削減額は? LitServe には、スケール・トゥ・ゼロ(サーバーレス)、中断可能なインスタンス、バッチ処理、ストリーミングなどの機能があり、サービングコストを大幅に削減できます。例として、1ドルで Llama 3.1 は 366,000トークン、chatGPT は 25,000トークンを取得できます。さらに、モデルは専用容量を備えた安全なクラウドで実行されます。
Lightning AI プラットフォームで LitServe を使用する利点は何ですか?
Lightning AI にデプロイすると、自動監視、自動スケーリング(ゼロから数千のGPUまで)、フォールトトレランス、および簡素化された管理など、追加のメリットが得られます。デプロイプロセスが効率化され、エンタープライズグレードの機能が提供されます。
More information on LitServe
Launched
2017-12
Pricing Model
Free
Starting Price
Global Rank
89547
Follow
Month Visit
464.6K
Tech used
Google Tag Manager,Cloudflare CDN,Google Fonts,Gzip,JSON Schema,OpenGraph,Progressive Web App,HSTS
Top 5 Countries
19.19%
8.05%
6.32%
3.97%
3.62%
United States
India
Germany
Vietnam
Kazakhstan
Traffic Sources
2.26%
0.62%
0.09%
7.48%
48.35%
41.21%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 25, 2025)
LitServe was manually vetted by our editorial team and was first featured on 2025-03-10.
LitServe 代替ソフト
もっと見る 代替ソフト-

-
-

Literal AI:RAGとLLMの可観測性と評価。デバッグ、監視、パフォーマンスの最適化を行い、本番環境に対応できるAIアプリケーションを確実に実現します。
-

-