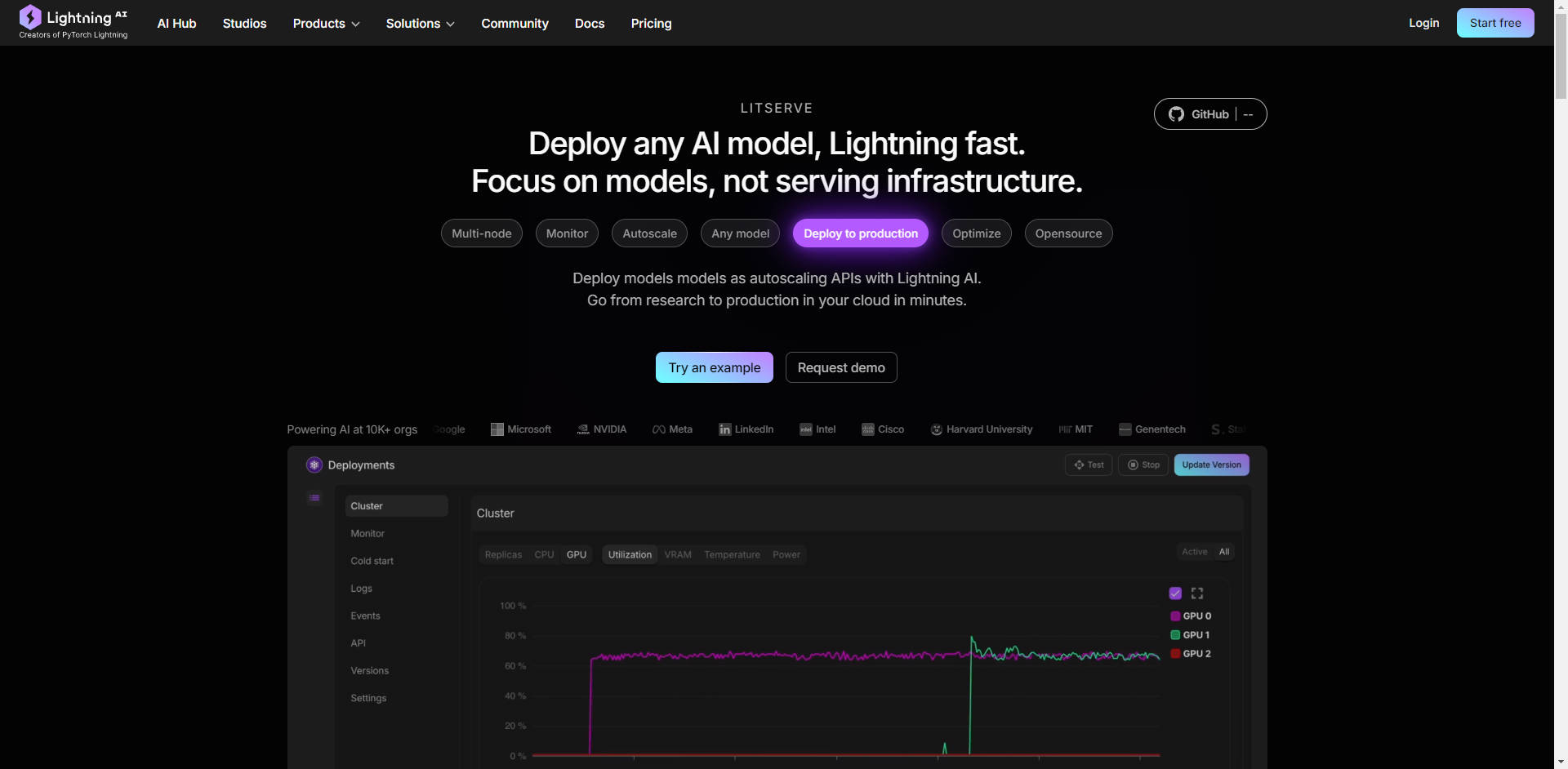
What is LitServe?
Вы AI-разработчик или инженер, который тратит больше времени на борьбу с инфраструктурой, чем на инновации в своих моделях? LitServe – это гибкий и простой в использовании движок для обслуживания, разработанный для оптимизации развертывания любой AI-модели, независимо от размера или фреймворка. Основанный на популярном фреймворке FastAPI, LitServe устраняет сложности масштабирования, пакетирования и управления GPU, позволяя вам сосредоточиться на том, что действительно важно: производительности вашего AI.
Ключевые особенности:
⚡️ Ускорение производительности обслуживания: Оцените как минимум двукратное увеличение скорости по сравнению со стандартными реализациями FastAPI благодаря оптимизированной обработке нескольких рабочих процессов в LitServe, специально разработанной для AI-задач.
⚙️ Упрощение развертывания с помощью LitAPI и LitServer: Структурируйте свой код без усилий. LitAPI определяет, как ваша модель обрабатывает запросы, а LitServer управляет сложностями масштабирования, пакетирования и потоковой передачи, и все это без необходимости глубоких знаний в области инфраструктуры.
🤖 Развертывание любой модели, любого фреймворка: Принесите свою собственную модель! LitServe поддерживает широкий спектр фреймворков, включая PyTorch, JAX, TensorFlow и другие. Он разработан для универсальности, обрабатывая все, от LLM до традиционных моделей машинного обучения.
🚀 Легкое масштабирование с автоматическим управлением GPU: LitServe автоматически масштабирует вашу модель на доступных GPU, максимально увеличивая использование ресурсов. Он также поддерживает пакетирование и потоковую передачу, что еще больше повышает производительность для приложений генеративного AI.
☁️ Развертывание где угодно, с полным контролем: Выберите среду развертывания. Запустите LitServe на собственной инфраструктуре для полного контроля или используйте управляемую платформу Lightning AI для автоматизированного мониторинга, автомасштабирования и отказоустойчивости.
Примеры использования:
Генерация текста с высокой пропускной способностью: Представьте, что вы разработали собственную большую языковую модель (LLM) для создания маркетинговых текстов. С помощью LitServe вы можете развернуть эту модель для обработки тысяч одновременных запросов, обеспечивая быструю генерацию контента для всей вашей маркетинговой команды, не беспокоясь об узких местах сервера.
Обработка изображений в реальном времени: Вы создали модель компьютерного зрения для анализа изображений с камер видеонаблюдения в реальном времени. LitServe позволяет развернуть эту модель на периферийных устройствах или в облаке, обрабатывая несколько видеопотоков одновременно и предоставляя мгновенные оповещения о критических событиях. Все это достигается с помощью поддержки нескольких GPU и оптимизированного обслуживания.
Составная AI-система для поддержки клиентов: Вам нужна система, которая сначала транскрибирует голосовые запросы клиентов (с помощью модели преобразования речи в текст), затем анализирует настроение и намерения (с помощью модели NLP) и, наконец, генерирует персонализированный ответ (с помощью LLM). LitServe позволяет объединять эти модели вместе, создавая мощное и эффективное решение для поддержки клиентов.
Заключение:
LitServe позволяет вам перейти от разработки модели к производственному развертыванию с беспрецедентной скоростью и эффективностью. Его гибкая архитектура в сочетании с мощными возможностями масштабирования и поддержкой любой AI-модели делает его идеальным решением для разработчиков, стремящихся представить свои AI-инновации миру. Хватит бороться с инфраструктурой, начните фокусироваться на том, что действительно важно – на вашем AI.
FAQ:
В чем разница между LitServe и vLLM?
LitServe работает на более низком уровне абстракции, чем такие серверы, как vLLM. Думайте о LitServe как о фундаментальном инструменте, который позволяет вам создать свое собственное специализированное решение для обслуживания, например, собственный сервер vLLM. vLLM – это готовое решение, оптимизированное специально для LLM, в то время как LitServe предлагает более широкую гибкость для любого типа AI-модели.
Могу ли я использовать LitServe с моими существующими проектами FastAPI?
Да, LitServe построен на FastAPI и разработан для легкой интеграции. Он расширяет FastAPI функциями, специфичными для AI, улучшая его производительность и масштабируемость для обслуживания моделей.
Какой уровень технических знаний требуется для использования LitServe?
LitServe предназначен для AI-разработчиков и инженеров, которые комфортно работают с Python и имеют некоторое представление о развертывании моделей машинного обучения. Предоставленные примеры кода и документация позволяют легко начать работу, даже если вы не являетесь экспертом в области инфраструктуры глубокого обучения.
Какую экономию средств я могу ожидать с LitServe? LitServe имеет такие функции, как scale-to-zero (serverless), прерываемые экземпляры, пакетирование и потоковая передача, которые могут значительно снизить затраты на обслуживание. Например, за 1 доллар Llama 3.1 получает 366 тысяч токенов, а chatGPT – 25 тысяч токенов. Кроме того, модель работает в вашем безопасном облаке, с выделенной емкостью.
Каковы преимущества использования LitServe на платформе Lightning AI?
Развертывание на Lightning AI предоставляет дополнительные преимущества, включая автоматизированный мониторинг, автомасштабирование (от нуля до тысяч GPU), отказоустойчивость и упрощенное управление. Это упрощает процесс развертывания и предлагает функции корпоративного уровня.
More information on LitServe
Launched
2017-12
Pricing Model
Free
Starting Price
Global Rank
89547
Follow
Month Visit
464.6K
Tech used
Google Tag Manager,Cloudflare CDN,Google Fonts,Gzip,JSON Schema,OpenGraph,Progressive Web App,HSTS
Top 5 Countries
19.19%
8.05%
6.32%
3.97%
3.62%
United States
India
Germany
Vietnam
Kazakhstan
Traffic Sources
2.26%
0.62%
0.09%
7.48%
48.35%
41.21%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 25, 2025)
LitServe was manually vetted by our editorial team and was first featured on 2025-03-10.
LitServe Альтернативи
Больше Альтернативи-

-
-

Literal AI: Наблюдаемость и оценка для RAG и LLM. Отладка, мониторинг, оптимизация производительности и обеспечение готовности к эксплуатации приложений AI.
-

OpenLIT - это инструмент наблюдения за LLM и GPU с открытым исходным кодом, построенный на OpenTelemetry. Он предлагает трассировку, метрики и площадку для отладки и улучшения приложений LLM. Поддерживает более 20 интеграций, таких как OpenAI, LangChain, и экспортирует данные в ваши существующие инструменты наблюдения.
-